题目1–前k大问题
题目:从一组元素(n个)中找出前k大个元素。

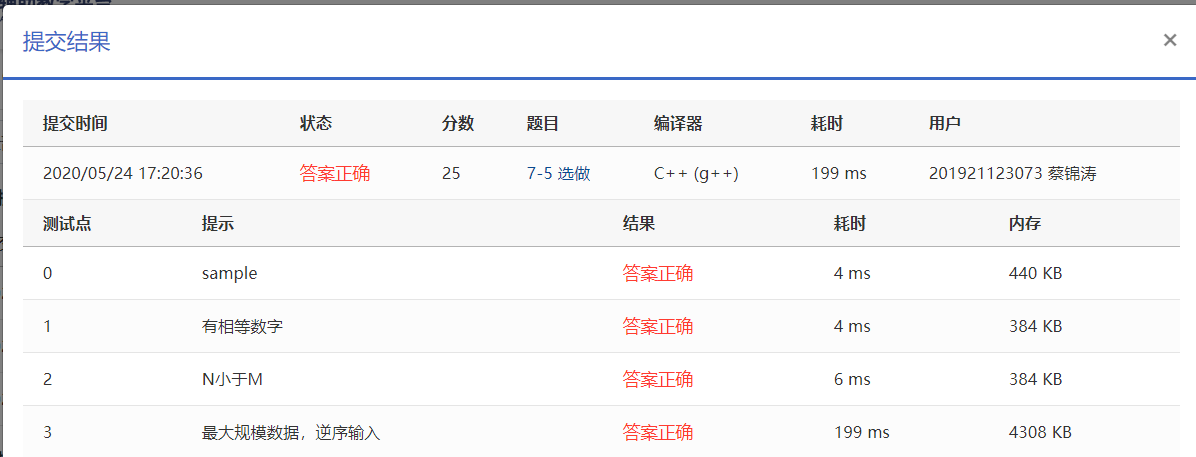
这题和PTA 7-5 选做 寻找大富翁差不多,7-5的提交情况:
代码
代码:
#include<iostream>
#define MaxNum 1000001
using namespace std;
int arr[MaxNum];
void sift(int R[], int low, int high) {
int i = low, j = i * 2;
int tmp = R[i];
while (j <= high) {
if (j < high && R[j] < R[j + 1]) j++;
if (tmp < R[j]) {
R[i] = R[j];
i = j;
j = 2 * i;
}
else break;
}
R[i] = tmp;
}
void Heap(int R[], int n, int m) {
int i, j, t;
for (i = n / 2; i >= 1; i--)
sift(R, i, n);
for (i = n, j = 0; i >= 2, j < m; i--, j++) {
t = R[1];
R[1] = R[i];
R[i] = t;
sift(R, 1, i - 1);
}
}
int main() {
int n, m;
scanf("%d %d", &n, &m);
for (int i = 1; i <= n; i++) {
scanf("%d", &arr[i]);
}
if (m > n) m = n;
Heap(arr, n, m);
for (int i = n, j = 1; j <= m; j++, i--) {
cout << arr[i];
if (j < m) cout << " ";
}
}
考核点
给出方法描述或示意图
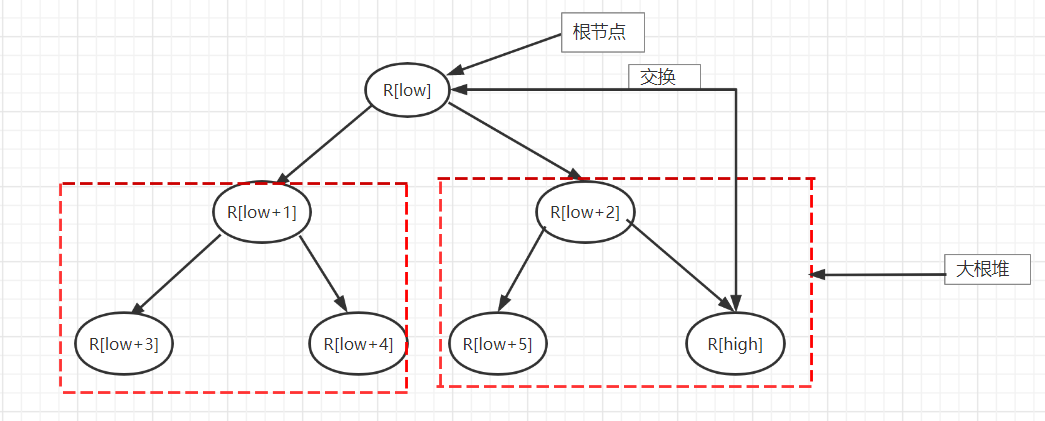
方法描述:输入n和k,随后输入n个整数,利用堆排序每趟产生的有序区一定是全局有序区(即每趟产生的有序区中的所有元素都归位了)且每次挑选最大元素归位的性质,用改造后的堆排序对数组进行排序,最后输出前k大元素。
堆排序首先要构建初始堆,在初始堆R[1..n]构造好后,根节点R[1]一定是最大元素,将其放到排序序列的最后,也就是将堆中的根与最后一个叶子结点交换。由于最大元素已归位,整个待排序的元素个数将减少一个。由于根节点的改变,这n-1个结点R[1..n-1]不一定为堆,但其左右子树均为堆,再调用一次sift函数将这n-1个结点R[1..n-1]调整成堆,其根节点为次大的元素,将它放到排序序列的倒数第2个位置,即将堆中的根与最后一个叶子结点交换,待排序的元素个数变为n-2个,即R[1..n-2],再调整,再将根节点归位,如此这样,直到归位了k个元素为止。
预估方法时间复杂度、空间复杂度
堆排序的算法分析:

堆排序的时间复杂度为O(nlog2(n)),但这个方法并不用进行n-1趟排序,所以预估平均时间复杂度应该略好于O(nlog2(n))
