图书信息管理系统
一、数据结构分析
答:(1)线性表:适用于数据元素类型相同且数据元素之间存在线性关系;应用:图书管理系统,稀疏多项式的运算。(2)栈:数据元素可以是任意类型的数据,但必须是同一个数据对象,栈中数据元素之间也是线性关系,特点是先进后出;应用:括号匹配,表达式求值。(3)队列:队列和栈类似,是一种特殊的线性表,但队列的特点是先进先出;应用:排队匹配,迷宫求解。(4)树:树型结构是一种非线性结构,树的结点之间有分支并具有层次关系;应用:二叉树,哈夫曼树等。(5)图:结点之间的关系可以是任意。应用:构造最小生成树,寻找最短路径。
本题,图书管理系统中,我选择线性表。理由:每本书都有相同的数据元素,可以把图书信息表抽象成一个线性表,每一本书作为线性表的一个元素。
二、存储结构分析
采用顺序存储结构还是链式存储结构?分析顺序结构和链式结构分别适合用于什么样的场景,在本题中选择哪种存储结构,并说明原因。
答:图书管理系统中,如果图书数据较多,需要频繁的进行插入和删除操作可采用链表,若图书数据个数变化不大,很少进行插入和删除则可采用顺序表。此题,我选择双链表。理由:我以文本BookLis.txt中读取书籍信息,数据较多所以选择链表,同时,我以冒泡排序法对书籍排序,在链表结点比较时需要比较多轮,所以选择双链表,方便回溯到表头。
三、存储结构的实现
1、符号常量定义
#define OK 1
#define ERROR 0
typedef int Status;
2、类型定义
(1)链表结点定义
typedef struct LNode
{
Book data;
struct LNode *next;
struct LNode *prior;
}LNode, *LinkList;
(2)对Book类型定义
typedef struct Book
{
char bookname[30];
char ISBN[30];
char price[10];
char author[30];
char press[30];//出版社
char time[15];//出版时间,例如2019.06.18
char vetrsion[10];//版本
char page[10];
char flag;//状态,判断是否可借
int mark = 0;//标记
}Book;
(3)符号重载
a: 对输入符“>>”重载:
friend istream &operator >> (istream &i, Book& b)
{
cout << "请输入书号ISBN:"; i >> b.ISBN;
cout << "请输入书名:"; i >> b.bookname;
cout << "请输入价格:"; i >> b.price;
cout << "请输入作者:"; i >> b.author;
cout << "请输入出版时间:"; i >> b.time;
cout << "请输入出版社:"; i >> b.press;
cout << "请输入版本号:"; i >> b.vetrsion;
cout << "请输入页数:"; i >> b.page;
cout << "状态(1可借),(0不可借):"; i >> b.flag;
cout << " ";
return i;
}
b: 对输出符“<<”重载:
friend ostream &operator << (ostream &i, Book& b)
{
cout << "+——————————————+ ";
cout << "|ISBN:" << setfill(' ') << setw(15) << b.ISBN << setfill(' ') << setw(8) << "|" << endl;
cout << "|" << setfill(' ') << setw(29) << "|" << endl;
cout << "|书名:" << setfill(' ') << setw(15) << b.bookname << setfill(' ') << setw(8) << "|" << endl;
cout << "|" << setfill(' ') << setw(29) << "|" << endl;
cout << "|作者:" << setfill(' ') << setw(15) << b.author << setfill(' ') << setw(8) << "|" << endl;
cout << "|" << setfill(' ') << setw(29) << "|" << endl;
cout << "|价格:" << setfill(' ') << setw(15) << b.price << setfill(' ') << setw(9) << "|" << endl;
cout << "|" << setfill(' ') << setw(29) << "|" << endl;
cout << "|页数:" << setfill(' ') << setw(15) << b.page << setfill(' ') << setw(8) << "|" << endl;
cout << "|" << setfill(' ') << setw(29) << "|" << endl;
