1.创建一个工程: scrapy startproject 工程名称
1. 目录结构:

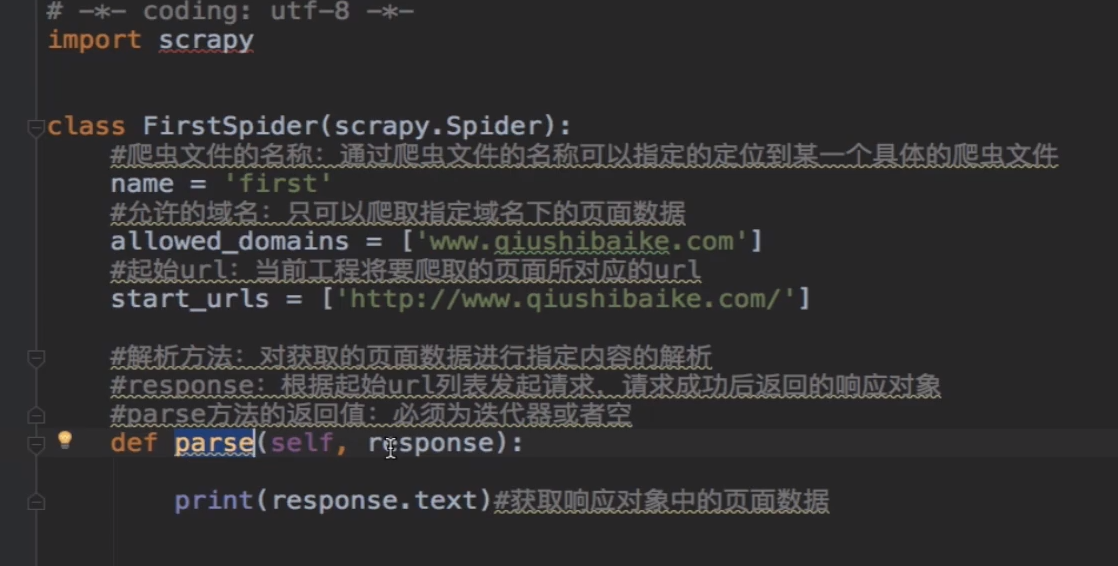
2.在工程目录下创建一个爬虫文件
1.cd 工程
2. scrapy genspider 爬虫文件的名称 起始的url
3.对应的文件中编写爬虫程序来完成爬虫的相关操作
4.配置文件的编写 修改
将settings.py 里面的22行的 ROBOTSTXT = True 改为False (这为爬虫是否遵循站点允许爬取的范围robot.txt协议)
19行的 USER_AGENT = "浏览器代理头"(对请求载体的身份进行伪装)
5.执行: scrapy crawl 爬虫文件的名称
6.打印结果包含日志, 如果打印结果不需要日志 scrapy crawl 爬虫文件的名称 --nolog(阻止日志信息的输出)
7.新建爬虫实例,爬取段子内容跟作者名
import scrapy class QiubaiSpider(scrapy.Spider): name = "qiubai" # allowed_domains = ["https://www.qiushibaike.com/text/"] start_urls = ["https://www.qiushibaike.com/text/"] def parse(self, response): # 建议大家使用xpath进行指定内容的解析(框架集成了xpath解析的接口) # 段子的内容和作者 div_list = response.xpath("//div[@id="content-left"]/div") for div in div_list: # xpath解析到的指定内容被存储到了Selector对象 # extract()该方法可以将Selector对象中存储的数据值拿到 # author = div.xpath("./div/a[2]/h2/text()").extract()[0] # extract_first() == extract()[0] author = div.xpath("./div/a[2]/h2/text()").extract_first() content = div.xpath(".//div[@class="content"]/span/text()").extract_first()
print(author)
print(content)