基本代码结构
urls.py:
from django.conf.urls import url, include
from web.views.s5_parser import TestView
urlpatterns = [
url(r'test/', TestView.as_view(), name='test'),
]
views.py:
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.request import Request
from rest_framework.parsers import JSONParser
class TestView(APIView):
# JSONParser:请求头content-type为application/json
# FormParser:请求头content-type为application/x-www-form-urlencoded
# MultiPartParser: 请求头content-type为multipart/form-data
# FileUploadParser:上传文件
parser_classes = [JSONParser, FormParser, MultiPartParser, FileUploadParser, ]
def post(self, request, *args, **kwargs):
print(request.content_type)
# 获取请求的值,并使用对应的JSONParser进行处理
print(request.data)
# application/x-www-form-urlencoded 或 multipart/form-data时,request.POST中才有值
print(request.POST)
print(request.FILES)
return Response('POST请求,响应内容')
def put(self, request, *args, **kwargs):
return Response('PUT请求,响应内容')
parser_classes属性变量中的值,是各种解析器对象。前端会向后台发送不同类型的请求,而django后台的drf接口必须通过配置解析器才能获取到相关请求数据。常用的解析器主要是“JSONParser”和“FormParser”这两个解析器。
源码分析
-
为什么会使用parser_classes属性变量,它有什么用?
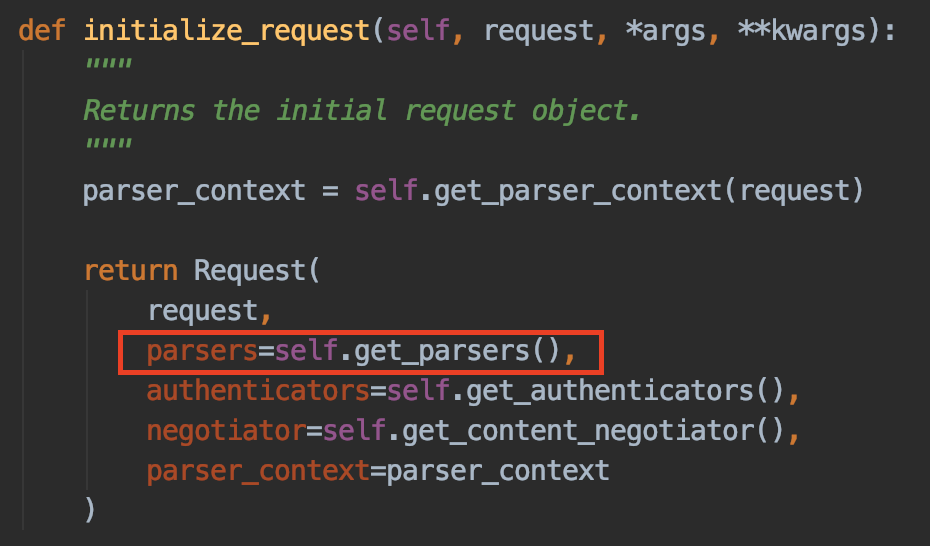
同样还是从APIView类的入口方法dispatch入口,在dispatch方法中,调用了initialize_request方法。这个方法在前文中已经说过,是用来封装django原生的request请求的。由上图知道,django原生的request请求数据被封装到了Request对象中,在实例化该对象时,将解析数据的解析器初始化到了parsers属性变量中。

跳转到get_parsers方法中,可以看到,同样也是返回的是列表生成式。
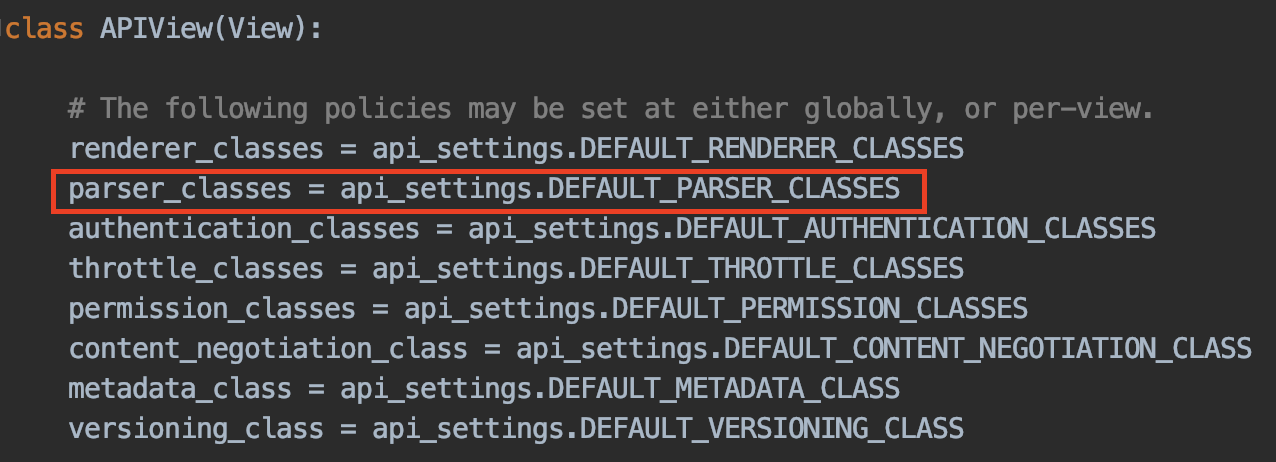
再跳转回APIView类中,可以看到属性变量parser_classes定义的地方。同样也可以通过settings配置文件进行全局配置。如果不需要进行全局配置,那就要在自定义的视图类中对parser_classes属性变量进行重新赋值,即:“parser_classes = [JSONParser, FormParser, MultiPartParser, FileUploadParser,]”。这列表元素都是解析器对象,只要这样配置好,drf就会根据parser_classes中的解析器去解析数据。
-
为什么从request.data中获取数据?
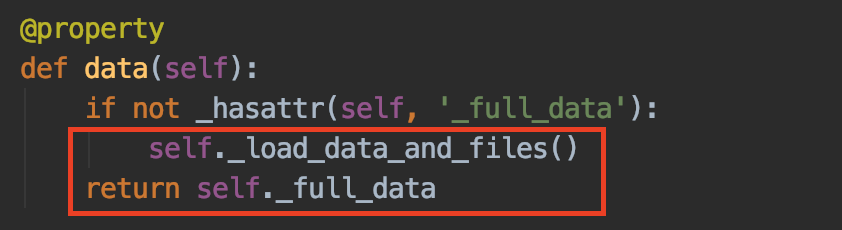
既然要分析为什么是从data中获取数据,那么分析的入口点当然就是data了。我们知道,django原生的request请求,会被drf通过Request对象封装,那么就跳转到Request类定义中看看这个“data”的实现。在data方法的实现中可以看到前端请求的数据是通过“_load_data_and_files”方法获取的,并且返回值是“_full_data”属性变量。先跳转到“_load_data_and_files”方法中:


在“_load_data_and_files”方法中可知,是通过调用“_parse”方法去获取请求数据的,并且将请求数据保存在“_data”和“_files”属性变量中。除文件相关的数据外的数据都保存在了“_data”中,而“_data”中的数据又都赋值到“_full_data”属性变量中。又由上一张图可知,“data”方法的返回值是“_full_data”,即:data方法获取到的数据就是“_full_data”中的数据。
再往下看,“content_type”属性变量是用来保存请求头的,所以,在基本代码结构中看到,只有设置了某些请求头才会通过“request.POST”来获取请求数据。
下面跳转到“_parse”方法中:

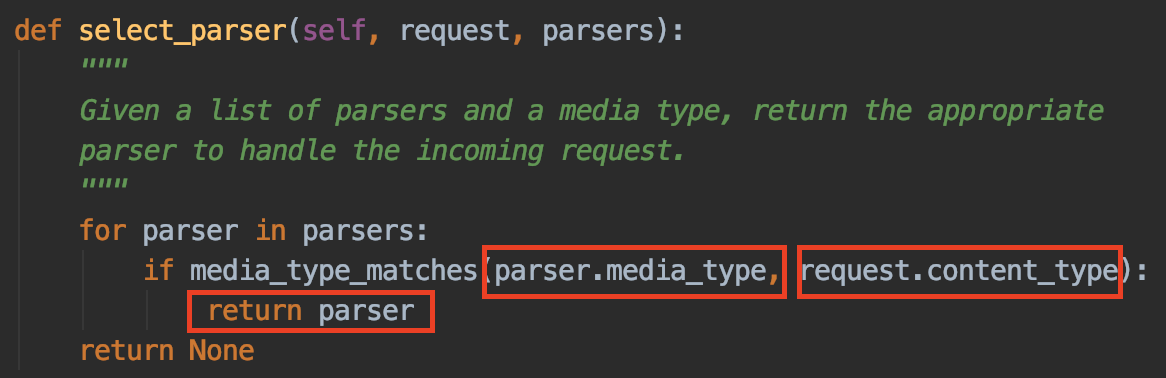

在“_parse”方法中,可以看到将获取到的请求头保存到了“media_type”变量中。然后又通过调用“select_parser(self, self.parsers)”方法,来选择所需要的解析器(参数“self.parsers”就是我们在自定义视图中“parser_classes”的值)。
又通过,parser_classes中解析器对象中的parser方法来解析请求到的数据,即:“parsed = parser.parse(steam, media_type, self.parser_context)”。这里以“JSONParser”对象为例,由上图可知,media_type属性变量中保存的是该解析器所对应的请求头,self.parser_context中,保存的是从前端请求中获取到的请求头。
再来到“JSONParser”类的“parse”方法中可知,再通过返回“json.load”来处理请求数据。返回的请求数据就会保存到“Request”类的“_parse”方法中的parsed变量中。而_parse方法的返回值为元组,第一个元素就是需要的数据。这些数据会在“_load_data_and_files”方法中,赋值给“Request”类的“_data”属性方法,而_data中的数据会赋值给“_full_data”中。因此,“Request”类中“data”方法返回值是“_full_data”,这样,就可以通过“request.data”获取请求数据。
全局配置
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES':[
'rest_framework.parsers.JSONParser'
'rest_framework.parsers.FormParser'
'rest_framework.parsers.MultiPartParser'
]
}
配置加入不同的解析器,就会解析不同类型的请求数据,当然是可以同时配置加入多个解析器的。同样的,配置了全局解析器后,那么,在自定义的视图类中,就可以不用通过“parser_classes”属性变量进行添加解析器的。