2018-01-18
工作队列是Linux内核中把工作延迟执行的一种手段,其目的不同于软中断,软中断是提高CPU的响应,尽可能的缩短关中断的时间;而工作队列主要目的是节省资源,其比较适合很微小的任务,比如执行某个唤醒工作等。通过创建线程同样可以达到目的,但是线程毕竟有其自身的资源开销如CPU、内存等。如果某个任务很小的话,就不至于创建一个线程,因此Linux内核提供了工作队列这种方式。本文参考内核代码3.10.1版本,而此时的工作队列称为Concurrency Managed Workqueue (cmwq),对于传统的工作队列,本文就不做介绍。
一、总体描述
在详细介绍工作队列前,我们先看下相关的核心数据结构
struct work_struct { atomic_long_t data; struct list_head entry; work_func_t func;//工作处理函数 #ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map; #endif };
这是工作队列机制暴露给外部(使用方)的工作对象,entry维护该结构在worker_pool中的链表,func是一个函数指针,指向该工作需要执行的处理函数,而data成员从代码还未看出具体作用。一个驱动程序后者内核模块要使用工作队列,创建一个work_struct结构,填充其中的func字段即可,之后调用schedule_work提交给对象即可。关于schedule_work后面我们在描述,下面开始展开内核对于工作队列的管理。
内核中既然把工作队列作为一种资源使用,其自然有其自身的管理规则,因此在内核中涉及到一下对象:
- worker 工作者,顾名思义为处理工作的单位
- worker_pool 工作者池,每个worker必然属于某个worker_pool,一个worker_pool可以有多个worker
- workqueue_struct 官方解释是对外部可见的workqueue
- pool_workqueue 链接workqueue_struct 和worker_pool的中介,每个workqueue_struct 可以有多个worker_pool,而一个worker_pool只能属于一个workqueue_struct
几个对象之间的关系如下图所示:
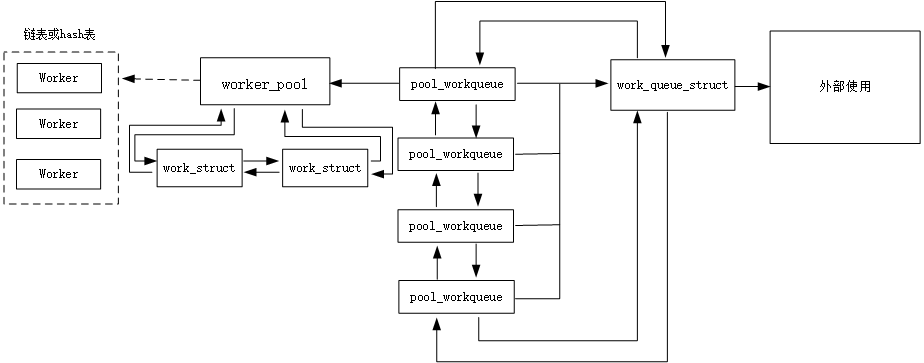
如前所述,外部使用的意思就是如果要使用工作队列,就是创建好work_struct结构,然后调用schedule_work即可,剩下的处理任务就是系统部分完成了。每个和外部交互的workqueue_struct,对应有多个pwq(pool_workqueue ),pool_workqueue 链接workqueue_struct和worker_pool的桥梁,worker_pool是核心所在,其包含有所有的worker,以及该pool对应的item即work_struct。其中worker其实就是一个线程,根据busy后者空闲位于hash表或者链表中。而所有的item就通过双链表的方式链接到worker_pool维护的链表头上。
二、具体介绍
2.1 workqueue(workqueue_struct)
该结构是 externally visible workqueue,即外部可见的工作队列,而其本身主要描述队列的属性,既不包含worker也不包含work。一个workqueue对应多个pwd,这些pwq链接在workqueue_struct结构中的pwqs链表头上。而系统中所有的workqueue通过list字段链接成双链表。系统内部已经定义了几个workqueue,如下所示
struct workqueue_struct *system_wq __read_mostly; EXPORT_SYMBOL(system_wq); struct workqueue_struct *system_highpri_wq __read_mostly; EXPORT_SYMBOL_GPL(system_highpri_wq); struct workqueue_struct *system_long_wq __read_mostly; EXPORT_SYMBOL_GPL(system_long_wq); struct workqueue_struct *system_unbound_wq __read_mostly; EXPORT_SYMBOL_GPL(system_unbound_wq); struct workqueue_struct *system_freezable_wq __read_mostly; EXPORT_SYMBOL_GPL(system_freezable_wq);
而一般情况下,系统中通过schedule_work均是把work加入到system_wq中。从代码来看,系统中的workqueue根据使用情况可以分为两种:普通的workqueue和unbound workqueue。前者的worker一般是和CPU绑定的,系统会为每个CPU创建一个pwd,而针对后者,就不和单个CPU绑定,而是针对NUMA节点,创建pwd。
2.2 worker
worker是具体处理work的对象,系统把worker作为一种资源管理,提出了worker_pool的概念,一个worker必定会属于某个worker_pool,worker结构如下
