想要拥有不平凡的人生,请先拿出不平凡的努力。
前言
此内容为学习廖雪峰Python教程的学习笔记,内容是个人认为常常疏忽或是未了解的知识点,不具连贯性,如要学习Python,推荐前往廖雪峰官方站点学习。
基础常见问题
编码问题
1.在最新的Python 3版本中,字符串是以Unicode编码的。
2.字符串默认类型为str类型,在内存中以Unicode表示,一个字符对应若干个字节。
3.这常常会导致一些问题,特别是在进行相关字符串加密解密时,一定要考虑到先把字符串转为以字节为单位的bytes 可以直接转,也可以通过encode()方法可以编码为指定的bytes,反正一定要记得转,否则会出错。
Python3中的bytes和bytearray
1.bytes:不可变字节类型,bytes是字节组成的有序的不可变序列
2.字节数组,可变,bytearray是字节组成的有序的可变序列
3.其他相关使用,请看这里
关于迭代
1.字典的迭代,默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
2.判断一个对象是可迭代对象,可用
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list是否可迭代
True
>>> isinstance(123, Iterable) # 整数是否可迭代
False
3.如果要对list实现下标循环,用enumerate,enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
>>> for i, value in enumerate(['A', 'B', 'C']):
... print(i, value)
...
0 A
1 B
2 C
4.上面的for循环里,同时引用了两个变量,这种在Python中是很常见的,也很常用
>>> for x, y in [(1, 1), (2, 4), (3, 9)]:
... print(x, y)
...
1 1
2 4
3 9
列表生成式
多用方知,几个例子:
# 生成 x * x列表
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
# 附加条件
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
# 使用两层循环
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
# 将字典转为列表
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> [k + '=' + v for k, v in d.items()]
['y=B', 'x=A', 'z=C']
# 把列表中的字符串都变为小写,由于非字符串类型没有lower()方法,所以要分别讨论
>>> L1 = ['Hello', 'World', 18, 'Apple', None]
>>> L2 = [x.lower() if isinstance(x, str) else x for x in L1]
>>> L2
['hello', 'world', 18, 'apple', None]
>>>
生成器
通过列表生成式,可以直接创建一个列表。但由于受到内存限制,列表容量肯定是有限的。同时,列表元素可以按照某种算法推算出来,那是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
1.和列表生成是类似,generator是非常强大的工具,在Python中,可以简单地把列表生成式改成generator,即:只要把一个列表生成式的[]改成(),就创建了一个generator。当然,也可以通过函数实现复杂逻辑的generator。
2.生成器中的值可通过next(g) (g为生成器)一个一个访问,因为generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
3.next(g)一般不用,一般使用for循环,因为generator也是可迭代对象
# 可写为生成器的函数中使用yield即为生成器
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
# generator函数的“调用”实际返回一个generator对象
print(fib(6))
# 通过for循环访问,注意,这里得不到 return 'done' 即打印不出done,下面有说明。
for i in fib(6):
print(i)
4.generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
5.for循环调用generator时,发现得不到generator的return语句的返回值。如果想要得到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中
# 通过捕获StopIteration错误,获取return返回值,返回值包含在StopIteration的value中
g = fib(6)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e:
print('Generator return value:', e.value)
break
# 输出
# g: 1
# g: 1
# g: 2
# g: 3
# g: 5
# g: 8
# Generator return value: done
迭代器
1.凡是可作用于for循环的对象都是Iterable类型,主要有两类
- 集合数据类型,如list、tuple、dict、set、str等;
- generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable 可以使用isinstance()判断一个对象是否是Iterable对象:
2.凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列,可以使用isinstance()判断一个对象是否是Iterator对象。
- 生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator
- 把list、dict、str等Iterable变成Iterator可以使用
iter()函数 - Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算
- Iterator可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数
- Python的for循环本质上就是通过不断调用
next()函数实现的
函数
函数中的return
1.如果没有return语句,函数执行完毕后也会返回结果,只是结果为None。return None可以简写为return。
2.如果返回有多个值,则返回的是一个元组对象。
# 一个简单的函数,从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的新的坐标
import math
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
# 用连个变量接收返回值
x, y = move(100, 100, 60, math.pi / 6)
print(x, y)
