In statistics and in statistical physics, Gibbs sampling or a Gibbs sampler is aMarkov chain Monte Carlo (MCMC) algorithm for obtaining a sequence of observations which are approximated from a specifiedmultivariate probability distribution (i.e. from the joint probability distribution of two or more random variables), when direct sampling is difficult. This sequence can be used to approximate the joint distribution (e.g., to generate a histogram of the distribution); to approximate themarginal distribution of one of the variables, or some subset of the variables (for example, the unknownparameters or latent variables); or to compute an integral (such as the expected value of one of the variables). Typically, some of the variables correspond to observations whose values are known, and hence do not need to be sampled.
Gibbs sampling is commonly used as a means ofstatistical inference, especially Bayesian inference. It is a randomized algorithm (i.e. an algorithm that makes use of random numbers, and hence may produce different results each time it is run), and is an alternative todeterministic algorithms for statistical inference such as variational Bayes or the expectation-maximization algorithm (EM).
As with other MCMC algorithms, Gibbs sampling generates aMarkov chain of samples, each of which is correlated with nearby samples. As a result, care must be taken if independent samples are desired (typically bythinning the resulting chain of samples by only taking every nth value, e.g. every 100th value). In addition (again, as in other MCMC algorithms), samples from the beginning of the chain (theburn-in period) may not accurately represent the desired distribution[citation needed].
Contents
Introduction
Gibbs sampling is named after the physicistJosiah Willard Gibbs, in reference to an analogy between the sampling algorithm and statistical physics. The algorithm was described by brothers Stuart and Donald Geman in 1984, some eight decades after the death of Gibbs.[1]
In its basic version, Gibbs sampling is a special case of theMetropolis–Hastings algorithm. However, in its extended versions (see below), it can be considered a general framework for sampling from a large set of variables by sampling each variable (or in some cases, each group of variables) in turn, and can incorporate theMetropolis–Hastings algorithm (or similar methods such as slice sampling) to implement one or more of the sampling steps.
Gibbs sampling is applicable when the joint distribution is not known explicitly or is difficult to sample from directly, but theconditional distribution of each variable is known and is easy (or at least, easier) to sample from. The Gibbs sampling algorithm generates an instance from the distribution of each variable in turn, conditional on the current values of the other variables. It can be shown (see, for example, Gelman et al. 1995) that the sequence of samples constitutes aMarkov chain, and the stationary distribution of that Markov chain is just the sought-after joint distribution.
Gibbs sampling is particularly well-adapted to sampling theposterior distribution of a Bayesian network, since Bayesian networks are typically specified as a collection of conditional distributions.
Implementation
Gibbs sampling, in its basic incarnation, is a special case of theMetropolis–Hastings
algorithm. The point of Gibbs sampling is that given a
multivariate distribution it is simpler to sample from a conditional distribution than tomarginalize by integrating over a
joint distribution. Suppose we want to obtain 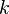 samples of
samples of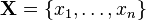 from a joint distribution
from a joint distribution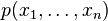 . Denote the
. Denote the th
sample by
th
sample by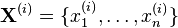 . We proceed as follows:
. We proceed as follows:
- We begin with some initial value
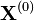 for each variable.
for each variable. - For each sample
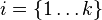 , sample each variable
, sample each variable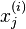 from the conditional distribution
from the conditional distribution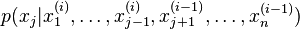 . That is, sample each variable from the distribution
of that variable conditioned on all other variables, making use of the most recent values and updating the variable with its new value as soon as it has been sampled.
. That is, sample each variable from the distribution
of that variable conditioned on all other variables, making use of the most recent values and updating the variable with its new value as soon as it has been sampled.
The samples then approximate the joint distribution of all variables. Furthermore, the marginal distribution of any subset of variables can be approximated by simply examining the samples for that subset of variables, ignoring the rest. In addition, the expected value of any variable can be approximated by averaging over all the samples.
- The initial values of the variables can be determined randomly or by some other algorithm such asexpectation-maximization.
- It is not actually necessary to determine an initial value for the first variable sampled.
