整型 int
按照长度分:int8 int16 int32 int64
无符号整型: unit8 unit16 unit32 unit64
unit8就是我们说的byte型
int16对应的C语言中的short型,
int64对应C语言中的long型
可以跨平台的编程语言可以运行在多种平台上,平台的字节长度是有差异的,64位较为普及,但是8 16 32位操作系统依然存在,16位的平台上依然可以使用64位的变量,但是性能和内存性能上较差,同理在64位上使用8位、16位于平台位数不等长的变量,编译器也是尽量将内存对齐以获得最好的性能,这种不能正确匹配平台字节长度的程序类似于用轿车拉牛和用卡车拉牛一个道理
浮点型 float
float32 float64
这两中浮点型遵循IEEE754标准
float32 3.4e38,可以使用常量定义 math.MaxFloat32
float32 1.8e308,可以使用常量定义 math.MaxFloat64
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("%f
",math.Pi)
//3.141593
fmt.Printf("%.2f
",math.Pi)
//可以指定精度 .2表示保留2位
//3.14
}
布尔型 bool
package main
import "fmt"
func main() {
var n bool
fmt.Println(int(n) * 2)
//cannot convert n (type bool) to type int
//布尔型无法参与数值计算也无法与其他类型进行转换
}
字符串 string
字符串在go中以原生数据类型出现,
go中的字符串内部实现使用了utf-8编码,通过rune类型,可以方便的对每个utf-8类型进行访问,当然,也支持ascii码进行逐字符访问
package main
import "fmt"
func main() {
//字符串的值以双引号写 ""
var str string = "123"
//多行字符串需要使用反引号 ``
const str1 = `
多行字符串
多行字符串
多行字符串
多行字符串
`
fmt.Println(str)
//在``之间的所有代码均不会被解释器解释。只是作为字符串的一部分
}
常见的转义符

字符
字符串中的每一元素都叫做 字符, 在遍历字符串获得元素的时候获得的就是字符
go中字符有两种
- uint8 类型,就是byte型,代表了ASCII码的一个字符
- rune类型,代表一个utf-8类型,当需要处理中文、日文等复合字符时,需要用到rune类型,实际上是一个 int32类型。
package main
import "fmt"
func main() {
var a byte = 'a'
//单子字符使用单引号
fmt.Printf("%T %v %d",a,a,a)
// uint8 97 97对应的ASCII码
var b rune ='世' // '' 中也只能包含一个字符,超过报错
fmt.Printf("%T %v %d",b,b,b)
// int32 19990 19990对应的unicode码
//go使用特殊的rune类型处理unicode,
}