堆排序仅使用i、j、tmp等辅助变量,所以辅助空间复杂度为(1)
尝试给出伪代码
void sift(RecType R[], int low, int high) {
int i = low, j = i * 2;//R[j]是R[i]的左孩子
RecType tmp = R[i];
while (j 小于 high) {
if (j 小于 high && 右孩子比左孩子大) j指向右孩子j++;
if (根节点 小于 最大孩子) {
将R[j]调整到双亲结点位置上;
修改i和j值,以便继续向下筛选;
}
else 若根节点大于等于最大孩子,筛选结束;
}
被筛选结点放入最终位置上;
}
void Heap(RecType R[], int n, int k) {
int i, j;
RecType t;
for (i = n / 2; i >= 1; i--)//循环建立初始堆,调用sift函数n/2次
sift(R, i, n);
for (i = n, j = 0; i >= 2 && j < k; i--, j++) {
将最后一个元素与根R[1]交换;
对R[1...i - 1]进行筛选,得到i - 1个结点的堆;
}
}
int main() {
int n, k;
输入n和k;
for (int i = 1; i <= n; i++) {
输入n个元素,存放在arr数组中;
}
if (k 大于 n) k = n;
Heap(arr, n, k);
for (int i = n, j = 1; j <= k; j++, i--) {
从数组后往前输出k个元素;
if (j 小于 k) cout << " ";
}
}
拓展
输出前K大问题的其他解法
1.快排+分治思想
————(转载自C++ 输出前K大的数)
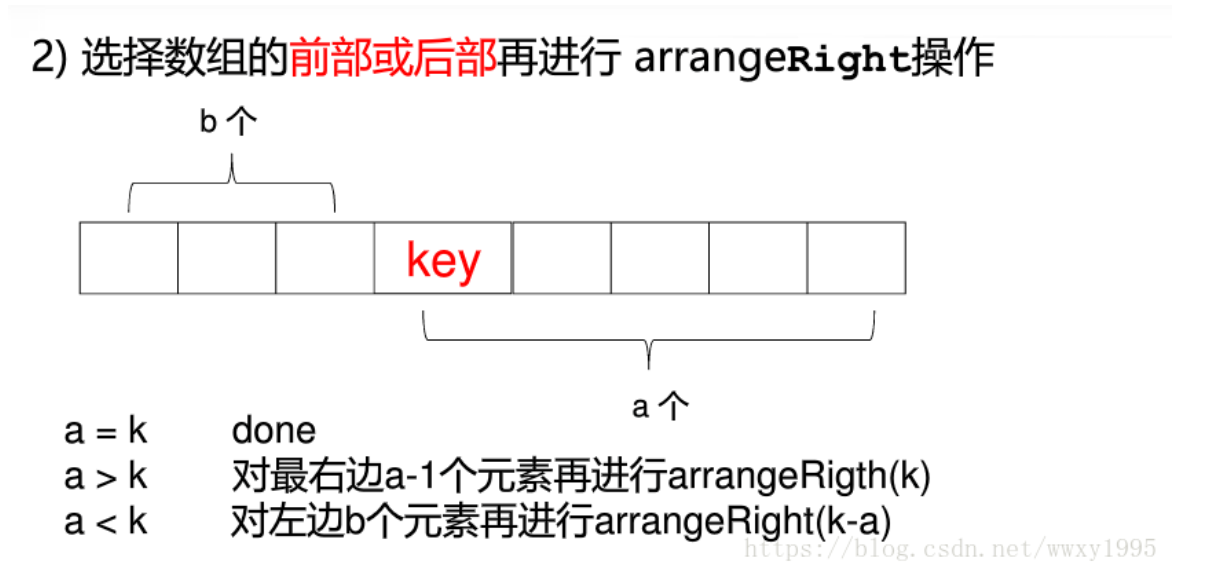
首先借助了快速排序的思想,一次快速排序之后,存在一个key牌,左边的数都小于这个key,右边的数都大于key,所以只要右边的数的个数刚好等于k那么就能找到这个数,在对右边的数进行排序就行
定义arrangeRight为操作使得右边的数为k,如果右边的数大于k,那么对右边部分递归调用这个函数
如果右边的数小于k,那么对左边e-j-s个数进行操作,使得右边的数等于k
最后在对k个数进行排序,时间复杂度是O(n+klogk)
代码:
#include<iostream>
#include<algorithm>
#define N 100010
using namespace std;
void swap(int &a, int &b)
{
int temp = a;
a = b;
b = temp;
}
void quicksort(int a[], int s, int e, int k)
{
// s 是数组的开始,e是数组的最后一个元素,k要求的前k个最大值
int m = a[s];
if (s >= e)
return;