- It is common to ignore some number of samples at the beginning (the so-calledburn-in period), and then consider only every
 th sample when averaging values to compute an expectation. For example, the first 1,000 samples might be ignored, and then every 100th sample averaged,
throwing away all the rest. The reason for this is that (1) successive samples are not independent of each other but form aMarkov chain with some amount
of correlation; (2) the
stationary distribution of the Markov chain is the desired joint distribution over the variables, but it may take a while for that stationary distribution to be reached. Sometimes, algorithms can be used to determine the amount ofautocorrelation
between samples and the value of (the period between samples that are actually used) computed from this, but in practice there is a fair amount of "black
magic" involved.
th sample when averaging values to compute an expectation. For example, the first 1,000 samples might be ignored, and then every 100th sample averaged,
throwing away all the rest. The reason for this is that (1) successive samples are not independent of each other but form aMarkov chain with some amount
of correlation; (2) the
stationary distribution of the Markov chain is the desired joint distribution over the variables, but it may take a while for that stationary distribution to be reached. Sometimes, algorithms can be used to determine the amount ofautocorrelation
between samples and the value of (the period between samples that are actually used) computed from this, but in practice there is a fair amount of "black
magic" involved. - The process of simulated annealing is often used to reduce the "random walk" behavior in the early part of the sampling process (i.e. the tendency to move slowly around the sample space, with a high amount of autocorrelation between samples, rather than moving around quickly, as is desired). Other techniques that may reduce autocorrelation arecollapsed Gibbs sampling, blocked Gibbs sampling, and ordered overrelaxation; see below.
Relation of conditional distribution and joint distribution
Furthermore, the conditional distribution of one variable given all others is proportional to the joint distribution:
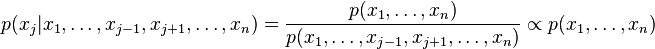
"Proportional to" in this case means that the denominator is not a function of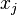 and thus
is the same for all values of; it forms part of thenormalization
constant for the distribution over . In practice, to determine the nature of the conditional distribution of a factor,
it is easiest to factor the joint distribution according to the individual conditional distributions defined by thegraphical model over the variables,
ignore all factors that are not functions of (all of which, together with the denominator above, constitute the normalization constant), and then reinstate
the normalization constant at the end, as necessary. In practice, this means doing one of three things:
and thus
is the same for all values of; it forms part of thenormalization
constant for the distribution over . In practice, to determine the nature of the conditional distribution of a factor,
it is easiest to factor the joint distribution according to the individual conditional distributions defined by thegraphical model over the variables,
ignore all factors that are not functions of (all of which, together with the denominator above, constitute the normalization constant), and then reinstate
the normalization constant at the end, as necessary. In practice, this means doing one of three things:
- If the distribution is discrete, the individual probabilities of all possible values of
are computed, and then summed to find the normalization constant.
- If the distribution is continuous and of a known form, the normalization constant will also be known.
- In other cases, the normalization constant can usually be ignored, as most sampling methods do not require it.
Inference
Gibbs sampling is commonly used forstatistical inference (e.g. determining the best value of a parameter, such as determining the number of people likely to shop at a particular store on a given day, the candidate a voter will most likely vote for, etc.). The idea is that observed data is incorporated into the sampling process by creating separate variables for each piece of observed data and fixing the variables in question to their observed values, rather than sampling from those variables. The distribution of the remaining variables is then effectively a posterior distribution conditioned on the observed data.
The most likely value of a desired parameter (themode) could then simply be selected by choosing the sample value that occurs most commonly; this is essentially equivalent tomaximum a posteriori estimation of a parameter. (Since the parameters are usually continuous, it is often necessary to "bin" the sampled values into one of a finite number of ranges or "bins" in order to get a meaningful estimate of the mode.) More commonly, however, the expected value (mean or average) of the sampled values is chosen; this is aBayes estimator that takes advantage of the additional data about the entire distribution that is available from Bayesian sampling, whereas a maximization algorithm such asexpectation maximization (EM) is capable of only returning a single point from the distribution. For example, for a unimodal distribution the mean (expected value) is usually similar to the mode (most common value), but if the distribution isskewed in one direction, the mean will be moved in that direction, which effectively accounts for the extra probability mass in that direction. (Note, however, that if a distribution is multimodal, the expected value may not return a meaningful point, and any of the modes is typically a better choice.)
Although some of the variables typically correspond to parameters of interest, others are uninteresting ("nuisance") variables introduced into the model to properly express the relationships among variables. Although the sampled values represent the joint distribution over all variables, the nuisance variables can simply be ignored when computing expected values or modes; this is equivalent tomarginalizing over the nuisance variables. When a value for multiple variables is desired, the expected value is simply computed over each variable separately. (When computing the mode, however, all variables must be considered together.)
Supervised learning,unsupervised learning and semi-supervised learning (aka learning with missing values) can all be handled by simply fixing the values of all variables whose values are known, and sampling from the remainder.