常量 const
常量就是恒定不变的量
可以在编译时,对常量的表达式进行计算求值,并在运行期间使用该计算结果,这个是无法修改的。

应用





切片 slice
动态分配大小的连续空间
内部结构包含地址,大小,容量
一般用于快速操作一块数据集合,类似切蛋糕,切的过程包括 从哪里开始(切片的地址) 切多大(切片的大小) 容量可以理解为装切片的口袋
切片有着指针的便利性,但比指针更加的安全,利用切片进行安全和高效的内存操作
切片像c中的指针,指针可以做运算,但是代价是内存操作越界,切片在指针的基础上增加了大小,约束了切片对应的内存区域,切片使用中无法对切片内部的地址和大小进行手动调整,因此切片比指针更加安全强大。
切片默认指向一片连续内存区域,可以是数组,也可以是切片本身
切片声明
var name [] T
name:表示切片类型的变量名
T:表示切片类型对应的元素类型
注意[]中是空的,有值的话那就成了数组了
package main
import "fmt"
func main() {
var a = [3]int{1, 2, 3}
fmt.Printf("%v", a)
//[1 2 3]
// 新建切片
var b = a[1:2]
fmt.Println(b)
// [2]
//声明字符串切片
var strList []string
fmt.Println(strList)
//声明整型切片
var numList []int
fmt.Println(numList)
//声明空切片 本来要在{}中填充切片的初始化数据,但是没有填充,所以切片是空的,但是这个变量已经被赋予了内存空间,只是没有元素
var nullList = []int{}
fmt.Println(nullList)
//切片判断空
//空切片的默认值是nil
var nullList1 = []int{}
if nullList1 == nil { // false 虽然其中没有值,初始化时{},但是内存空间已经生成,不是nil了
}
var nullList2 []int
if nullList2 == nil { // true 其中没有数据,是nil
}
//使用make()函数动态的构造切片
//make([] T,size,cap)
//T:切片的元素类型
//size:为这个类型分配多少元素
//cap:预分配的元素数量,这个值设定后不影响size,只是提前分配空间,降低多次分配空间造成的性能问题
a := make([]int,2)
b := make([]int,2,10)
fmt.Println(a,b) //[0,0] [0,0]
fmt.Println(len(a),len(b)) // 2 2
//a和b都云分配了2个元素的切片,只是b的内部存储空间已经分配了10个,但实际上使用了2个
//容量不会影响当前的元素个数,所以a b 的len结果都是2
//
//make函数生成的切片一定发生了内存分配操作,但给定开始与结束为止(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存
//区域,设定开始与结束位置,不会发生内存分配操作
//切片不一定必须经过make函数才能使用,生成切片,声明后使用append函数均可正常使用切片
}
切片取值
s := []int{1,2,3,4,5,6,7}
a := s[1:5:7]
fmt.Println(a) [2 3 4 5] 切片的截取得到的还是切片,不能超做容器的范围
fmt.Printf("%T",a) []int 切片类型
s = s[low : high : max] 切片的三个参数的切片截取的意义为 low为截取的起始下标(含), high为切取的结束下标(不含high),max为切片保留的原切片的最大下标(不含max);即新切片从老切片的low下标元素开始,len = high - low, cap = max - low;high 和 max一旦超出在老切片中越界,就会发生runtime err,slice out of range。另外如果省略第三个参数的时候,第三个参数默认和第二个参数相同,即len = cap
从切片或数组生成新的切片
格式: slice [start: stop]
slice:目标切片对象
start:对应目标的开始位置的索引
stop:对应目标的结束位置的索引
package main
import "fmt"
func main() {
var a = [3] int{1, 2, 3}
fmt.Printf("%v", a)
//[1 2 3]
// 新建切片
var b = a[1:2]
fmt.Println(b)
// [2]
}
从数组或者切片生成新的切片拥有以下特性:
- 取出的元素数量为: 结束位置 - 开始位置
- 取出元素不包含结束位置对应的索引,切片最后一个元素使用slice[len(slice)] 获取
- 当缺省开始位置时,表示从连续区域开头到结束位置
- 当缺省结束位置时,表示从开始位置到整个连续区域末尾
- 两者都缺省时,与切片本身等效
- 两者同时为0时,等于空切片,一般用于切片的复位
- 根据索引位置取切片slice元素值时,取值范围是 0~len(slice)-1 。越界会报错,生成切片时,结束位置可以填写len(slice) 但不会报错
//表示原有切片,开始与结束位置都被忽略,生成的切片将表示和原切片一致的切片,并且数据内容是一致的
a := []int{1,2,3}
fmt.Println(a[:]) //[1 2 3]