cout << "|版本:" << setfill(' ') << setw(15) << b.vetrsion << setfill(' ') << setw(8) << "|" << endl;
cout << "|" << setfill(' ') << setw(29) << "|" << endl;
cout << "|出版时间:" << setfill(' ') << setw(15) << b.time << setfill(' ') << setw(5) << "|" << endl;
cout << "|" << setfill(' ') << setw(29) << "|" << endl;
cout << "|出版社:" << setfill(' ') << setw(15) << b.press << setfill(' ') << setw(6) << "|" << endl;
cout << "|" << setfill(' ') << setw(29) << "|" << endl;
if (b.flag == '0')
cout << "|状态:" << setfill(' ') << setw(15) << "已借出" << setfill(' ') << setw(8) << "|" << endl;
else
cout << "|状态:" << setfill(' ') << setw(15) << "可借" << setfill(' ') << setw(8) << "|" << endl;
cout << "+——————————————+ ";
return i;
}
说明:对“<<”重载时使用了<iomanip>库中的setfill(),setw()函数,目的是格式化输出书籍信息,更加工整美观。
四、基本操作概要设计
1、InitList(LinkList &L)
操作结果:构造一个空的双链表L
2、CreateList(LinkList &L)
初始条件:双链表L已存在
操作结果:从BookList.txt文件中读取书籍数据存入双链表L
3、ListInsert(LinkList &L)
说明:使用后插法插入双链表L
初始条件:双链表L已存在
操作结果:插入一个新结点于表L尾部
4、ListRevise(LinkList &L, char ISBN[])
初始条件:双链表L已存在,用户输入ISBN号
操作结果:修改ISBN号对应书籍的数据
5、ListDelete(LinkList &L, char ISBN[])
初始条件:双链表L已存在,用户输入ISBN号
操作结果:删除ISBN号对应书籍的数据
6、LocateList(LinkList L, int oper)
初始条件:双链表L已存在,用户输入oper查找方式和查找关键字
操作结果:返回关键字对应书籍数据
说明:oper提供4种查找方式:
<1>按ISBN查找 <2>按作者查找 <3>按书名查找 <4>按出版社查找
7、OrderList(LinkList &L, int oper, int i)
初始条件:双链表L已存在,用户输入oper排序方式
操作结果:双链表L按oper方式排序
说明:oper提供4种排序方式:
<1>按书名排序 <2>按价格排序 <3>按ISBN排序 <4>按出版时间排序
8、ReturnBook(LinkList L)
初始条件:双链表L已存在,用户输入ISBN
操作结果:对应ISBN书籍状态更新
9、BorrowBook(LinkList L)
初始条件:双链表L已存在,用户输入ISBN
操作结果:对应ISBN书籍状态更新
10、CountList(LinkList L, int oper)
初始条件:双链表L已存在,用户输入oper计数方式
操作结果:返回按oper计数结果
说明:oper提供3种计数方式:
<1>按出版社计数 <2>按作者计数 <3>按状态计数
11、DisplayList(LinkList L)
初始条件:双链表L已存在
操作结果:遍历双链表L显示每个结点数据
12、SaveData(LinkList L)
初始条件:双链表L已存在
操作结果:打开BookList.txt文件覆写数据,
说明:程序退出时自动调用SaveData更新数据
五、基本操作详细设计
1、创建链表
创建链表L时直接从文件BookList.txt文件中读入数据,免去了需要用户输入大量书籍信息的工作。
Status CreateList(LinkList &L)
{
fstream file;
file.open("BookList.txt");
if (!file) {
cout << "错误!未找到文件! " << endl;
exit(ERROR);
}
LNode *p, *r;
r = L;
while (file.peek() != EOF) {
p = new LNode;
file >> p->data.ISBN >> p->data.bookname >> p->data.price
>> p->data.author >> p->data.time >> p->data.press
>> p->data.vetrsion >> p->data.page >> p->data.flag;//“>>”提取符
p->prior = r;
p->next = NULL;
r->next = p;
r = p;
}
L->prior = r;
r->next = L;
