冒泡排序 :Bubble Sort
时间复杂度 : O(N*N)
说明: 将待排序的元素看作是竖着排列的“气泡”,较小的元素比较轻,从而要往上浮
import random
a = []
for i in range(40):
a.append(random.randrange(1,20))
for i in range(len(a) - 1):
for j in range(len(a) - i - 1):
if a[j] > a[j + 1]:
a[j], a[j + 1] = a[j + 1], a[j]
print(a)
插入排序 :Insertion sort
时间复杂度 : O(N*N)
说明: 逐一取出元素,在已经排序的元素序列中从后向前扫描,放到适当的位置
data_set = [ 9,1,22,31,45,3,6,2,11 ]
smallest_num_index = 0 #初始列表最小值,默认为第一个
loop_count = 0
for j in range(len(data_set)):
for i in range(j,len(data_set)):
if data_set[i] < data_set[smallest_num_index]: #当前值 比之前选出来的最小值 还要小,那就把它换成最小值
smallest_num_index = i
loop_count +=1
else:
print("smallest num is ",data_set[smallest_num_index])
tmp = data_set[smallest_num_index]
data_set[smallest_num_index] = data_set[j]
data_set[j] = tmp
print(data_set)
print("loop times", loop_count)
选择排序
时间复杂度 : O(N*N)
说明: 首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。以此递归。
data_set = [ 9,1,22,31,45,3,6,2,11 ]
smallest_num_index = 0 #初始列表最小值,默认为第一个
loop_count = 0
for j in range(len(data_set)):
for i in range(j,len(data_set)):
if data_set[i] < data_set[smallest_num_index]: #当前值 比之前选出来的最小值 还要小,那就把它换成最小值
smallest_num_index = i
loop_count +=1
else:
print("smallest num is ",data_set[smallest_num_index])
tmp = data_set[smallest_num_index]
data_set[smallest_num_index] = data_set[j]
data_set[j] = tmp
print(data_set)
print("loop times", loop_count)
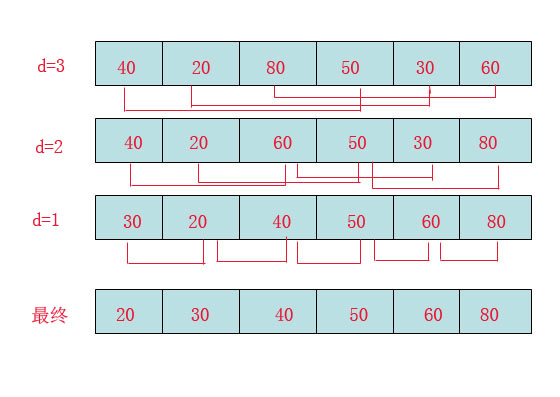
希尔排序:
时间复杂度:O(n1+£) 0<£<1
说明:选择一个步长(Step) ,然后按间隔为步长的单元进行排序.递归,步长逐渐变小,直至为1.
import random
a = []
for i in range(10000):
a.append(random.randrange(1,1000))
# 希尔运算 整理用的,把大概的顺序 整理好
################################################
b = int(len(a)/2)
while b >= 1:
for i in range(len(a) - b):
if a[i] > a[i + b]:
a[i], a[i + b] = a[i + b], a[i]
b = int(b/2)
################################################
f = 0
# 下面 while 循环 排序的时候 因为希尔运算做过整理,很多时候只判断下就可以了,
################################################
for i in range(len(a)):
while i > 0 and a[i-1]>a[i]:
a[i - 1], a[i] = a[i], a[i - 1]
i -= 1
f+=1 #24966238 大约循环次数------希尔不给整理
#3765358 大约循环次数------希尔整理后
################################################
print(f)
#####################################################################
#堆排序
#儿子找父亲
a = []
for i in range(100):
a.append(random.randrange(100))
lens = len(a)
#总长度除以 2 减 1 就是他父亲索引
parent = int(lens/2-1)
for ii in range(lens-1):
last = 0
# 缩短循环长度
for i in range(lens-1-ii):
#循环完剩下的长度
last = i+1
# 打印循环长度
# print(a[0:i])
#找到父亲的索引位置 减ii是找到缩短长度的 父亲索引
parent = int((lens-i- ii ) / 2 -1)
#判断自己的索引位置是否大于父亲的索引 然后替换
if a[lens - i - 1-ii] > a[parent]:
a[lens - i - 1 - ii],a[parent] = a[parent],a[lens - i - 1-ii ]
#交换最大元素 把最大的元素衣服往后面排放lens-ii-1
a[0],a[last] = a[last],a[0]
print(a)
print(last)
#####################################################################
#堆排序 从父亲找儿子
dataset = [random.randrange(50) for i in range(20)]
# 从大往小循环 list 的长度
for i in range(len(dataset)-1,0,-1):
print(i)
#每次循环 把最大的值放到最前面
for index in range(int((i+1)/2),0,-1):
p_index = index
l_child_index = p_index *2 - 1
r_child_index = p_index *2
p_node = dataset[p_index-1]
left_child = dataset[l_child_index]
#如果 left chil 大于 parent
if p_node < left_child:
dataset[p_index - 1], dataset[l_child_index] = left_child, p_node
p_node = dataset[p_index - 1]
#如果 right chil 索引 大于 循环 list len
if r_child_index < len(dataset[0:i+1]):
right_child = dataset[r_child_index]
if p_node < right_child:
dataset[p_index - 1] , dataset[r_child_index] = right_child,p_node
