为什么需要线程池
new Thread()不是创建一个对象那么简单,需要调用操作系统内核的API,然后操作系统要为线程分配一系列的资源,这个成本就很高。所以线程是一个重量级的对象,应该避免频繁创建和销毁。而应对方案就是线程池。
定义
线程池,除了池的功能外,还提供了更全面的线程管理、任务提交等方法。带来的好处是:
- 降低资源消耗
- 提高任务响应速度
- 提高线程可管理性
ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- workQueue,工作队列负责存储用户提交的各个任务,下面会详细介绍。
- corePoolSize,核心线程数,可以理解为长期驻留的线程数目(除非设置了allowCoreThreadTimeOut)。对于不同的线程池,这个值可能会有很大区别,比如newFixedThreadPool会将其设置为nThreads,而对于newCachedThreadPool则是为0。
- maximumPoolSize,线程不够时能够创建的最大线程数。对于newFixedThreadPool,就是nThreads,因为其要求是固定大小,而newCachedThreadPool则是Integer.MAX_VALUE 。
- keepAliveTime和TimeUnit,这两个参数指定了额外的线程能够闲置多久,显然有些线程池不需要它。
- threadFactory,自定义如何创建线程,例如你可以给线程指定一个有意义的名字。
- handler,自定义任务的拒绝策略。
- 内部的“线程池”,是保存工作线程的集合,线程池需要在运行过程中管理线程创建、销毁。线程池的工作线程被抽象为静态内部类Worker,基于AQS实现。
private final HashSet<Worker> workers = new HashSet<>();
- ctl变量是一个非常有意思的设计,它被赋予了双重角色,通过高低位的不同,既表示线程池状态,又表示工作线程数目,这是一个典型的高效优化。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 真正决定了工作线程数的理论上限
private static fnal int COUNT_BITS = Integer.SIZE - 3;
private static fnal int COUNT_MASK = (1 << COUNT_BITS) - 1;
// 线程池状态,存储在数字的高位
private static fnal int RUNNING = -1 << COUNT_BITS;
…
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
private static int workerCountOf(int c) { return c & COUNT_MASK; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
工作队列workQueue
即各种BlockingQueue
- 直接提交队列。synchronousQueue,是特殊的BlockingQueue, 容量为0,没执行一个插入就会阻塞,需要执行删除才能唤醒。
- 有界队列。ArrayBlockingQueue,来了新任务时,pool创建工作线程,直到线程数达到corePoolSize,此时将任务加入有界队列。如果队列满了,则继续创建线程,直到maximimPoolSize,此时执行拒绝策略。
- 无界队列。LinkBlockingQueue,无界,注意OOM问题,提倡使用有界队列。
不同的线程池
JUC的Executors目前提供了5种不同的线程池
-
newFixedThreadPooll(int nThreads)创建一个指定工作线程数量的线程池。
coolPoolSize = maximumPoolSize = nThreads
使用的是无界的工作队列LinkBlockingQueue,每提交一个任务就创建一个工作线程,如果工作线程数量达到coolPoolSize,则将提交的任务存入到队列中等待。
maximumPoolSize和keepAliveTime无效。 -
newCachedThreadPooll()创建一个可缓存的线程池,用来处理大量短时间工作任务的线程池。特点是:
- 它会试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程。工作线程的创建数量有限制为Interger. MAX_VALUE。
- 如果工作线程空闲超过1分钟,将自动终止并移出缓存。长时间闲置时,这种线程池,不会消耗什么资源。
- 其内部使用SynchronousQueue作为工作队列
-
newSingleThreadExecutor()创建一个单线程化的Executor。
只创建唯一的工作者线程,如果这个线程异常结束会有另一个取代它。单工作线程最大的特点是可保证顺序地执行各个任务,并且在任意给定的时间只有一个线程在工作。 -
newSingleThreadScheduledExecutor()和newScheduledThreadPool(int corePoolSize)。
创建的是个ScheduledExecutorService,可以进行定时或周期性的工作调度,区别在于单一工作线程还是多个工作线程。 -
newWorkStealingPool(int parallelism),JDK1.8引入。
内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序。
work-stealing pool的实现
Executor
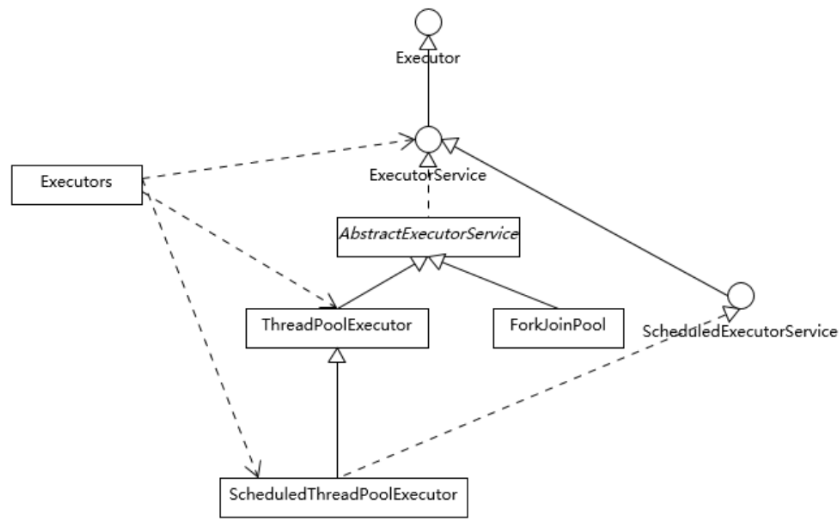
Executor是一个基础的接口,其初衷是将任务提交和任务执行细节解耦,使开发者不被太多线程创建、调度等不相关细节所打扰。
void execute(Runnable command);
ExecutorService则更加完善,不仅提供service的管理功能,比如shutdown等方法,也提供了更加全面的提交任务机制,如返回Future而不是void的submit方法。
<T> Future<T> submit(Callable<T> task);
线程池的工作原理
线程池是一种生产者-消费者模式,而不是经典池化资源的获取/释放模式。
为什么线程池没有采用一般意义上池化资源的设计方法呢?因为找不到似execute(Runnable target)这种方法执行业务逻辑。
//采⽤⼀般意义上池化资源的设计⽅法
class ThreadPool{
// 获取空闲线程
Thread acquire() {
}
// 释放线程
void release(Thread t){
}
}
//期望的使⽤
ThreadPool pool;
Thread T1=pool.acquire();
//传⼊Runnable对象
T1.execute(()->{
//具体业务逻辑
......