return OK;
}
BookList.txt文件:
1111 数据结构 53.00元 严蔚敏 2018.03.12 人民出版社 第3版 239页 1
2222 程序设计 48.00元 冯希 2003.04.14 邮电出版社 第4版 513页 1
3333 前端开发 62.00元 楼浩仁 2014.09.05 邮电出版社 第3版 384页 1
4444 大学英语 35.00元 蒋官东 2006.12.09 重庆出版社 第8版 473页 1
5555 高等数学 59.00元 康峰 2007.04.31 人民出版社 第7版 743页 1
6666 近代史 81.00元 何虎 2001.06.21 重庆出版社 第5版 634页 0
7777 线性代数 47.00元 蒋文 2017.03.24 人民出版社 第5版 634页 1
注:(每本书的元素之间用空格隔开,两本书之间可以不用换行或空格)
óóó原因:
(1)提取符“>>”从file中提取各种数据。“>>”会以空格为分隔符逐个从文件中读取数据(>>会忽略空格和换行符)并将其保存到相应的数据变量中,若没有空格数据会依次读入变量中直到变量空间已满或者遇到EOF文件结束符时才会停止,所以同一本书的不同元素之间需要以空格隔开。
(2)两本书之间可以不用换行或空格,以下面为例:
…… 人民出版社 第3版 239页 12222 程序设计 48.00元 冯骥 ……
每本书最后一个数据为char flag单个字符变量,当“>>”读取字符 “1”或者“0”后,flag空间已满,“>>”仍可以读取后面“2222”数据但不能存入flag中,只能等到下一次存入新的一本书的第一个变量中(即ISBN)。因此仍可以正常读入数据
2、 链表排序
对链表排序时,涉及中文汉字排序。通过一个小项目test测试中文字符比较大小:
int main()
{
char a[30] = "人民教育出版社";
char b[30] = "邮电出版社";
char c[30] = "重庆出版社";
if (strcmp(a, b) < 0)
cout << b << "大";
if (strcmp(a, c) > 0)
cout << c << "小";
if (strcmp(b, c) < 0)
cout << b << "小";
return 0;
}
这里发现strcmp函数比较中文字符时,根据第一个字符首字母比较大小,然后依次后移进行比较。所以排序时以strccmp函数比较关键字大小。每一轮比较结束后需要指针p需要回溯到表头L为下一轮比较做准备,因为L为双链表可直接p=p->next,只需要判断一轮是否结束。此处按书名排序为例:
LNode *p = L->next, *q = L->next;
if (!p)
return 0;
int flag = 1;
if (oper == 1) {//按书名排序
while (flag && i >= 0) {//冒泡排序
flag = 0;
while (p->next != L) {
if (strcmp(p->data.bookname, p->next->data.bookname) > 0) {
LNode *q;
q = new LNode;
q->data = p->next->data;
p->next->data = p->data;
p->data = q->data;
flag = 1;//标志置为1表示本轮有交换
}
p = p->next;
}
--i;
p = L->next;//重新指向首元结点为下轮准备
}
}
3、 统计计数功能
例如:用户要求按“<1>出版社”计数,我们需要找到关键字出版社的名字并对链表进行遍历,找到关键字相同的结点时计数器+1,然后进行第二次遍历,这是关键字已经不再是上一次出版社的名字了,而是另一个与前一次不同的出版社的名字,这里的难点就是我们不知道出版社应该有几类,也不知道要遍历多少次才能全部统计结束。因此,我在Book类型里面添加了一个标记int mark表示已经遍历并且计数成功时,mark由0(未读)置为1(已读)。第一次遍历时将第一个结点mark置为1并strcpy关键字到一个新的字符串数组中,一轮遍历结束后要对关键字进行更新并继续遍历,直到全部结点mark为1或者遍历指针q=L时统计完成。
if (oper == 1) {//按出版社计数
while (q != L) {
char press[30] = { 0 };
int num = 1;
while (p != L && p->data.mark == 1) {//p遍历找到未读标记
p = p->next;
q = p;//下一次从p(未读)开始
}
if (q == L)//全部统计结束
break;
strcpy_s(press, p->data.press);//更新关键字
p->data.mark = 1;
while (p != L) {
if (!strcmp(press, p->next->data.press)) {
++num;
p->next->data.mark = 1;
}
p = p->next;
}
q = q->next;
p = q;
cout << "------------------------ ";
cout << press << " " << num << "本" << endl;
}
óóó这里需要注意!!!