//a拥有3个元素的切片,将a切片使用a[:]进行操作后,得到的切片与a切片一直
//重置切片,清空元素,切片将变空
a := []int{1,2,3}
fmt.Println(a[0:0]) //[]
//append()
//可以为切片动态的添加元素,每个切片会指向一片内存空间,这片空间能容纳一定数量的元素,当空间不能容纳足够的元素时,切片就会
//进行扩容,扩容往往发生在append调用的时候
//在扩容时,容量的扩展规律按照容量的2倍扩充, 1 2 4 8 16.。。
//声明一个切片整型的
var number []int
//循环向切片中添加10个数
for i:=0;i<10;i++{
number = append(number,i)
//打印切片长度(元素个数),容量(切片容量)和指针变化
fmt.Printf("%d %d %p",len(number),cap(number),number)
//1 1 0xc0420080e8
//2 2 0x50
//3 4 0x
//4 8
//. . .
//8 8
//9 16
//10 16
//注意,len函数值并一定等于cap函数
//切片在创建的时候分配好了内存,添加元素超限后就是扩容了,内存将重新分配,
//append直接添加多个元素
var car []string
//添加单个元素
car = append(car,"a")
//添加多个元素
car = append(car,"a","b","c")
//添加切片 注意... 表示将整个切片添加到car后面
car = append(car,[]string{"c","d"}...)
数组 array
一段固定长度的连续内存区域,在声明时就确定了大小,使用时可以修改数组成员,但是数组大小不可变化
声明:
var 数组变量名 [元素数量] T
数组变量名:数组声明即使用时的名称
元素数量:数组的元素数量,可以是一个表达式,但最终必须是整型数值,元素数量不能含有到运行时才能确认大小的数值。
T: 可以使任何基本类型,包括T为数组本很,但类型为数组本身时,可以实现多维数组
package main
import "fmt"
func main() {
// 正常声明
var arr [5] int
arr[0] = 1
arr[2] = 4
arr[3] = 5
fmt.Println(arr) //[1 0 4 5 0]
// 直接初始化
var arr1 = [3] int {1,2,3}
fmt.Println(arr1,len(arr1)) //[1 2 3] 3
// 不指定数量,让编译器来计算
arr2 := [...] int {2,2,2,2,2,}
fmt.Println(arr2,len(arr2)) //[2 2 2 2 2] 5
//遍历数组
for k,v := range arr2{
fmt.Println(k,v)
//0 2
//1 2
//2 2
//3 2
//4 2
}
}
列表 list
内部实现原理是双链表,列表可以进行高效的任意位置的元素插入和删除
列表与切片和map的区别是,列表并没有具体元素类型的限制,所以,列表中的元素可以是任意类型,会带来一些问题:给一个列表放入了非期望类型的值,在取出值之后,将interface{} 转换为期望类型时会放生宕机
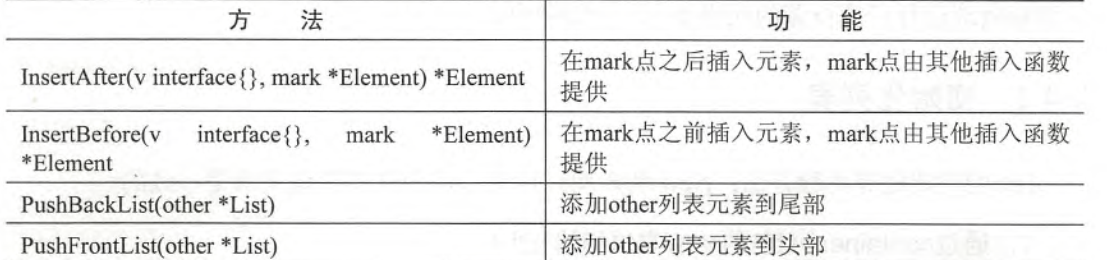
列表方法
package main
import (
"container/list"
"fmt"
)
func main() {
//初始化方法1
var list1 list.List
//list1 := list.List
//初始化方法2
list2 := list.New()
//元素的插入
//双链表支持从队列的前面和后面插入数据,分别对应的方法是 PushFront PushBack
//这两个方法都会返回一个 *list.Element结构,如果在以后使用中需要删除插入的元素,只能用过 *list.Element配合Remove方法进行删除
//这种方法让删除更加高效,也是双链表特性之一。
l := list.New()
l.PushBack("first") //将first字符串插入到列表的尾部,
l.PushFront(55) //将55插入到first之前
l.PushFront([]int{1,2,3,4})
//元素的删除
//列表的插入函数的返回值提供一个 *list.Element结构,这个结构记录着列表元素的值及其他节点之间的关系等信息
//从列表中删除元素时,需要用到这个结构进行快速删除
l := list.New()
//尾部添加
l.PushBack("first")
//头部添加
l.PushFront(55)
// 头部添加后保存元素句柄,此时句柄代表的就是切片
element := l.PushFront([]int{1,2,3,4})
//在切片后方添加元素
l.InsertAfter(55,element)
//在切片前方添加
l.InsertBefore("123",element)
//删除element对应的元素,此时将切片元素删除
l.Remove(element)
//遍历列表
//遍历双链表需要配合Front函数获取头元素,遍历时只要元素不为空就可以继续前行,
//每一次遍历调用元素的Next
l := list.New()
//尾部添加
l.PushBack("first")
//头部添加
l.PushFront(55)
//初始l.Front();条件 i!=nil;结束语句 i=i.Next()
