[DeeplearningAI笔记]第二章1.1-1.3偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
觉得有用的话,欢迎一起讨论相互学习~




1.1 训练/开发/测试集
-
对于一个数据集而言,可以将一个数据集分为三个部分,一部分作为训练集,一部分作为简单交叉验证集(dev)有时候也成为验证集,最后一部分作为测试集(test).接下来我们开始对训练集执行训练算法,通过验证集或简单交叉验证集选择最好的模型.经过验证我们选择最终的模型,然后就可以在测试集上进行评估了.在机器学习的小数据量时代常见的做法是将所有数据三七分,就是人们常说的70%训练集集,30%测试集,如果设置有验证集,我们可以使用60%训练,20%验证和20%测试集来划分整个数据集.这是前几年机器学习领域公认的最好的测试与训练方式,如果我们只有100条/1000条/1W条数据,我们按照上面的比例进行划分是非常合理的,但是在大数据时代,我们现在的数据量可能是百万级,那么验证集和测试集占数据总量的比例会趋向变得更小.因为验证集的目的就是验证不同的算法检验那种算法更加有效,在大数据时代我们可能不需要拿出20%的数据作为验证集.比如我们有100W,那我们取1W条数据便足以找出其中表现最好的1-2种算法.同样地,根据最终选择的分类器,测试集的主要目的是正确评估分类器的性能.所以,如果拥有百万级数据我们只需要1000条数据,便足以评估单个分类器.准确评估分类器的性能。
-
假设我们有100W条数据,其中1W条做验证集,1W条做测试集,训练集占98%,验证集和测试集各占1%.对于数据量过百万级别的数据我们可以使测试集占0.5%,验证集占0.5%或者更少.测试集占0.4%,验证集占0.1%.
经验之谈:要确保验证集和测试集的数据来自同一分布.
- 最后一点,就算没有测试集也不要紧,测试集的目的是对最终选定的神经网络系统做出无偏评估,如果不需要无偏评估也可以不设置测试集所以如果只有验证集没有测试集.我们要做的就是在训练集上训练尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型.因为验证集已经包含有测试集的数据,故不在提供无偏性能评估.当然,如果你不需要无偏评估,那就再好不过了.在机器学习如果只有训练集和验证集但是没有独立的测试集,这种情况下,训练集还是训练集,而验证集则被称为测试集.不过在实际应用中,人们只是把测试集当做简单交叉验证集使用,并没有完全实现该术语的功能.因为他们把验证集数据过度拟合到了测试集中.如果某团队跟你说他们只设置了一个训练集和一个测试集我会很谨慎,心想他们是不是真的有训练验证集.因为他们把验证集数据过渡拟合到了测试集中.让这些团队改变叫法,改称其为"训练验证集".
1.2 偏差/方差
- 偏差(Bias)方差(Variance)这两个概念易学难精,在深度学习的领域对偏差 方差的权衡研究甚浅.但是深度学习的却很少权衡的考虑这两个概念,都是分别得考虑偏差和方差.
欠拟合
-
"欠拟合(underfitting)"当数据不能够很好的拟合数据时,有较大的误差.
-
以下面这个逻辑回归拟合的例子而言:
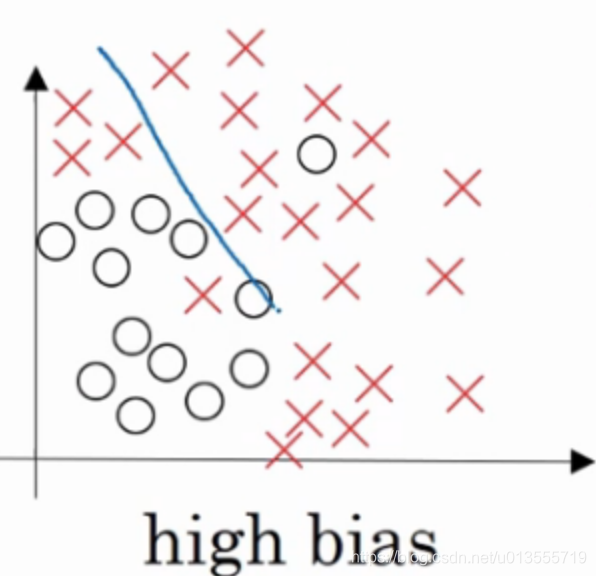
- 这就是high bias的情况.
过拟合
- "过拟合(overfitting)"如果我们拟合一个非常复杂的分类器,比如深度神经网络或者含有隐藏神经的神经网络,可能就非常适用于这个数据集,但是这看起来不是一种很好的拟合方式,分类器方差较高,数据过度拟合
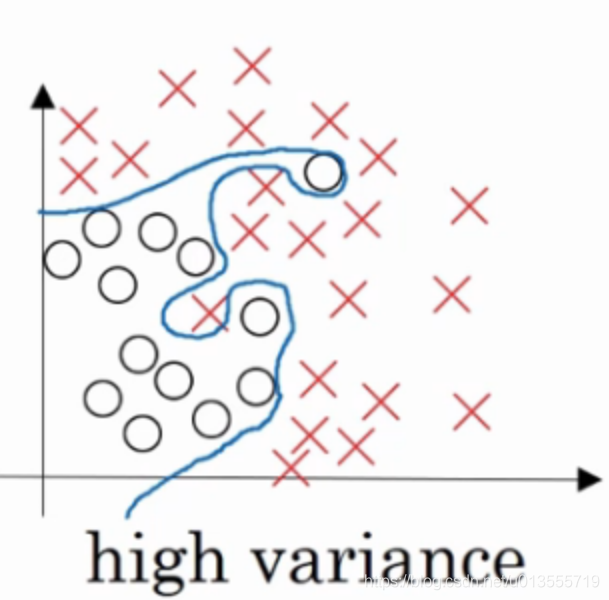
适度拟合
- 复杂程度适中,数据拟合适度的分类器,数据拟合程度相对合理,我们称之为"适度拟合"是介于过拟合和欠拟合中间的一类.