int i = s, j = e;
while (i != j)
{
while (j > i&&a[j] >= m)
{
j--;
}
swap(a[i], a[j]);
while (j > i&&a[i] <= m)
{
i++;
}
swap(a[i], a[j]);
}
//quicksort(a, s, i - 1);
//quicksort(a, i + 1, e);
if ((e - j) == k)
{
// 如果已经有k个数在key的右边,则目标完成
return;
}
else if ((e - j) > k)
{
// 对右边的从j到e的数进行操作
quicksort(a, j, e, k);
}
else
{
// 对从s到j的数
quicksort(a, s, j, e - j - k);
}
}
int main()
{
int n, k;
int a[N];
scanf("%d", &n);
for (int i = 0; i < n; i++)
scanf("%d", &a[i]);
scanf("%d", &k);
quicksort(a, 0, n - 1, k);
sort(a+n-k, a + n);
for (int i = n-1; i >= n-k; i--)
{
printf("%d
", a[i]);
}
return 0;
}
2.维护小顶堆
————(转载自海量数据中找出前k大数(topk问题)和在N个数中查找第K大的数字(Top K问题))
思路:维护一个大小为k的小根堆,堆顶元素是最大K 个数中最小的一个,即第K个元素
处理过程对于数组中的每一个元素X,判断与堆顶的大小
如果X 比堆顶小,则不需要改变原来的堆, 因为这个元素比最大的K 个 数小。
如果X比堆顶大,要用X 替换堆顶的元素Y 。调整堆的时间复杂度为O(log2K)。
时间复杂度: O (N * log2 K ),算法只需要扫描所有的数据一次
空间复杂度:大小为K的数组,只需要存储一个容量为K 的堆。
注意、大多数情况下,堆可以全部载入内存。如果K 仍然很大,我们可以尝试先找最大的K ’个元素,然后找第K ’+1个到第2 * K ’
元素,如此类推(其中容量K ’的堆可以完全载入内存)。这时,每求出K’个数,就遍历一遍数据了
java代码:
public int findKthLargest(int[] nums, int k) {
PriorityQueue<Integer> minQueue = new PriorityQueue<>(k);
for (int num : nums) {
if (minQueue.size() < k || num > minQueue.peek())
minQueue.offer(num);
if (minQueue.size() > k)
minQueue.poll();
}
return minQueue.peek();
}
从海量数据中找出前k大数
————转载自海量数据中找出前k大数(topk问题)
eg:有1亿个浮点数,如果找出期中最大的10000个?
