多目标进化算法的性能指标总结 (一)
觉得有用的话,欢迎一起讨论相互学习~




转载自:
https://blog.csdn.net/qq_40458671/article/details/88601195
注:此次总结的只是多目标性能评价指标中很少的一部分。
一、指标的常见分类方法:
1.考虑指标同时能评估的解集数目(1个或2个解集),可将指标分为一元和二元指标。
一元指标:接受一个解集作为参数进行评估。
二元指标:接受两个解集作为参数,通过比较两个解集的支配关系或其他方面,给出哪个解集更好的判断。
2.多目标进化算法解集的性能评价指标主要分为三个方面:
1)解集的收敛性评价(convergence), 反映解集与真实Pareto前沿之间的逼近程度(距离)。一般我们希望所得解集距离PF尽可能近。
2)解集的均匀性评价(uniformity / evenness), 体现解集中个体分布的均匀程度。一般我们希望所得解集在PF上分布尽可能均匀。
3)解集的广泛性评价(spread), 反映整个解集在目标空间中分布的广泛程度。一般我们希望所得解集在PF上分布尽可能广、尽可能完整地表达PF。
也有一些学者,不这样分类,分为基数指标,收敛性指标,和多样性/分布性指标,认为多样性包括均匀性(evenness)和广泛性/范围(spread),具体如下:
1)基数指标:评估解集中存在的解的个数。
2)收敛性指标(精确度指标):评估解集到理论帕累托最优前沿的距离(逼近程度)。
3)多样性指标:包括评估解集分布的均匀性(evenness)和广泛性/范围(spread)。均匀性体现解集中个体分布的均匀程度;广泛性反映整个解集在目标空间中分布的广泛程度。
二、常用性能评价指标回顾
1.GD:解集P中的每个点到参考集P *中的平均最小距离表示。GD值越小,表示收敛性越好。

其中P是算法求得的解集,P _是从PF上采样的一组均匀分布的参考点,而dis(x,y)表示解集P中的点y和参考集P_中的点x之间的欧式距离。
优点:相比HV,计算代价是轻量级的。
缺点:1)仅度量解集的收敛性,无法评估多样性;
2)需要参考集,使得这个测度很容易不客观;
2.convergence metric γ:解集P中的每个点到参考集P *中的最小距离的平均值。(类似GD)
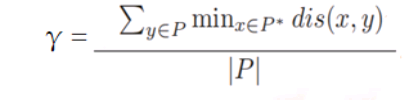
其中P是算法求得的解集,P _是从PF上采样的均匀分布的参考点集,而dis(x,y)表示参考集P_中的点x和解集P中的点y之间的欧式距离。
3.Spacing:度量每个解到其他解的最小距离的标准差。Spacing值越小,说明解集越均匀。
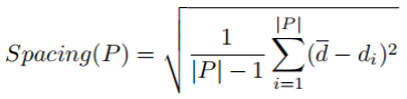
其中表示第di个解到P中其他解的最小距离,d-表示所有di的均值。
缺点:仅度量解集的均匀性,而不考虑它的广泛性。
4. diversity metric △:衡量所获得的解集的广泛程度。
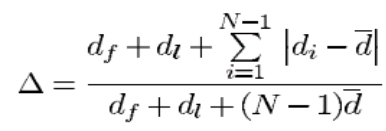
参数df和dl是极端解与所获得的非支配集的边界解之间的欧几里德距;di 是所获得的非支配解集中的连续解之间的欧几里德距离;
d是di 的平均值。
假设最佳非支配前沿有N个解。使用N个解,有N-1个连续距离。当只有一个解,即N=1时,分母=分子。值得注意的是,这不是解可能的最坏情况。我们可以有一个场景,其中di 存在很大的差异。在这种情况下,度量可能大于1。因此,上述度量的最大值可以大于1.然而,良好的分布将使所有距离di 等于d并且将使得df=dl = 0(在非支配集合中存在极端解)。因此,对于最广泛和均匀展开的非支配解集,△的分子将为零,使得度量值为零。对于任何其他分布,度量的值将大于零。
对于具有相同df和dl值的两个分布,度量△在极端解中具有更高的值和更差的解的分布。
5.超体积指标(HV,Hypervolume):算法获得的非支配解集与参照点围成的目标空间中区域的体积。HV值越大,说明算法的综合性能越好。
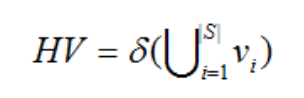
代表δ表示 Lebesgue 测度,用来测量体积。 |S| 表示非支配解集的数目, vi表示参照点与解集中第 i 个解构成的超体积。
优点:1)同时评价收敛性和多样性;
2)无需知道PF或参考集;
缺点:1)计算复杂度高,尤其是高维多目标优化问题;
2)参考点的选择在一定程度上决定超体积指标值的准确性;
6.反转世代距离(IGD,Inverted Generational Distance):每个参考点到最近的解的距离的平均值。IGD值越小,说明算法综合性能越好。
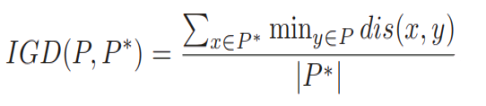
其中P是算法求得的解集,P _是从PF上采样的一组均匀分布的参考点,而dis(x,y)表示参考集P_中的点x到解集P中的点y之间的欧式距离。
优点:1)可同时评价收敛性和多样性;
2)计算代价小;
缺点:2)需要参考集;
7.C-metric解集覆盖率:
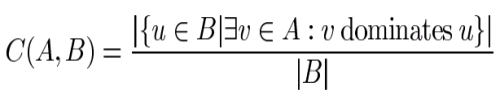
分子表示B中被A中至少一个解支配的解的数目;分母表示B中包含的解的总数。
C(A,B)=1表示B中所有解都被A中的一些解所支配;C(A,B)=0表示B中没有解被A中的任一解所支配。
8.IGD-NS 注:为什么要识别非贡献解呢?因为非贡献解影响收敛
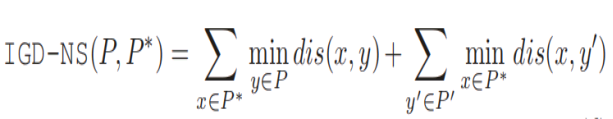
P_是PF上均匀采样的参考点集,P是算法获得的解集,P’是P中的非贡献解集。
公式的前一部分和IGD很相似,控制P的收敛性和多样性;
第二部分是每个非贡献解到参考集P_的点的最小距离之和。
因此,IGD-NS值越小,说明收敛和多样性越好,且解集的非贡献解尽可能少。
9.KD:衡量是否每个解集都至少包含一个与拐点相近的解或该解集是否包括全部拐点。
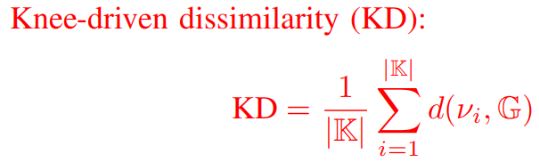
其中d(vi,G)是K中的第i个真实拐点vi到G中最接近解之间的欧几里得距离。
KD值越小,说明检测拐点的能力越完整;
当所获的解集覆盖到所有的拐点时,KD=0。
三、参考集的缺陷:
不少指标在计算时都需要参考集,因为有参考集的存在,指标的客观型就值得怀疑,如下图所示。

解集B肯定比A要好,可是因为选用了图中的参考集。而且,绝大多数实际问题都没参考集。
四、支配关系的缺陷:
在高维多目标里,很多解集或解都相互不支配,这时候支配关系这种东西就很鸡肋了。