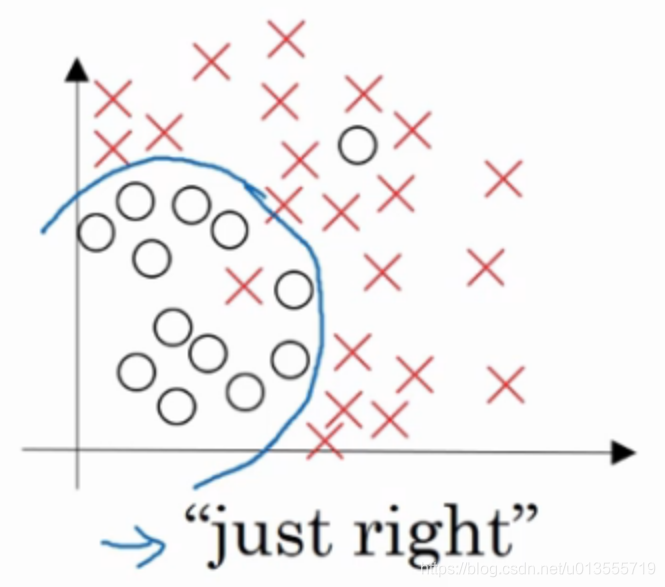
- 在这样一个只有x1和x2两个特征的二维数据集中,我们可以绘制数据,将偏差和方差可视化.但是在高维空间数据中,会直属局和可视化分割边界无法实现.但我们可以通过几个指标来研究偏差和方差.
高方差高偏差
- 高偏差指的是无法很好的拟合数据,高偏差指的是数据拟合灵活性过高,曲线过于灵活但是还包含有过度拟合的错误数据.
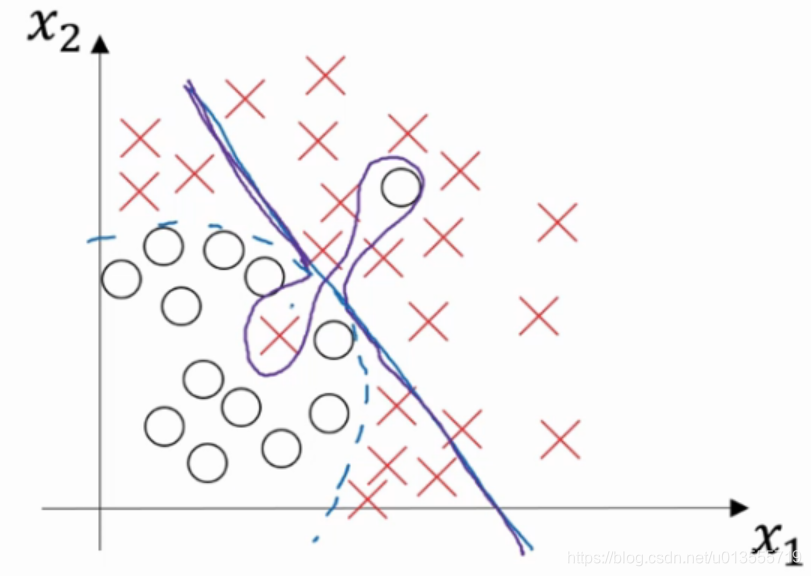
通过验证集/训练集判断拟合
"过拟合":训练集中错误率很低,但是验证集中错误率比验证集中高很多.方差很大.
"欠拟合":训练集中错误率相对比较高,但是验证集的错误率和训练集中错误率差别不大.偏差很大.
偏差和方差都很大: 如果训练集得到的错误率较大,表示不能很好的拟合数据,同时验证集上的错误率甚至更高,表示不能很好的验证算法.这是偏差和方差都很大的情况.
较好的情况: 训练集和验证集上的错误率都很低,并且验证集上的错误率和训练集上的错误率十分接近.

以上分析的前提都是假设基本误差很小,训练集和验证集数据来自相同分布,如果没有这些前提,分析结果会更加的复杂.
1.3 参数调节基本方法
-
初始训练完成后,首先看算法的偏差高不高,如果偏差过高,试着评估训练集或训练数据的性能.如果偏差真的很大,甚至无法拟合数据,现在就要选择一个新的网络.比如有更多隐层或者隐藏单元的网络.或者花费更多时间训练算法或者尝试更先进的优化算法.(ps:一般来讲,采用规模更大的网络通常会有帮助,延长训练时间不一定有用,但是也没有坏处,训练学习算法时,会不断尝试这些方法,知道解决掉偏差问题,这是最低标准,通常如果网络足够大,一般可以很好的拟合训练集)
-
一旦训练集上的偏差降低到一定的水平,可以检查一下方差有没有问题.为了评估方差我们要查看验证集性能.如果验证集和训练集的错误率误差较大即方差较大,最好的方法是采用更多数据.如果不能收集到更多的数据,我们可以采用正则化来减少过拟合.
-
我们需要选择正确的方法,不断迭代改进,如果是偏差本身比较大,准备更多的训练数据也没有什么用,所以一定要看清是哪方面出了问题.一般来讲选择正确的方法,使用更大更深的网络,更多的数据可以得到很好的效果