});
所以,采用了生产者消费者模式,线程池的使用方是生产者,线程池本身是消费者,产品则是业务任务work,work被放入工作队列workQueue。
可以把线程池类比为一个项目组,而线程就是项目组的成员。
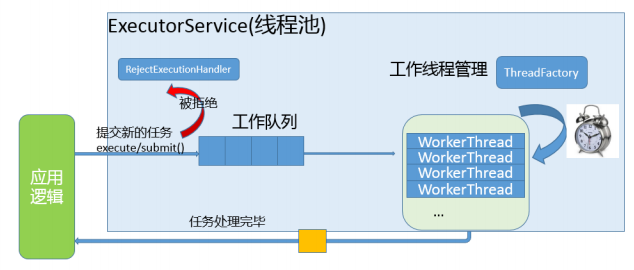
线程池生命周期
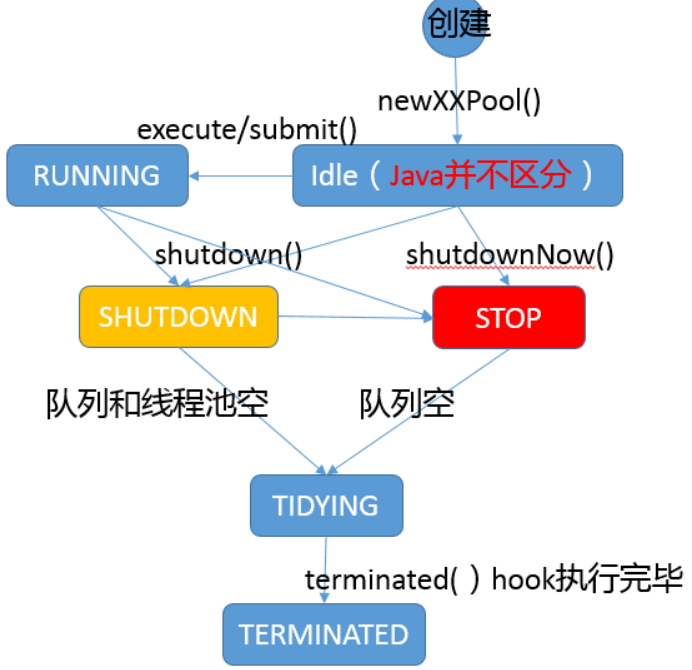
线程池增长策略
任务通过execute(Runable)添加到pool
public void execute(Runnable command) {
…
int c = ctl.get();
// 检查工作线程数目,低于corePoolSize则添加Worker
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// isRunning就是检查线程池是否被shutdown
// 工作队列可能是有界的,ofer是比较友好的入队方式
if (isRunning(c) && workQueue.ofer(command)) {
int recheck = ctl.get();
// 再次进行防御性检查
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 尝试添加一个worker,如果失败以为着已经饱和或者被shutdown了
else if (!addWorker(command, false))
reject(command);
}
线程池大小的设置
如果我们的任务主要是进行计算,通常建议按照CPU核的数目N或者N+1。
如果是需要较多等待的任务,例如I/O操作比较多,可以参考Brain Goetz推荐的计算方法:线程数 = CPU核数 × (1 + 平均等待时间/平均工作时间)
线程池使用的注意事项
- 避免任务堆积。工作队列是无界的,如果工作线程数目太少,导致处理跟不上入队的速度,这就很有可能占用大量系统内存,甚至是出现OOM。
- 避免过度扩展线程。通常在处理大量短时任务时,使用可缓存的线程池,但很难明确设置线程数目。
- 避免线程泄漏。往往是因为任务逻辑有问题,导致工作线程迟迟不能被释放,当线程数目不断增长时造成溢出。
- 避免死锁
- 避免在使用线程池时操作ThreadLocal。因为ThreadLocalMap中废弃项目的回收依赖于显式地触发,否则就要等待线程结束,内存自动回收弱引用,进而回收相应ThreadLocalMap,但worker线程往往是不会退出的,这就容易出现OOM。
- Executors提供的很多方法默认使用的都是无界的LinkedBlockingQueue,高负载情境下,无界队列很容易导致OOM,而OOM会导致所有请求都无法处理,所以建议使用有界队列
参考
《Java并发实战》
《Java核心技术36讲》杨晓峰