for i:=l.Front();i != nil; i=i.Next(){
//元素在i的value属性中
fmt.Println(i.value)
}
}
结构体 struct
函数 function
映射 map
package main
import (
"fmt"
"sort"
"sync"
)
//大多数语言中映射关系容器使用两种算法:散列表和平衡树
/*散列表可理解为一个数组(桶) 数组的每个元素是一个列表,根据散列函数获得每个元素的特征值,将特征值作为映射的键,如果特征值重复。
表示元素发生碰撞,碰撞的元素将被放到同一个特征值的列表中进行保存。散列表的查找复杂度为O1 和属组一致,最坏的情况是On n为元素总数
散列需要尽量避免元素碰撞以提高效率,这样就需要对同进行扩容,每次扩容元素都要重新放入桶中,比较耗时
平衡树类似于父子关系的一颗数据数,每个元素在放入树时,都要与一些节点进行比较,平衡树的查找复杂度还用为O logn*/
//map的定义
//map [键的类型] 值的类型
//在一个map中,键值对总是成对出现的
//声明方法1
//手动使用make进行创建,
func main() {
m := make(map[string]int)
//向map中加入映射关系,
m["name"] = 55
fmt.Println(m) //map[name:55]
fmt.Println(m["name"]) //55
fmt.Println(m["age"]) //查找一个不存在的键,不会报错,返回的值类型的默认值,这里是0
}
//声明方法2
//在声明的时候直接进行内容填充
func main() {
m := map[string]int{
"name": 11,
"age": 12,
}
}
//判断在map中是否存在某个键
func main() {
//手动使用make进行创建,
m := make(map[string]int)
//向map中加入映射关系,
m["name"] = 55
value, ok := m["name"]
fmt.Println(value, ok) //55 true
value1, ok := m["name1"]
fmt.Println(value1, ok) //0 false
}
//对map遍历取值
func main() {
m := map[string]int{
"name": 11,
"age": 12,
}
for k, v := range m {
fmt.Println(k, v)
}
//只输出value
for _, v := range m {
fmt.Println(k, v)
}
//只要key的时候,不同使用匿名变量,直接忽略值即可
for k := range m {
fmt.Println(k, v)
}
}
//由于遍历输出的元素顺序与填充顺序无关,类似于其他语言的字典,本身就是无序的
//所以,如果希望输出的有顺序,那么需要进行排序
func main() {
m := map[string]int{
"name": 11,
"age": 12,
"num": 20,
}
//声明一个切片保存map
var s []string
for k := range m {
//声明一个切片保存存到切片中
//排序时,切片会被修改,需用一个变量来保留
s = append(s, k)
}
//进切片行排序,默认是按照字符串的升序
sort.Strings(s)
}
//delete 从map中删除键值对
//delte(map,键)
func main() {
m := map[string]int{
"name": 11,
"age": 12,
"num": 20,
}
delete(m, "name")
fmt.Println(m["name"]) //0
}
//清空map
//go中没有提供任何map清空元素的函数,清空map的唯一办法就是make一个新的map,go的并行垃圾回收机制比写一个清空函数高效多
//并发环境中使用map
//sync.Map
//go中的map在并发情况下,只读线程安全,同时读写线程是不安全的
//同时读写,使用两个并发函数不断的对map进行读写发生了竞态问题,map内部会对这种并发操作进行检查
//在并发读写时,一般的操作时加锁,这样导致性能不高,go在1.9提供了sync.Map
//特性:
//无序初始化,直接声明即可
//不能使用map的方式进行取值和设置的操作,而是使用sync.Map的 Store表示存储,Load表示获取,Delete表示删除
//使用range配合一个回调函数进行遍历操作,通过会掉皮函数内部遍历出来的值,range参数中的回调函数的返回值功能是 需要继续迭代遍历时,返回true 否则返回 false
func main() {
var m sync.Map
//加值
m.Store("name", 10)
m.Store("age", 10)
m.Store("num", 10)
// 读取
m.Load("name")
// 删除
m.Delete("name")
//遍历,需要提供一个匿名函数,参数kv 类型interface{}
//每次 range在遍历一个元素时,都会调用这个匿名函数吧结果返回
m.Range(func(k, v interface{}) bool {
fmt.Println("iterate", k, v)
return true
})
}
通道 channel
指针 point