For observed data, there will be one variable for each observation — rather than, for example, one variable corresponding to thesample mean or sample variance of a set of observations. In fact, there generally will be no variables at all corresponding to concepts such as "sample mean" or "sample variance". Instead, in such a case there will be variables representing the unknown true mean and true variance, and the determination of sample values for these variables results automatically from the operation of the Gibbs sampler.
Generalized linear models (i.e. variations oflinear regression) can sometimes be handled by Gibbs sampling as well. For example,probit regression for determining the probability of a given binary (yes/no) choice, withnormally distributed priors placed over the regression coefficients, can be implemented with Gibbs sampling because it is possible to add additional variables and take advantage ofconjugacy. However, logistic regression cannot be handled this way. One possibility is to approximate thelogistic function with a mixture (typically 7-9) of normal distributions. More commonly, however,Metropolis-Hastings is used instead of Gibbs sampling.
Mathematical background
Suppose that a sample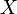 is taken from a distribution depending on a parameter
vector
is taken from a distribution depending on a parameter
vector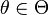 of length
of length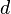 ,
with prior distribution
,
with prior distribution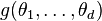 . It may be that
is very large and that numerical integration to find the marginal densities of the
. It may be that
is very large and that numerical integration to find the marginal densities of the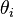 would be computationally expensive. Then an alternative
method of calculating the marginal densities is to create a Markov chain on the space
would be computationally expensive. Then an alternative
method of calculating the marginal densities is to create a Markov chain on the space
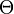 by repeating these two steps:
by repeating these two steps:
- Pick a random index
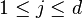
- Pick a new value for
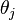 according to
according to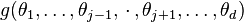
These steps define areversible Markov chain with the desired invariant distribution
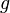 . This can be proved as follows. Define
. This can be proved as follows. Define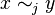 if
if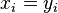 for all
for all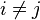 and
let
and
let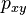 denote the probability of a jump from
denote the probability of a jump from to
to . Then, the transition probabilities are
. Then, the transition probabilities are

So

since is anequivalence
relation. Thus the
detailed balance equations are satisfied, implying the chain is reversible and it has invariant distribution.
In practice, the suffix is not chosen at random, and the chain cycles through
the suffixes in order. In general this gives a non-stationary Markov process, but each individual step will still be reversible, and the overall process will still have the desired stationary distribution (as long as the chain can access all states under the
fixed ordering).
is not chosen at random, and the chain cycles through
the suffixes in order. In general this gives a non-stationary Markov process, but each individual step will still be reversible, and the overall process will still have the desired stationary distribution (as long as the chain can access all states under the
fixed ordering).
Variations and extensions
Numerous variations of the basic Gibbs sampler exist. The goal of these variations is to reduce theautocorrelation between samples sufficiently to overcome any added computational costs.
Blocked Gibbs sampler
- A blocked Gibbs sampler groups two or more variables together and samples from theirjoint distribution conditioned on all other variables, rather than sampling from each one individually. For example, in ahidden Markov model, a blocked Gibbs sampler might sample from all the latent variables making up the Markov chain in one go, using the forward-backward algorithm.
Collapsed Gibbs sampler
- A collapsed Gibbs sampler integrates out (marginalizes over) one or more variables when sampling for some other variable. For example, imagine that a model consists of three variablesA, B, and C. A simple Gibbs sampler would sample from p(A|B,C), then p(B|A,C), thenp(C|A,B). A collapsed Gibbs sampler might replace the sampling step forA with a sample taken from the marginal distribution p(A|C), with variableB integrated out in this case. Alternatively, variable B could be collapsed out entirely, alternately sampling fromp(A|C) and p(C|A) and not sampling overB at all. The distribution over a variable A that arises when collapsing a parent variableB is called a compound distribution; sampling from this distribution is generally tractable whenB is the conjugate prior for A, particularly when A and B are members of theexponential family. For more information, see the article on compound distributions or Liu (1994).[2]
Implementing a collapsed Gibbs sampler
Collapsing Dirichlet distributions
In hierarchical Bayesian models with categorical variables, such as latent Dirichlet allocation and various other models used in natural language processing, it is quite common to collapse out the Dirichlet distributions that are typically used as prior distributions over the categorical variables. The result of this collapsing introduces dependencies among all the categorical variables dependent on a given Dirichlet prior, and the joint distribution of these variables after collapsing is aDirichlet-multinomial distribution. The conditional distribution of a given categorical variable in this distribution, conditioned on the others, assumes an extremely simple form that makes Gibbs sampling even easier than if the collapsing had not been done. The rules are as follows:
- Collapsing out a Dirichlet prior node affects only the parent and children nodes of the prior. Since the parent is often a constant, it is typically only the children that we need to worry about.