151.96152422706632 70.0
# 用一个变量接收返回值
r = move(100, 100, 60, math.pi / 6)
print(r)
(151.96152422706632, 70.0)
返回值是一个tuple!但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,Python的函数返回多值其实就是返回一个tuple,这样写起来也更方便。详细
空函数
如果想定义一个什么事也不做的空函数,可以用pass语句:
def func_name():
pass
实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
pass还可以用在其他语句里,比如:
if age >= 18:
pass
缺少了pass,代码运行就会有语法错误。
函数参数
1.如果定义连个同名函数(不设置类),后面定义的会覆盖前面的。
2.Python中有5类参数,分别为位置参数,默认参数,可变参数,关键字参数和命名关键字参数
- 位置参数:即平时常用的参数,参数位置需要对应好。
- 默认参数:在位置参数的基础上赋予其一个默认值,其他的类似位置参数。必选参数(用到的位置参数)在前,默认参数在后。
- 可变参数:形式为
*args,可理解为参数是不定长列表或元组。如:*nums表示把列表nums的所有元素作为可变参数传进去。 - 关键字参数:形式为
**kw,可理解为参数是不定长字典。 - 命名关键字参数:限制关键字参数的键(参数名) 只能用规定的参数名做参数,同时可以提供默认值。
(1)对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。
(2)和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
(3)如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:如
def person(name, age, *args, city, job):
print(name, age, args, city, job)
3.注意:默认参数必须指向不变对象
一个例子,如果定义的默认参数是L=[]时,即是可变对象时:
def add_end(L=[]):
L.append('END')
return L
# 调用发现,L从[]->['END']->['END', 'END']
print(add_end()) # ['END']
print(add_end()) # ['END', 'END']
Python函数在定义的时候,默认参数L=[]的值就被计算出来了,并指向一个对象,即[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
也就是说,每调用一次,其对应的默认参数就变一次。所以默认参数必须指向不变对象。具体看这里。
参数组合(顺序)
Python中,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
# 调用f1函数
print(f1(1, 2)) # a = 1 b = 2 c = 0 args = () kw = {}
print(f1(1, 2, c=3)) # a = 1 b = 2 c = 3 args = () kw = {}
print(f1(1, 2, 3, 'a', 'b')) # a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
print(f1(1, 2, 3, 'a', 'b', x=99)) # a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
# 调用f2函数
print(f2(1, 2, d=99, ext=None)) # a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}
实际上,每个输出都还有一个None,即对应上面说的:如果没有return语句,函数执行完毕后也会返回结果,只是结果为None。

实际上,也可以通过一个tuple和dict,调用上述函数:
args = (1, 2, 3, 4)
kw = {'d': 99, 'x': '#'}
print(f1(*args, **kw)) # a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
args = (1, 2, 3)
kw = {'d': 88, 'x': '#'}
print(f2(*args, **kw)) # a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}
也就是说,对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
函数式编程
函数式编程的特点
1.面向过程的程序设计: 通过把大段代码拆成函数,一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
2.函数式编程: 一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。
而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
3.虽然也可以归结到面向过程的程序设计,但其思想更接近数学计算。
4.函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数
5.Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言
高阶函数
1.英文叫Higher-order function
2.变量可以指向函数,函数的参数能接收变量,即一个函数可以接收另一个函数作为参数,这种函数就称之为高阶函数。
3.map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
>>> list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
['1', '2', '3', '4', '5', '6', '7', '8', '9']
4.reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
5.几个例子
# 规范用户名输入
def normalize(name):
return name[:1].upper() + name[1:].lower()
# 测试:
L1 = ['adam', 'LISA', 'barT']
L2 = list(map(normalize, L1))
print(L2)
# map返回的是map对象地址
L3 = map(normalize, L1)
print(L3)
# Python提供的sum()函数可以接受一个list并求和,请编写一个prod()函数,可以接受一个list并利用reduce()求积:
from functools import reduce
def prod(L):
return reduce(lambda x, y: x * y, L)
print('3 * 5 * 7 * 9 =', prod([3, 5, 7, 9]))
if prod([3, 5, 7, 9]) == 945:
print('测试成功!')
else:
print('测试失败!')
