1. namenode介绍
namenode管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件fsimage和编辑日志文件edits。NameNode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息在系统启动时由数据节点重建。
namenode主要负责三个功能,分别是
管理元数据
维护目录树
响应客户请求
2. namenode关键文件夹
位于/opt/software/hadoop277/tmp/dfs/name/current目录中
(初次启动之前需要对namenode目录格式化:hadoop namenode -format)
seen_txid文件保存的是一个数字,就是最后一个edits_的数字
fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息
edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中
version: 该文件为namenode中一些版本号的信息
3. 元数据
3.1元数据格式
/jdk/jdk18.zip, 3, {blk_1,blk_2}, [{blk_1:[dd1,dd2,dd4]}, {blk_2:[dd0,dd1,dd3]}]
/jdk/jdk18.zip:这个文件在hdfs文件系统中的路径
3:这个文件的副本数(hdfs-site.xml可修改)
{blk_1,blk_2}:这个文件分成的块(默认满128M分成一个块)
dd0,dd1...:datanode节点,比如blk_1的3个副本分别存储在dd1,dd2,dd4中
3.2元数据的合并
3.2.1原因
1、随着集群的运行,edit logs文件逐步增大,管理该文件需要消耗资源
2、Namenode合并fsimage文件需要消耗资源
3、Namenode宕机后,再次恢复时会丢失一部分操作
2.2.2解决办法
使用secondarynamenode对元数据进行合并
2.2.3触发条件(其中之一即可)
到达检查点周期,默认1个小时。可通过 dfs.namenode.checkpoint.period属性手动配置。
一分钟检查一次操作次数,到达设置事务数量,默认一百万条。可通过dfs.namenode.checkpoint.txns属性配置
2.2.3合并过程
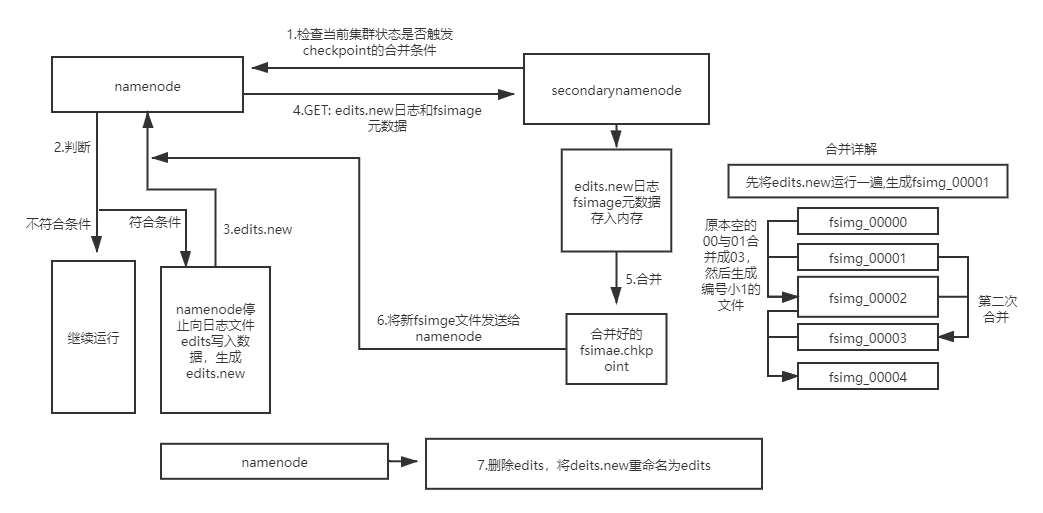
1、secondarynamenode检查当前集群状态是否触发checkpoint的合并条件
2、若未触发则继续运行,否则开始元数据合并
3、namenode停止向日志文件edits写入数据,并生成一个新的edits文件用于存储在合并期间产生的操作
4、secondarynamenode通过Http GET方式从namenode处下载edits文件和fsimage文件,并将fsimage文件载入内存
5、secondarynamenode逐条执行edits文件的更新操作,使内存中的fsimage文件保存最新的操作日志,结束后生成一个新fsimaget文件
6、secondarynamenode复制发送新fsimaget文件给namenode,然后删除edits.new
7、两个新文件替换前两个旧文件,等待下一次合并