Kinesis Data Streams 高级别架构
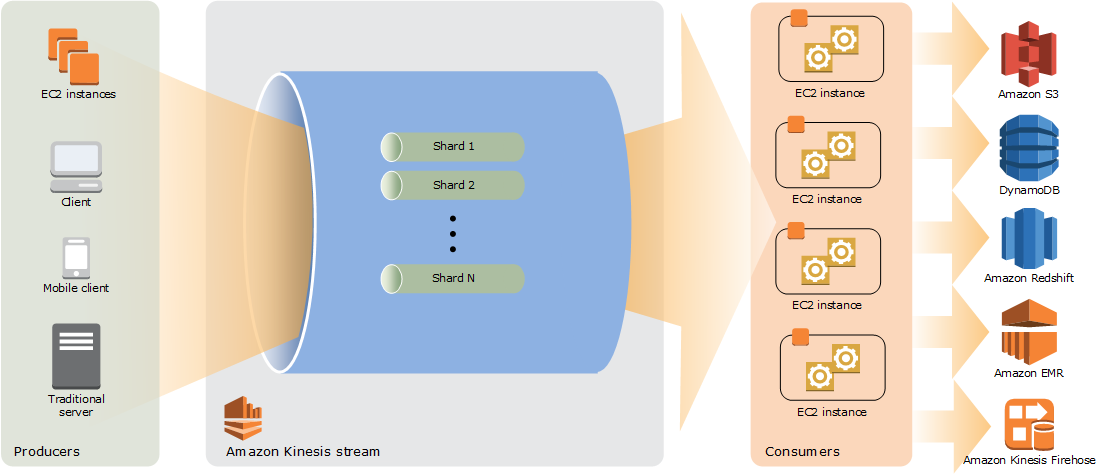
下图演示 Kinesis Data Streams 的高级别架构。创建器会持续将数据推送到 Kinesis Data Streams,并且使用者 可实时处理数据。使用者(如在 Amazon EC2 上运行的自定义应用程序或 Amazon Kinesis Data Firehose 传输流)可以使用 Amazon DynamoDB、Amazon Redshift 或 Amazon S3 等 AWS 服务存储其结果。
Kinesis Data Streams 术语
Kinesis Data Stream
Kinesis data stream 是一组分片。每个分片都有一系列数据记录。每个数据记录都具有一个由 Kinesis Data Streams 分配的序列号。
数据记录
数据记录 是存储在 Kinesis data stream中的数据单位。数据记录由序列号、分区键和数据 Blob 组成,后者是不可变的字节序列。Kinesis Data Streams 不以任何方式检查、解释或更改 Blob 中的数据。数据 Blob 可以是 最多 1 MB。
保留周期
保留期 是数据记录在添加到流中后可供访问的时间长度。在创建之后,流的保留期设置为默认值 24 小时。您可以使用 IncreaseStreamRetentionPeriod 操作将保留期增加到最高 168 小时(7 天),使用 DecreaseStreamRetentionPeriod 操作可将保留期减少到最短 24 小时。对于保留期设置为 24 小时以上的流,将收取额外费用。有关更多信息,请参阅Amazon Kinesis Data Streams 定价。
创建者
创建器将记录放入 Amazon Kinesis Data Streams 中。例如,发送日志数据到流的 Web 服务器是创建器。
使用者
使用者 从 Amazon Kinesis Data Streams 获取记录并进行处理。这些使用者称为 Amazon Kinesis Data Streams Application。
Amazon Kinesis Data Streams Application
Amazon Kinesis Data Streams application 是通常在 EC2 实例队列上运行的流的使用者。
可以开发的使用者有两种:共享扇出功能使用者和增强型扇出功能使用者。要了解它们之间的区别,以及了解如何创建每种使用者,请参阅读取 Amazon Kinesis Data Streams 中的数据。
Kinesis Data Streams 应用程序的输出可能是另一个流的输入,这使您能够创建实时处理数据的复杂拓扑。应用程序也可将数据发送到各种其他 AWS 服务。一个流可以有多个应用程序,每个应用程序可同时单独使用流中的数据。
分区
分片 是流中数据记录的唯一标识序列。一个流由一个或多个分片组成,每个分片提供一个固定的容量单位。每个分片均可支持 最多 每秒 5 次交易 可用于读取,最多可达的最大总数据读取速率为 每秒 2 MB 和 最多 每秒 1000 条记录 可用于写入,最多可达的最大总数据写入速率为 每秒 1 MB (包括分区键)。流的数据容量是您为流指定的分片数的函数。流的总容量是其分片容量的总和。
如果数据速率增加,您可以增加或减少分配给流的分片数量。
分区键
分区键 用于按分片对流中的数据进行分组。Kinesis Data Streams 将属于一个流的数据记录隔离到多个分片中。它使用与每个数据记录关联的分区键确定指定数据记录属于哪个分片。分区键是最大长度限制为 256 个字节的 Unicode 字符串。MD5 哈希函数用于将分区键映射到 128 位整数值并将关联的数据记录映射到分片。当应用程序将数据放入流中时,它必须指定一个分区键。
序列号
每个数据记录都有一个序列号,此序列号对于其分片中的每个密钥是唯一的。在您使用 client.putRecords 或 client.putRecord 写入流之后,Kinesis Data Streams 将分配序列号。同一分区键的序列号通常会随时间推移增加。写入请求之间的时间段越长,序列号越大。
注意
序列号不能用作相同流中的数据集的索引。为了在逻辑上分隔数据集,请使用分区键或者为每个数据集创建单独的流。
Kinesis Client Library
Kinesis Client Library 将编译成应用程序,从而支持以容错方式使用流中的数据。Kinesis Client Library 确保每个分片有一个用于运行和处理它的记录处理器。库还可以简化流中的数据读取。Kinesis Client Library 使用 Amazon DynamoDB 表存储控制数据。它会为每个正在处理数据的应用程序创建一个表。
Kinesis Client Library 有两个主要版本。使用哪个版本取决于要创建的使用者的类型。有关更多信息,请参阅 读取 Amazon Kinesis Data Streams 中的数据。
应用程序名称
Amazon Kinesis Data Streams application 的名称标识应用程序。每个应用程序必须具有一个唯一名称,此名称的范围限定于应用程序使用的 AWS 账户和区域。此名称用作 Amazon DynamoDB 中的控制表名称和 Amazon CloudWatch 指标的命名空间。
服务器端加密
当创建器将敏感数据输入流时,Amazon Kinesis Data Streams 可以自动加密这些数据。Kinesis Data Streams 使用 AWS KMS 主密钥进行加密。有关更多信息,请参阅Amazon Kinesis Data Streams 中的数据保护。