如果用户要求再次统计时,会统计失败。原因是统计结束后链表结点的mark值全部为1,再次统计时无法找到标记值为0的结点,所以每次统计结束后需要重置mark为0,才能够保证再次统计,问题解决。
p = L->next;
while (p != L) {
p->data.mark = 0;
p = p->next;
++total;//书籍总数
}
4、 关于查找问题
链表的查找很简单,就是通过关键字遍历匹配,找到关键字相匹配的结点,返回该结点并结束。刚开始我也是这样用的,然而实际情况还需要多考虑一下。例如:按作者查找书籍,关键字“刘云杰”,那么遍历时我们会找到与“刘云杰”匹配成功的结点并返回它,查找结束。如果“刘云杰”写了多本书呢?这种情况我们始终只能找到第一本匹配成功的书而无法确定后续结点是否也满足。针对这点不足,需要对LocateList改写:
while (p != L) {
if (!strcmp(author, p->data.author))
cout << p->data;
p = p->next;
}
5、新增借还功能
在Book类型里面增加了char flag状态标志,1为可借,0为已借出。用户按照ISBN号查找书籍并完成借还。这里有一个错误控制,即书籍状态为0时,会有提示该书为不可借状态。
Status BorrowBook(LinkList L)//借书
{
cout << "请输入ISBN:";
char newISBN[30];
cin >> newISBN;
LNode *p;
p = L->next;
while (p != L && strcmp(newISBN, p->data.ISBN))
p = p->next;
if (p == L)
p = NULL;
else if (p->data.flag == '0')
{//判断书籍状态
cout << "借书失败,该书为不可借状态! ";
return ERROR;
}
else
p->data.flag = '0';
return OK;
}
Status ReturnBook(LinkList L)//还书
{
cout << "请输入ISBN:";
char newISBN[30];
cin >> newISBN;
LNode *p;
p = L->next;
while (p != L && strcmp(newISBN, p->data.ISBN))
p = p->next;
if (p == L)
p = NULL;
else
p->data.flag = '1';
return OK;
}
6、保存数据
在退出程序时对链表的数据进行覆写。我们保存数据后,第二次运行程序需要重新读入数据,前面提到元素之间必须要有空格,这时必须要保证上一次程序结束时,覆写的数据必须符合读入的格式。这里用fprintf(fp1, " ")来保证元素之间的空格,fprintf(fp1, " ")对每一本书的数据进行换行写入文本来保证格式工整。
Status SaveData(LinkList L)
{
LNode *p;
p = L->next;
FILE* fp1;
errno_t err;
err = fopen_s(&fp1, "BookList.txt", "w");
if (err != 0) {
printf("文件打开失败! ");
exit(0);
}
while (p != L) {
fputs(p->data.ISBN, fp1);
fprintf(fp1, " ");//元素之间用空格隔开,这里必须有空格
fputs(p->data.bookname, fp1);
fprintf(fp1, " ");
fputs(p->data.price, fp1);
fprintf(fp1, " ");
fputs(p->data.author, fp1);
fprintf(fp1, " ");
fputs(p->data.time, fp1);
fprintf(fp1, " ");
fputs(p->data.press, fp1);
fprintf(fp1, " ");
fputs(p->data.vetrsion, fp1);
fprintf(fp1, " ");
fputs(p->data.page, fp1);
fprintf(fp1, " ");
fputc(p->data.flag, fp1);
if (p->next != L)//每本书之间换行再写入,当然也可以不用换行,不影响读入
fprintf(fp1, " ");//换行是为了文本数据工整美观
p = p->next;
}
fclose(fp1);
return OK;
}
óóó关于换行
这里为什么要p->next != L 才换行,也就是说为什么在最后一本书写入完成之后不能换行?经过我的测试,如果在最后一本书换行,第二次再读入文件时会多读入一次数据,而且显示时会多出一本书,这本书的信息为空白。
if (p->next != L)//每本书之间换行再写入,当然也可以不用换行,不影响读入
fprintf(fp1, " ");//换行是为了文本数据工整美观
原因:while (file.peek() != EOF)中peek()会预读下一个字符,在最后一本书写入完成之后,如果添加了换行符(或者空格),那么再次打开程序进行读入文件时,会将最后一行的换行符或者空格也读入链表中(在这里多出一本空白书),然后才是读入文件结束符EOF结束。前面提到“>>”自动忽略空格和换行符,那么在最后一行的换行符为什么没有被忽略而是被读入了呢?