p_node = dataset[p_index - 1]
#把list 的第一个值 放到最后
dataset[0],dataset[i] = dataset[i],dataset[0]
print(dataset)
#快排
#最快的排序
def quick_sort(array, left, right):
if left >= right:
return
low = left
high = right
key = array[low] # 第一个值
while low < high: # 只要左右未遇见
while low < high and array[high] > key: # 找到列表右边比key大的值 为止
high -= 1
# 此时直接 把key(array[low]) 跟 比它大的array[high]进行交换
array[low] = array[high]
array[high] = key
while low < high and array[low] <= key: # 找到key左边比key大的值,这里为何是<=而不是<呢?你要思考。。。
low += 1
# array[low] =
# 找到了左边比k大的值 ,把array[high](此时应该刚存成了key) 跟这个比key大的array[low]进行调换
array[high] = array[low]
array[low] = key
quick_sort(array, left, low - 1) # 最后用同样的方式对分出来的左边的小组进行同上的做法
quick_sort(array, low + 1, right) # 用同样的方式对分出来的右边的小组进行同上的做法
if __name__ == '__main__':
array = [random.randrange(10000) for i in range(10000)]
quick_sort(array, 0, len(array) - 1)
print("-------final -------")
print(array)
#二分算法
#!/usr/bin/python3.4
# -*- coding: utf-8 -*-
#PS: 最小值0 最大值10 k为 7
# 中间值 5 < k7
# 最小值 5+1 + 最大值 10 = 中间值 8
# 中间值 k7 < 8
# 最小值 6 + 最大值 8-1 = 中间值 6
# 中间值 6 < k7
# 最小值 6+1 最大值 7 = 中间值 7
# 中间值 7 == k7
def BinarySearch(arr, key):
#最小值
mins = 0
#最大值
maxs = len(arr) - 1
if key in arr:
# 建立一个死循环,直到找到key
i = 0
while True:
#得到每次查找次数
i += 1
#得到中间值
center = int((mins + maxs) / 2)
#如果key 小于 中间值 那么最大值就等于 中间值 的下一位 最小值不变 #为什么最小值 不变呢,因为有可能等于最小值
if key < arr[center]:
maxs = center - 1
#如果key 大于 中间值 那么最小值就等于中间值的 上一位, 最大值不变 #为什么最大值 不变呢,因为有可能等于最大值
elif arr[center] < key:
mins = center + 1
# key在数组中间
elif arr[center] == key:
print(str(key) + "在数组里面的第" + str(center) + "个位置" + '----%s'%i)
return arr[center]
else:
print("没有该数字!")
if __name__ == "__main__":
arr = []
for i in range(10000000):
arr.append(i)
while True:
key = input("请输入你要查找的数字:")
if key == " ":
print("谢谢使用!")
break
else:
BinarySearch(arr, int(key))
#后序遍历
class Tree(object):
def __init__(self,data=None,left=None,right=None):
self.data = data
self.left = left
self.right = right
class Btree(object):
def __init__(self,root):
self.root = root
#前序遍历 根节点 > 左子树 > 右子树
def perOrder(self,node):
print(node.data)
if type(node.left) == type(""):
print(node.left)
elif node.left is None:
pass
elif type(node.left) == type(self.root):
self.perOrder(node.left)
if type(node.right) == type(""):
print(node.right)
elif node.right is None:
pass
elif type(node.right) == type(self.root):
self.perOrder(node.right)
return
#中序遍历 左子树 > 根节点 > 右子树
def perIrder(self, node):
#如果左子树 是字符串类型 就打印
if type(node.left) == type(""):
print(node.left)
#如果左子树是空 什么都不干
elif node.left is None:
pass
#如果是对象 那么就进入
elif type(node.left) == type(self.root):
self.perIrder(node.left)
print(node.data)
if type(node.right) == type(""):
print(node.right)
elif node.right is None:
pass
elif type(node.right) == type(self.root):
self.perIrder(node.right)
#最后返回
return
#后序遍历 左子树 > 右子树 > 根节点
def perBrder(self, node):
if type(node.left) == type(""):
print(node.left)
elif node.left is None:
pass
elif type(node.left) == type(self.root):
self.perBrder(node.left)
if type(node.right) == type(""):
print(node.right)
elif node.right is None:
pass
elif type(node.right) == type(self.root):
self.perBrder(node.right)
print(node.data)
return
n1 = Tree('n1','n1-left','n1-right')
n2 = Tree('n2',n1,'n2-right')
n3 = Tree('n3','n3-left',n2)
n4 = Tree('n4','n4-left','n4-right')
n5 = Tree('n5',n4,n3)
n6 = Tree('n6','n6-left',n5)
n7 = Tree('n7',n6,'n7-right')
n8 = Tree('n8',)
n9 = Tree('root',n7,n8)
obj = Btree(n9)
obj.perBrder(obj.root)