struct worker { /* on idle list while idle, on busy hash table while busy */ union { struct list_head entry; /* L: while idle */ struct hlist_node hentry; /* L: while busy */ }; struct work_struct *current_work; /* L: work being processed */ work_func_t current_func; /* L: current_work's fn */ struct pool_workqueue *current_pwq; /* L: current_work's pwq */ bool desc_valid; /* ->desc is valid */ struct list_head scheduled; /* L: scheduled works */ /* 64 bytes boundary on 64bit, 32 on 32bit */ struct task_struct *task; /* I: worker task */ struct worker_pool *pool; /* I: the associated pool */ /* L: for rescuers */ unsigned long last_active; /* L: last active timestamp */ unsigned int flags; /* X: flags */ int id; /* I: worker id */ /* * Opaque string set with work_set_desc(). Printed out with task * dump for debugging - WARN, BUG, panic or sysrq. */ char desc[WORKER_DESC_LEN]; /* used only by rescuers to point to the target workqueue */ struct workqueue_struct *rescue_wq; /* I: the workqueue to rescue */ };
一个worker根据自身状态不同会处于不同的数据结构中,当worker没有任务要处理就是idle状态,处于worker_pool维护的链表中;当worker在处理任务,就处于worker_pool维护的hash表中。task字段指向该worker对象线程的task_struct结构。pool指向其隶属的worker_pool。而如果该worker是一个rescuer worker,最后一个字段指向其对应的workqueue。当worker在处理任务时,current_work指向正在处理的work,current_func是work的处理函数,current_pwd指向对应的pwq。worker的线程处理函数为worker_thread。
static int worker_thread(void *__worker) { struct worker *worker = __worker; struct worker_pool *pool = worker->pool; /* tell the scheduler that this is a workqueue worker */ worker->task->flags |= PF_WQ_WORKER; woke_up: spin_lock_irq(&pool->lock); /* am I supposed to die? */ if (unlikely(worker->flags & WORKER_DIE)) { spin_unlock_irq(&pool->lock); WARN_ON_ONCE(!list_empty(&worker->entry)); worker->task->flags &= ~PF_WQ_WORKER; return 0; } /*worker只有在执行任务时才是idle状态*/ worker_leave_idle(worker); recheck: /* no more worker necessary? */ if (!need_more_worker(pool)) goto sleep; /* do we need to manage? */ if (unlikely(!may_start_working(pool)) && manage_workers(worker)) goto recheck; /* * ->scheduled list can only be filled while a worker is * preparing to process a work or actually processing it. * Make sure nobody diddled with it while I was sleeping. */ WARN_ON_ONCE(!list_empty(&worker->scheduled)); /* * Finish PREP stage. We're guaranteed to have at least one idle * worker or that someone else has already assumed the manager * role. This is where @worker starts participating in concurrency * management if applicable and concurrency management is restored * after being rebound. See rebind_workers() for details. */ worker_clr_flags(worker, WORKER_PREP | WORKER_REBOUND); do { //从pool中摘下一个work_struct struct work_struct *work = list_first_entry(&pool->worklist, struct work_struct, entry); if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) { /* optimization path, not strictly necessary */ process_one_work(worker, work); if (unlikely(!list_empty(&worker->scheduled))) process_scheduled_works(worker); } else { move_linked_works(work, &worker->scheduled, NULL); process_scheduled_works(worker); } } while (keep_working(pool)); worker_set_flags(worker, WORKER_PREP, false); sleep: if (unlikely(need_to_manage_workers(pool)) && manage_workers(worker)) goto recheck; /* * pool->lock is held and there's no work to process and no need to * manage, sleep. Workers are woken up only while holding * pool->lock or from local cpu, so setting the current state * before releasing pool->lock is enough to prevent losing any * event. */ /*恢复idle状态*/ worker_enter_idle(worker); __set_current_state(TASK_INTERRUPTIBLE); spin_unlock_irq(&pool->lock); schedule(); goto woke_up; }
从该函数可以看出worker只有在处理任务时,才是idle状态。在执行任务前通过worker_leave_idle把worker从idle链表摘下并清除idle标志。然后会检查当前pool是否需要更多的worker,如果不需要则继续睡眠。怎么判断是否需要呢?这里有一个函数need_more_worker
static bool need_more_worker(struct worker_pool *pool) { /*如果工作者链表不为空且现在没有并发*/ return !list_empty(&pool->worklist) && __need_more_worker(pool); } static bool __need_more_worker(struct worker_pool *pool) { return !atomic_read(&pool->nr_running); }
针对unbound pool,只要存在work,那么该函数就返回true,因为unbound的pool并不计算nr_running。但是从这里看,针对普通的pool,只有在worklist不为空且没有正在运行的worker时才会返回true,那么怎么同时让多个worker同时运行呢??不解!如果确实需要则检查下是否需要管理worker,因为此时需要worker,所以需要判断下有没有idle的worker,如果没有则调用manage_workers进行管理,该函数中两个核心处理函数就是maybe_destroy_workers和maybe_create_worker。待检查过后,就开始具体的处理了,核心逻辑都在一个循环体中。
具体处理过程比较明确,先从pool的worklist中摘下一个work,如果该work没有设置WORK_STRUCT_LINKED标志,就直接调用process_one_work函数进行处理,如果worker->scheduled链表不为空,则调用process_scheduled_works对链表上的work进行处理;如果work设置了WORK_STRUCT_LINKED标志,则需要把work移动到worker的scheduled链表上,然后通过process_scheduled_works进行处理。而循环的条件是keep_working(pool),即只要worklist不为空且在运行的worker数目小于等于1(这里也不太明白,为何是小于等于1)。处理单个work的流程看process_one_work
该函数一个比较重要的验证就是判断当前work是否已经有别的worker在处理,如果存在则需要把work加入到对应worker的scheduled链表,以避免多个worker同时处理同一work;如果没问题就着手开始处理。具体处理过程比较简单,把worker加入到busy的hash表,然后设置worker的相关字段,主要是current_work、current_func和current_pwq。然后把work从链表中删除,之后就执行work的处理函数进行处理。当worker处理完成后,需要把worker从hash表中删除,并把相关字段设置默认值。
process_scheduled_works就比较简单,就是循环对worker中scheduled链表中的work执行处理,具体处理方式就是调用process_one_work。
2.3 worker_pool
顾名思义,worker_pool本身的重要任务就是管理worker,除此之外,worker_pool还管理用户提交的work。在worker_pool中有一个链表头idle_list,链接worker中的entry,对应于空闲的worker;而hash表busy_hash链接worker中的hentry,对应正在执行任务的worker。nr_workers和nr_idle代表worker和idle worker的数量。系统中worker_pool是一个perCPU变量,看下worker_pool的声明
static DEFINE_PER_CPU_SHARED_ALIGNED(struct worker_pool [NR_STD_WORKER_POOLS], cpu_worker_pools);
每个CPU对应有两个worker_pool,一个针对普通的workqueue,一个针对高优先级workqueue。而PWQ也是perCPU变量,即一个workqueue在每个CPU上都有对应的pwq,也就有对应的worker_pool。、
下篇文章介绍下workqueue的创建以及worker的管理。
以马内利
参考资料:
LInux内核3.10.1源码