网上查阅资料:
(1)“>>”操作符会忽略前面的空白符和换行符,但不会越过后面的换行符和空白符
(2)get()方法不会略过任何符号
(3)peek()方法预读取下一个字符(不管是何符号)
六、程序总体设计
1、构造链表。
(1) InitList(L):初始化链表L
(2) CreateList(L):
从BookList.txt文件中读取书籍信息存入链表中。
链表构造成功,书籍信息被录入链表中。
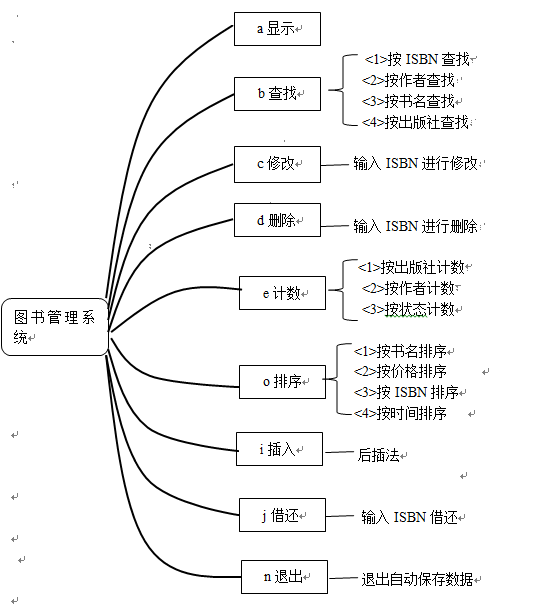
2、功能选择:
七、主程序
主程序的实现代码。注意给出注释。
int main()
{/********标题***********/
cout << "***********************************************************************************************" << endl;
cout << "*** xx ***-----****----***** 图书管理系统 *****-----****----*** xx ***" << endl;
cout << "*** xx ***-----****----***** 图书管理系统 *****-----****----*** xx ***" << endl;
cout << "*** xx ***-----****----***** 图书管理系统 *****-----****----*** xx ***" << endl;
cout << "***********************************************************************************************" << endl;
/*********************构造链表********************/
LinkList L;
InitList(L);
CreateList(L);//从BookList.txt文件中读取书籍信息
/*********************功能选择********************/
char ch;
while (1)
{
cout << "++-------------------------------------------------------------------------------------------------------------++ ";
cout << "||请选择要进行的操作:<a>显示 <b>查找 <c>修改 <d>删除 <e>统计计数 <o>排序 <i>插入 <j>借还 <n>退出 || ";
cout << "++-------------------------------------------------------------------------------------------------------------++ ";
ch = _getwch();
if (ch == 'a')//显示
DisplayList(L);
else if (ch == 'b') {//查找
cout << "++----------------------------------------------------------------------------------++ ";
cout << "||请选择要进行的操作:<1>按ISBN查找 <2>按作者查找 <3>按书名查找 <4>按出版社查找|| ";
cout << "++----------------------------------------------------------------------------------++ ";
int oper;
cin >> oper;
LocateList(L, oper);
}
else if (ch == 'c') {//修改