# 利用map和reduce编写一个str2float函数,把字符串'123.456'转换成浮点数123.456:
def str2float(s):
return reduce(lambda x, y: x * 10 + y, list(map(lambda x: float(x) / 1000, s.replace('.', ''))))
print('str2float(\'123.456\') =', str2float('123.456'))
if abs(str2float('123.456') - 123.456) < 0.00001:
print('测试成功!')
else:
print('测试失败!')
6.filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
注意:filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
7.sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序。
例如:按绝对值大小排序:
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]
实现忽略大小写的排序:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)
['about', 'bob', 'Credit', 'Zoo']
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
['Zoo', 'Credit', 'bob', 'about']
闭包
1.高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
2.闭包概念:在一个内部函数中,对外部作用域的变量进行引用,(并且一般外部函数的返回值为内部函数),那么内部函数就被认为是闭包。
3.下面看一个例子,利用闭包返回一个计数器函数,每次调用它返回递增整数:
# 闭包的使用,注意内层函数返回的是函数名
def createCounter():
# 注意,l = [0]只会在调用createCounter()时调用,这里使用列表,是因为其是可变变量,如果是数值型,则会出错。
l = [0]
def counter():
l[0] += 1
return l[0]
# 返回函数名,可看作函数的引用
return counter
# 测试:
counterA = createCounter()
print(counterA(), counterA(), counterA(), counterA(), counterA()) # 1 2 3 4 5
counterB = createCounter()
if [counterB(), counterB(), counterB(), counterB()] == [1, 2, 3, 4]:
print('测试通过!')
else:
print('测试失败!')
运行结果:
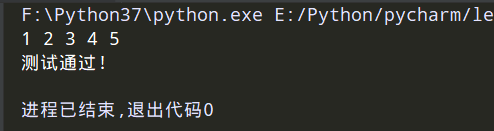
若是这样,则会出错:UnboundLocalError: local variable 'i' referenced before assignment
def createCounter():
i = 0
def counter():
i = 1 + i
return i
return counter
因为:在当前作用域中的给变量赋值时,该变量将成为该作用域的局部变量,并在外部范围中隐藏任何类似命名的变量。
而上面的情况不会是因为可变变量l所指向的对象始终没有变(只是其内容变了)这类似元组本身是不可变的,但是元组内的列表元素的内容是可变的。
4.深入理解闭包,先看一个例子:
# 关于闭包
def outer():
x = 1
y = 'a'
def inner():
print(x, y) #1
return inner
foo = outer()
print(foo.__closure__) #2
foo()
运行结果:

5.解释:闭包的理解
(1)python里运行的东西,都按照作用域规则来运行。
- x是outer函数里的local变量
- 在
#1处,inner打印x,y时,python在inner的locals中寻找x,找不到后再到外层作用域(即outer函数)中寻找,找到后打印。
(2)看起来一切OK,那么从变量生命周期(lifetime)的角度看,会发生什么呢:
- x,y是outer的local变量,这意味着只有outer运行时,x,y才存在。那么按照python运行的模式,我们不能在outer结束后再去调用inner。
- 在我们调用inner的时候,x,y应该已经不存在了。应该发生一个运行时错误或者其他错误。但是这一些都没有发生,inner函数依旧正常执行,打印了x,y。
(3)解释
- Python支持一种特性叫做函数闭包(function closures):在非全局(global)作用域中定义inner函数(即嵌套函数)时,会记录下它的嵌套函数namespaces(嵌套函数作用域的locals)
- 可以称作:定义时状态,可以通过
__closure__这个属性来获得inner函数的外层嵌套函数的namespaces。(如上例中#2,打印了foo.__closure__,里面保存了一个int对象和一个str对象,分别对应x和y)
注意:每次调用outer函数时,inner函数都是新定义的。上面的例子中,x,y是固定的,所以每次调用inner函数的结果都一样。
所以,闭包实际上是记录了外层嵌套函数作用域中的local变量。
6.更多可参考:python之嵌套函数与闭包
匿名函数lambda
直接看一个例子:
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[1, 4, 9, 16, 25, 36, 49, 64, 81]
匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数。
装饰器
1.装饰器本身是一个Python函数,它可以让其他函数在自身代码不做任何变动的情况下增加额外功能,装饰器的返回值也是一个函数对象。
2.常用语有切面需求的场景,比如:插入日志,性能测试,事物处理,缓存,权限校验等等场景。
3.理解装饰器:
4.装饰器例子:
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2015-3-25')
now()
# 执行结果如下:
# execute now():
# 2015-3-25
简单分析:
- 调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志
- 把
@log放到now()函数的定义处,相当于执行了语句:
now = log(now)
- 由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
- wrapper()函数的参数定义是(*args, **kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
5.带参数的装饰器
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
@log('execute')
def now():
print('2015-3-25')
now()
# 执行结果如下:
# execute now():
# 2015-3-25
分析:
- 和两层嵌套的decorator相比,3层嵌套的效果是这样的:
now = log('execute')(now)
- 首先执行
log('execute'),返回的是decorator函数,再调用返回的函数,参数是now函数,返回值最终是wrapper函数。 - 但有个问题,就是原函数的元信息丢失了,比如函数的docstring,
__name__,参数列表等。 - 上面两种情况都是有这个问题:经过decorator装饰之后的函数,它们的
__name__已经从原来的'now'变成了'wrapper':
print(now.__name__) # wrapper
- 因为返回的那个wrapper()函数名字就是'wrapper',所以,需要把原始函数的__name__等属性复制到wrapper()函数中,否则便会丢失。
6.一个完整的装饰器
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
或者针对带参数的decorator:
import functools
def log(text):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
import functools是导入functools模块,这样的导入使用时需要在前面加上functools,如上面的functools.wraps(func)。如果通过from functools import wraps,就只需要wraps(func)即可。
偏函数
1.functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
from functools import partial
# 转为二进制
int2 = partial(int, base=2)
print(int2('1010'))
# 因为上面是默认参数,所以这里依然可以设置关键字参数base的值
print(int2('1010', base=10))
# 打印出
# 10
# 1010
2.创建偏函数时,实际上可以接收函数对象、*args和**kw这3个参数
int2('10010')
# 相当于
kw = { 'base': 2 }
int('10010', **kw)
又如:
max2 = functools.partial(max, 10)
# 会把10作为*args的一部分自动加到左边
max2(5, 6, 7)
# 相当于
args = (10, 5, 6, 7)
max(*args)
模块
概述
1.好处:模块最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
2.使用模块还可以避免函数名和变量名冲突,只需注意,不要与内置函数名字冲突,这里查看内置函数。
3.为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
4.引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,abc.py模块的名字就变成了mycompany.abc,类似的,xyz.py的模块名变成了mycompany.xyz。
5.每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是mycompany。
6.自己创建模块时要注意命名,不能和Python自带的模块名称冲突。例如,系统自带了sys模块,自己的模块就不可命名为sys.py,否则将无法导入系统自带的sys模块。
模块内容
1.标准格式
2.其他需要注意的内容
if __name__=='__main__':Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该hello模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。- 类似
__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如__author__,__name__就是特殊变量,模块定义的文档注释也可以用特殊变量__doc__访问,我们自己的变量一般不要用这种变量名 - 类似
_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等
即:外部不需要引用的函数全部定义成private,只有外部需要引用的函数才定义为public。
模块导入
1.模块搜索路径:默认情况下,Python解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在sys模块的path变量中:
>>> import sys
>>> sys.path
['', 'F:\\Python37\\python37.zip', 'F:\\Python37\\DLLs', 'F:\\Python37\\lib', 'F:\\Python37', 'F:\\Python37\\lib\\site-packages']
2.如果要添加自己的搜索目录,有两种方法:
- 一是直接修改sys.path,添加要搜索的目录,这种方法是在运行时修改,运行结束后失效。
>>> import sys
>>> sys.path.append('/Users/michael/my_py_scripts')
- 第二种方法是设置环境变量PYTHONPATH,该环境变量的内容会被自动添加到模块搜索路径中。设置方式与设置Path环境变量类似。注意只需要添加你自己的搜索路径,Python自己本身的搜索路径不受影响。
3.模块导入的三种方式
- import
- from ... import ...
- import ... as 别名