前言
链表(Linked list)比数组稍微复杂一点,在我们生活中用到最常见的应该是缓存,它是一种提高数据读取性能的技术,常见的如cpu缓存,浏览器缓存,数据库缓存等。今天我们就来学习一下链表
正文
一、链表的定义?
1.一种线性表(数据排成像一条线一样的结构。每个线性表上的数据最多有前后两个方向);
2.从存储结构来看,通过“指针”,将一组零散的内存块串联起来使用的数据结构;
3.链表中的每一个内存块被称为结点Node,结点除了存储数据外,还需记录链上下一个节点的地址(next)
二、链表的优缺点
1.插入、删除数据效率高,时间复杂度为O(1)(只需更改指针指向即可),随机访问效率低,时间复杂度为O(n)级别(需要从链头至链尾进行遍历)。
2.和数组相比,内存空间消耗更大,因为每个存储数据的节点都需要额外的空间存储后继指针。
三、常用链表:单链表、循环链表、双向链表、双向循环链表和块状链表
1.单链表

1)每个节点只包含一个指针,即后继指针。
2)单链表有两个特殊的节点,即首节点和尾节点。
用首节点地址表示整条链表,尾节点的后继指针指向空地址null。
3)性能特点:插入和删除节点的时间复杂度为O(1),查找的时间复杂度为O(n)。
2.循环链表
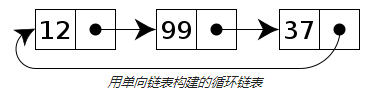
1)除了尾节点的后继指针指向首节点的地址外均与单链表一致。
2)适用于存储有循环特点的数据,比如约瑟夫问题。
3.双向链表

1)节点除了存储数据外,还有两个指针分别指向前一个节点地址(前驱指针prev)和下一个节点地址(后继指针next)。
2)当此“连接”为第一个“连接”时,指向空值或者空列表
当此“连接”为最后一个“连接”时,指向空值或者空列表)
3)性能特点:
和单链表相比,存储相同的数据,需要消耗更多的存储空间。
插入、删除操作比单链表效率更高O(1)级别。
以删除操作为例,删除操作分为2种情况:
给定数据值删除对应节点和给定节点地址删除节点。
对于前一种情况,单链表和双向链表都需要从头到尾进行遍历从而找到对应节点进行删除,时间复杂度为O(n)。
对于第二种情况,要进行删除操作必须找到前驱节点,单链表需要从头到尾进行遍历直到p->next = q,时间复杂度为O(n),而双向链表可以直接找到前驱节点,时间复杂度为O(1)。
对于一个有序链表,双向链表的按值查询效率要比单链表高一些。
因为我们可以记录上次查找的位置p,每一次查询时,根据要查找的值与p的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
4.双向循环链表(双向,循环链表的结合)
首节点的前驱指针指向尾节点,尾节点的后继指针指向首节点。
5.块状链表
块状链表本身是一个链表,但是链表储存的并不是一般的数据,而是由这些数据组成的顺序表。每一个块状链表的节点,也就是顺序表,可以被叫做一个块。
块状链表通过使用可变的顺序表的长度和特殊的插入、删除方式,可以在达到{displaystyle O({sqrt {n}})}
四、数组VS链表
1.插入、删除和随机访问的时间复杂度
数组:插入、删除的时间复杂度是O(n),随机访问的时间复杂度是O(1)。
链表:插入、删除的时间复杂度是O(1),随机访问的时间复杂端是O(n)。
2.数组缺点
1)若申请内存空间很大,比如100M,但若内存空间没有100M的连续空间时,则会申请失败,尽管内存可用空间超过100M。
2)大小固定,若存储空间不足,需进行扩容,一旦扩容就要进行数据复制,而这时非常费时的。
3.链表缺点
1)内存空间消耗更大,因为需要额外的空间存储指针信息。
2)对链表进行频繁的插入和删除操作,会导致频繁的内存申请和释放,容易造成内存碎片,如果是Java语言,还可能会造成频繁的GC(自动垃圾回收器)操作。
4.如何选择
数组简单易用,在实现上使用连续的内存空间,可以借助CPU的缓冲机制预读数组中的数据,所以访问效率更高,而链表在内存中并不是连续存储,所以对CPU缓存不友好,没办法预读。
如果代码对内存的使用非常苛刻,那数组就更适合
CPU缓存机制指的是什么?为什么就数组更好了?
CPU在从内存读取数据的时候,会先把读取到的数据加载到CPU的缓存中。而CPU每次从内存读取数据并不是只读取那个特定要访问的地址,而是读取一个数据块(这个大小我不太确定。。)并保存到CPU缓存中,然后下次访问内存数据的时候就会先从CPU缓存开始查找,如果找到就不需要再从内存中取。这样就实现了比内存访问速度更快的机制,也就是CPU缓存存在的意义:为了弥补内存访问速度过慢与CPU执行速度快之间的差异而引入。
对于数组来说,存储空间是连续的,所以在加载某个下标的时候可以把以后的几个下标元素也加载到CPU缓存这样执行速度会快于存储空间不连续的链表存储。
相关文章
以上内容为个人的学习笔记,仅作为学习交流之用。

欢迎大家关注公众号,不定时干货,只做有价值的输出
作者:Dawnzhang
出处:https://www.cnblogs.com/clwydjgs/p/9778394.html
版权:本文版权归作者
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任