cout << "请输入需要修改书籍的ISBN号." << endl;
char ISBN[30];
cin >> ISBN;
ListRevise(L, ISBN);
}
else if (ch == 'd') {//删除
cout << "请输入需要删除书籍的ISBN号." << endl;
char ISBN[30];
cin >> ISBN;
if (ListDelete(L, ISBN))
cout << "删除成功! ";
else
cout << "删除失败! ";
}
else if (ch == 'e') {//统计计数
int oper;
cout << "<1>按出版社计数 <2>按作者计数 <3>按状态计数 " << endl;
cin >> oper;
CountList(L, oper);
}
else if (ch == 'j') {//结束、还书
cout << "<b> 借书 <r> 还书 ";
char x;
cin >> x;
if (x == 'b' && BorrowBook(L))
cout << "借书成功! ";
else if (x == 'r'&& ReturnBook(L))
cout << "还书成功! ";
}
else if (ch == 'o'){//排序
cout << "+---------------------------------------------------------------------------------+ ";
cout << "|请选择排序方式:<1>按书名排序 <2>按价格排序 <3>按ISBN排序 <4>按出版时间排序 | ";
cout << "+---------------------------------------------------------------------------------+ ";
int oper, i = 0;
cin >> oper;
LNode *q = L->next;
while (q != L) {
q = q->next;
++i;//数据节点个数i
}
if (OrderList(L, oper,i))
cout << "排序成功! ";
else
cout << "排序失败! ";
}
else if (ch == 'i') {
if (ListInsert(L))
cout << "插入成功! ";
else
cout << "插入失败! ";
}
else if (ch == 'n') {//退出
SaveData(L);
break;
}
}
}
八、编译调试
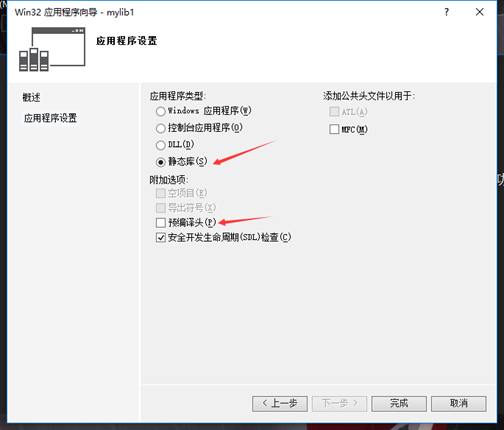
由于要求函数部分做成lib,可在此处介绍如何生成lib的过程,以及在工程中怎么调用自定义的lib文件中的函数。
1、创建静态库项目
2、添加文件
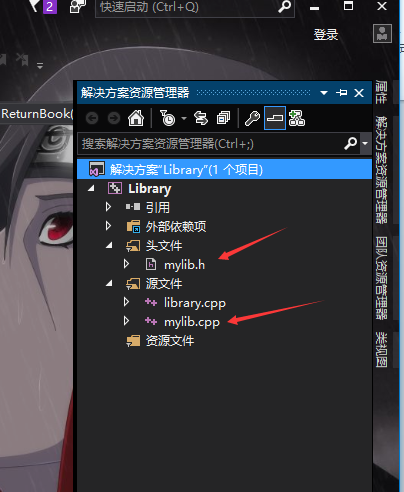
在解决方案中添加 .h头文件和对应的 .cpp文件,头文件中声明函数和常量定义,cpp文件中给出函数的具体实实现。
3、解决方案
这样会生成一个.lib文件和.h文件,这样就完成了一个静态库。
4、调用lib
然后我们可以把.lib文件和.h文件放到我们的项目中,这样就可以使用自己
静态库函数了,当然也可以不拷贝文件,只要我们的程序中写明.lib文件的
路径,也是同样可以使用的。
九、总结
这次的作业让我实现了人生第一个600行代码和人生第一个6000字的word报告。真是好久没有这么认真的完成作业了。对于本次设计的不足之处,我想应该是实用性不大,或许根本没有实用的可能性,因为这根本不能称得上是图书管理系统,与真正的图书管理系统相比,我这算是垃圾了吧简直丑陋至极。不过我很兴奋,这算是我大学里第一次起步吧,这学期的数据结构这门课程,我收获到的不仅是知识,还有很多其他宝贵的东西……就这样吧也算是对这门课程有了交代。时间还早,路还很长,我还年轻。