变量、指针地址、指针变量、取地址、取值的相关关系特性:

用指针修改值
通过指针不仅可以取值,也可以修改值
指针的另一种声明方式

栈 stack
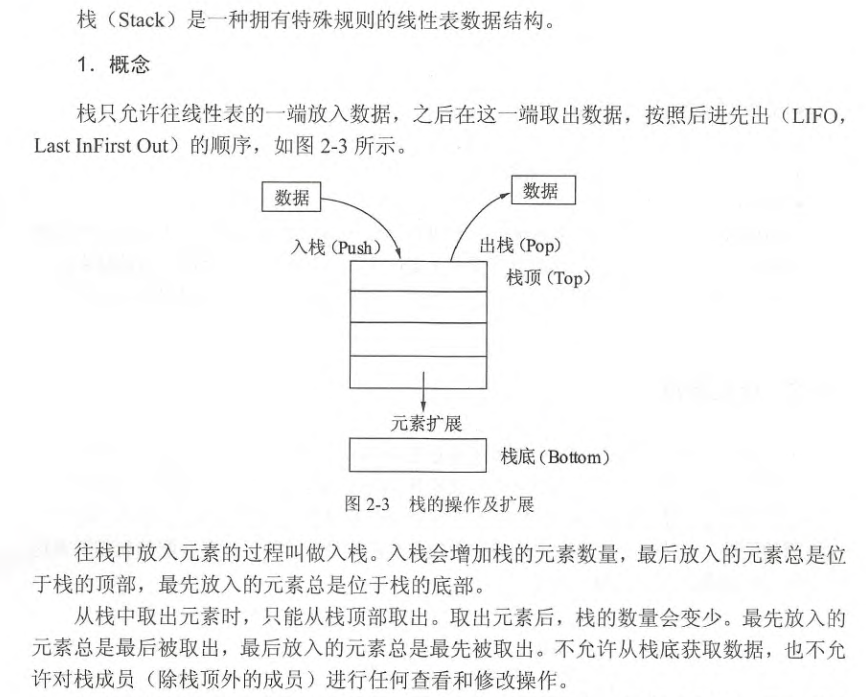
变量和栈的关系
栈可用于内存的分配,栈的分配跟回收非常的快



堆 deap
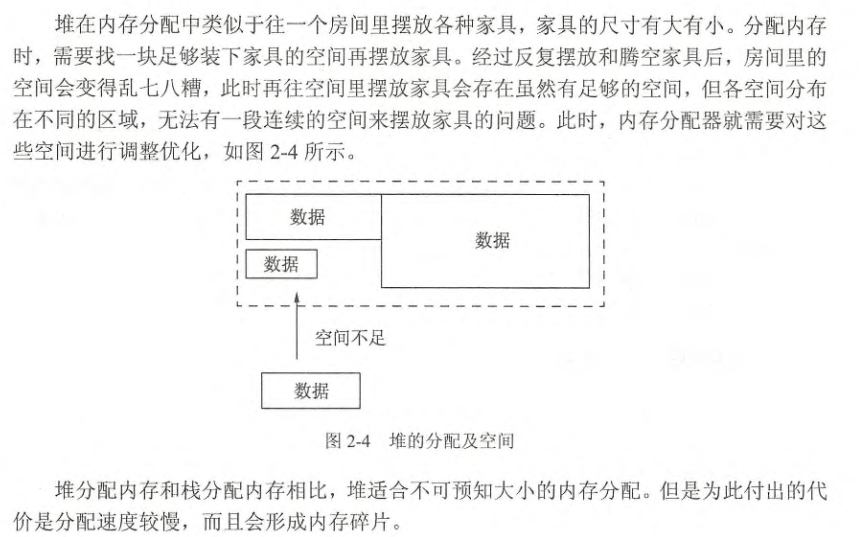
变量逃逸

package main
import "fmt"
// 次函数测试入口参数和返回值情况
func dummy(b int) int {
// 声明一个c赋值进入参数并返回
var c int
c = b
return c
}
// 定义一个空函数,
func void() {
}
func main() {
// 声明一个a变量
var a int
// 调用void函数
void()
// 打印a变量和dummy函数的返回值
fmt.Println(a, dummy(5))
}
//go run -gcflags "-m -l " 变量逃逸.go 执行
// gcflags 参数是编译参数, -m表示进行内存分配分析,-l表示避免程序关联,就是避免程序优化
// 结果
//.变量逃逸.go:25:13: a escapes to heap
////.变量逃逸.go:25:22: dummy(5) escapes to heap
////.变量逃逸.go:25:13: main ... argument does not escape
////0 5

取地址发生逃逸
package main
import "fmt"
// 声明一个空结构体测试结构体逃逸情况
type Data struct {
}
func dummy1() *Data{
//实例化c为Data类型
var c Data
// 返回函数局部变量地址
return &c
}
func main() {
fmt.Println(dummy1())
}
F:projectstudy_go>go run -gcflags "-m -l " 取地址发生逃逸.go
# command-line-arguments
.取地址发生逃逸.go:14:9: &c escapes to heap
.取地址发生逃逸.go:12:6: moved to heap: c
.取地址发生逃逸.go:18:20: dummy1() escapes to heap
.取地址发生逃逸.go:18:13: main ... argument does not escape
&{}

原则

类型别名