- Collapsing out a Dirichlet prior introduces dependencies among all the categorical children dependent on that prior — butno extra dependencies among any other categorical children. (This is important to keep in mind, for example, when there are multiple Dirichlet priors related by the same hyperprior. Each Dirichlet prior can be independently collapsed and affects only its direct children.)
- After collapsing, the conditional distribution of one dependent children on the others assumes a very simple form: The probability of seeing a given value is proportional to the sum of the corresponding hyperprior for this value, and the count of all of the other dependent nodes assuming the same value. Nodes not dependent on the same priormust not be counted. Note that the same rule applies in other iterative inference methods, such asvariational Bayes or expectation maximization; however, if the method involves keeping partial counts, then the partial counts for the value in question must be summed across all the other dependent nodes. Sometimes this summed up partial count is termed theexpected count or similar. Note also that the probability is proportional to the resulting value; the actual probability must be determined by normalizing across all the possible values that the categorical variable can take (i.e. adding up the computed result for each possible value of the categorical variable, and dividing all the computed results by this sum).
- If a given categorical node has dependent children (e.g. when it is alatent variable in a mixture model), the value computed in the previous step (expected count plus prior, or whatever is computed) must be multiplied by the actual conditional probabilities (not a computed value that is proportional to the probability!) of all children given their parents. See the article on the Dirichlet-multinomial distribution for a detailed discussion.
- In the case where the group membership of the nodes dependent on a given Dirichlet prior may change dynamically depending on some other variable (e.g. a categorical variable indexed by another latent categorical variable, as in a topic model), the same expected counts are still computed, but need to be done carefully so that the correct set of variables is included. See the article on theDirichlet-multinomial distribution for more discussion, including in the context of a topic model.
Collapsing other conjugate priors
In general, any conjugate prior can be collapsed out, if its only children have distributions conjugate to it. The relevant math is discussed in the article oncompound distributions. If there is only one child node, the result will often assume a known distribution. For example, collapsing aninverse-gamma-distributed variance out of a network with a single Gaussian child will yield a Student's t-distribution. (For that matter, collapsing both the mean and variance of a single Gaussian child will still yield a Student's t-distribution, provided both are conjugate, i.e. Gaussian mean, inverse-gamma variance.)
If there are multiple child nodes, they will all become dependent, as in theDirichlet-categorical case. The resultingjoint distribution will have a closed form that resembles in some ways the compound distribution, although it will have a product of a number of factors, one for each child node, in it.
In addition, and most importantly, the resultingconditional distribution of one of the child nodes given the others (and also given the parents of the collapsed node(s), butnot given the children of the child nodes) will have the same density as theposterior predictive distribution of all the remaining child nodes. Furthermore, the posterior predictive distribution has the same density as the basic compound distribution of a single node, although with different parameters. The general formula is given in the article on compound distributions.
For example, given a Bayes network with a set of conditionallyindependent identically distributed Gaussian-distributed nodes with conjugate prior distributions placed on the mean and variance, the conditional distribution of one node given the others after compounding out both the mean and variance will be aStudent's t-distribution. Similarly, the result of compounding out the gamma prior of a number of Poisson-distributed nodes causes the conditional distribution of one node given the others to assume anegative binomial distribution.
In these cases where compounding produces a well-known distribution, efficient sampling procedures often exist, and using them will often (although not necessarily) be more efficient than not collapsing, and instead sampling both prior and child nodes separately. However, in the case where the compound distribution is not well-known, it may not be easy to sample from, since it generally will not belong to theexponential family and typically will not be log-concave (which would make it easy to sample using adaptive rejection sampling, since a closed form always exists).
In the case where the child nodes of the collapsed nodes themselves have children, the conditional distribution of one of these child nodes given all other nodes in the graph will have to take into account the distribution of these second-level children. In particular, the resulting conditional distribution will be proportional to a product of the compound distribution as defined above, and the conditional distributions of all of the child nodes given their parents (but not given their own children). This follows from the fact that the full conditional distribution is proportional to the joint distribution. If the child nodes of the collapsed nodes arecontinuous, this distribution will generally not be of a known form, and may well be difficult to sample from despite the fact that a closed form can be written, for the same reasons as described above for non-well-known compound distributions. However, in the particular case that the child nodes are discrete, sampling is feasible, regardless of whether the children of these child nodes are continuous or discrete. In fact, the principle involved here is described in fair detail in the article on theDirichlet-multinomial distribution.