最容易想到的方法是将数据全部排序,然后在排序后的集合中进行查找,最快的排序算法的时间复杂度一般为O(nlogn),如快速排序。但是在32位的机器上,每个float类型占4个字节,1亿个浮点数就要占用400MB的存储空间,对于一些可用内存小于400M的计算机而言,很显然是不能一次将全部数据读入内存进行排序的。其实即使内存能够满足要求(我机器内存都是8GB),该方法也并不高效,因为题目的目的是寻找出最大的10000个数即可,而排序却是将所有的元素都排序了,做了很多的无用功。
第二种方法为局部淘汰法,该方法与排序方法类似,用一个容器保存前10000个数,然后将剩余的所有数字——与容器内的最小数字相比,如果所有后续的元素都比容器内的10000个数还小,那么容器内这个10000个数就是最大10000个数。如果某一后续元素比容器内最小数字大,则删掉容器内最小元素,并将该元素插入容器,最后遍历完这1亿个数,得到的结果容器中保存的数即为最终结果了。此时的时间复杂度为O(n+m^2),其中m为容器的大小,即10000。
第三种方法是分治法,将1亿个数据分成100份,每份100万个数据,找到每份数据中最大的10000个,最后在剩下的100×10000个数据里面找出最大的10000个。如果100万数据选择足够理想,那么可以过滤掉1亿数据里面99%的数据。100万个数据里面查找最大的10000个数据的方法如下:用快速排序的方法,将数据分为2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大堆个数N小于10000个,就在小的那堆里面快速排序一次,找第10000-n大的数字;递归以上过程,就可以找到第1w大的数。参考上面的找出第1w大数字,就可以类似的方法找到前10000大数字了。此种方法需要每次的内存空间为10^6×4=4MB,一共需要101次这样的比较。
第四种方法是Hash法。如果这1亿个书里面有很多重复的数,先通过Hash法,把这1亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,然后通过分治法或最小堆法查找最大的10000个数。
第五种方法采用最小堆。首先读入前10000个数来创建大小为10000的最小堆,建堆的时间复杂度为O(mlogm)(m为数组的大小即为10000),然后遍历后续的数字,并于堆顶(最小)数字进行比较。如果比最小的数小,则继续读取后续数字;如果比堆顶数字大,则替换堆顶元素并重新调整堆为最小堆。整个过程直至1亿个数全部遍历完为止。然后按照中序遍历的方式输出当前堆中的所有10000个数字。该算法的时间复杂度为O(nmlogm),空间复杂度是10000(常数)。
总结
综上所述,本篇所介绍的有三种方法,第一种是直接建大根堆,第二种是快排+分治思想,第三种是建立小根堆并维护,三种方法实际运行起来所用时间差不多,但第三种方法空间复杂度较好。其实还有其他许多方法,如计数排序+map、使用sort函数、基数排序、类二分查找等等。
输出前K大(Top k)问题主要锻炼我们使用排序算法的熟练度,以便在之后遇到问题时能快速判断出使用哪种算法。