-
DDL,英文叫做Data Definition Language,也就是数据定义语言,它用来定义我们的数据库对象,包括 数据库、数据表和列。通过使用DDL,我们可以创建,删除和修改数据库和表结构。
-
DML,英文叫做Data Manipulation Language,数据操作语言,我们用它操作和数据库相关的记录,比 如增加、删除、修改数据表中的记录。
-
DCL,英文叫做Data Control Language,数据控制语言,我们用它来定义访问权限和安全级别。
-
DQL,英文叫做Data Query Language,数据查询语言,我们用它查询想要的记录,它是SQL语言的重中
之重。在实际的业务中,我们绝大多数情况下都是在和查询打交道,因此学会编写正确且高效的查询语 句,是学习的重点。
1. 表名、表别名、字段名、字段别名等都小写; 2. SQL保留字、函数名、绑定变量等都大写。
你能看到SELECT、FROM、WHERE这些常用的SQL保留字都采用了大写,而name、hp_max、role_main这 些字段名,表名都采用了小写。此外在数据表的字段名推荐采用下划线命名,比如role_main这种。
二、DBMS
(1)DB、DBS和DBMS的区别是什么
(3)sql阵营中的DBMS
三、不同DBMS中的sql是怎么执行的。
-
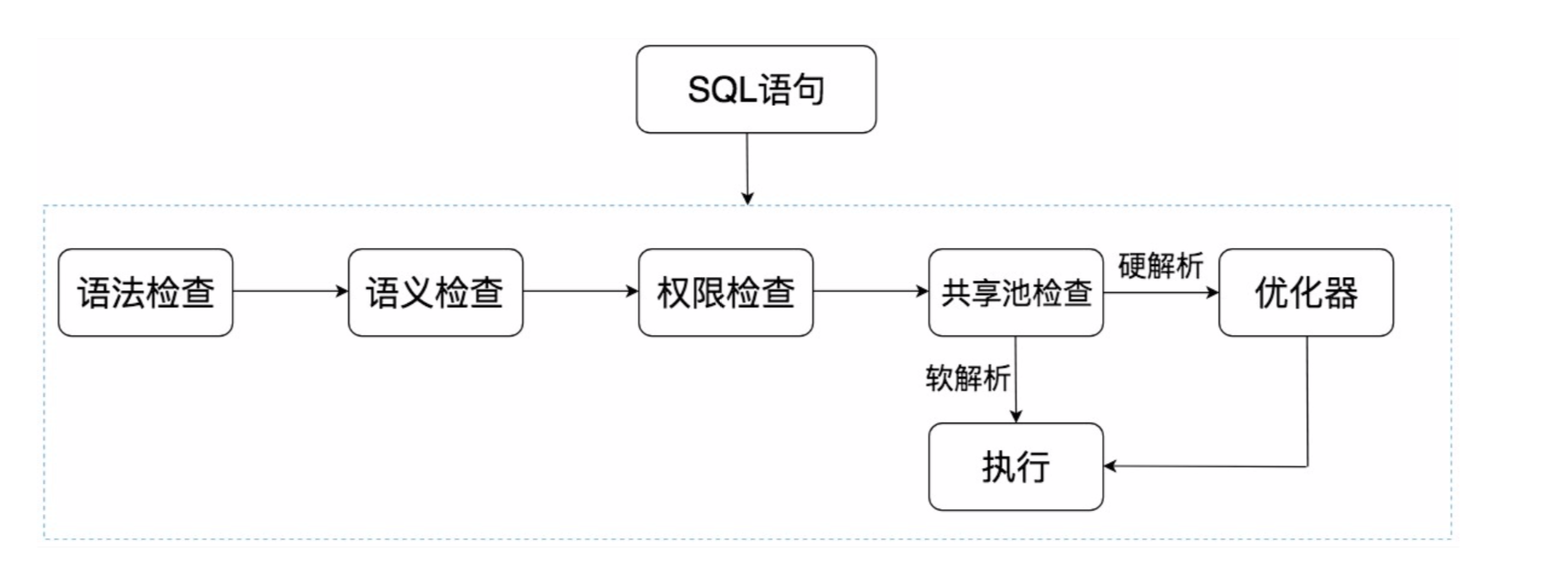
语法检查:检查SQL拼写是否正确,如果不正确,Oracle会报语法错误。
-
语义检查:检查SQL中的访问对象是否存在。比如我们在写SELECT语句的时候,列名写错了,系统就会提示错误。语法检查和语义检查的作用是保证SQL语句没有错误。
-
权限检查:看用户是否具备访问该数据的权限。
-
共享池检查:共享池(Shared Pool)是一块内存池,最主要的作用是缓存SQL语句和该语句的执行计
划。Oracle通过检查共享池是否存在SQL语句的执行计划,来判断进行软解析,还是硬解析。那软解析和 硬解析又该怎么理解呢? 在共享池中,Oracle首先对SQL语句进行Hash运算,然后根据Hash值在库缓存(Library Cache)中查 找,如果存在SQL语句的执行计划,就直接拿来执行,直接进入“执行器”的环节,这就是软解析。 如果没有找到SQL语句和执行计划,Oracle就需要创建解析树进行解析,生成执行计划,进入“优化 器”这个步骤,这就是硬解析。
-
优化器:优化器中就是要进行硬解析,也就是决定怎么做,比如创建解析树,生成执行计划。
-
执行器:当有了解析树和执行计划之后,就知道了SQL该怎么被执行,这样就可以在执行器中执行语句了。
共享池是Oracle中的术语,包括了库缓存,数据字典缓冲区等。库缓存:存sql语句和执行计划。数据字典缓冲区(决定是否需要硬解析,应该避免使用硬解析,因为在sql执行过程中,创建解析树,生成执行计划是很消耗资源。):Oracle中的对象定义,比如表、视图、索引等对象。对sql进行解析对时候,如果需要相关数据就会从数据字典缓冲区中提取。如何避免硬解析,尽量使用软解析呢?在Oracle中,绑定变量是它的一大特色。绑定变量就是 在SQL语句中使用变量,通过不同的变量取值来改变SQL的执行结果。这样做的好处是能提升软解析的可能 性,不足之处在于可能会导致生成的执行计划不够优化,因此是否需要绑定变量还需要视情况而定。举个例子,我们可以使用下面的查询语句:
SQL> select * from player where player_id = 10001;
你也可以使用绑定变量,如:
SQL> select * from player where player_id = :player_id;
这两个查询语句的效率在Oracle中是完全不同的。如果你在查询player_id = 10001之后,还会查询10002、 10003之类的数据,那么每一次查询都会创建一个新的查询解析。而第二种方式使用了绑定变量,那么在第 一次查询之后,在共享池中就会存在这类查询的执行计划,也就是软解析。
因此我们可以通过使用绑定变量来减少硬解析,减少Oracle的解析工作量。但是这种方式也有缺点,使用动 态SQL的方式,因为参数不同,会导致SQL的执行效率不同,同时SQL优化也会比较困难。
2、mysql中sql是如何执行的?
mysql是典型的cs架构,服务器端程序使用mysqld。整体的mysql流程如下图所示。
 1. 连接层:客户端和服务器端建立连接,客户端发送SQL至服务器端; 2. SQL层:对SQL语句进行查询处理;
1. 连接层:客户端和服务器端建立连接,客户端发送SQL至服务器端; 2. SQL层:对SQL语句进行查询处理;
3. 存储引擎层:与数据库文件打交道,负责数据的存储和读取。其中SQL层与数据库文件的存储方式无关,我们来看下SQL层的结构:
 1. 查询缓存:Server如果在查询缓存中发现了这条SQL语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在MySQL8.0之后就抛弃了这个功能。
1. 查询缓存:Server如果在查询缓存中发现了这条SQL语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在MySQL8.0之后就抛弃了这个功能。-
解析器:在解析器中对SQL语句进行语法分析、语义分析。
-
优化器:在优化器中会确定SQL语句的执行路径,比如是根据全表检索,还是根据索引来检索等。
-
执行器:在执行之前需要判断该用户是否具备权限,如果具备权限就执行SQL查询并返回结果。在MySQL8.0以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
你能看到SQL语句在MySQL中的流程是:SQL语句→缓存查询→解析器→优化器→执行器。在一部分中, MySQL和Oracle执行SQL的原理是一样的。
与Oracle不同的是,MySQL的存储引擎采用了插件的形式,每个存储引擎都面向一种特定的数据库应用环 境。同时开源的MySQL还允许开发人员设置自己的存储引擎,下面是一些常见的存储引擎:-
InnoDB存储引擎:它是MySQL 5.5.8版本之后默认的存储引擎,最大的特点是支持事务、行级锁定、外 键约束等。
-
MyISAM存储引擎:在MySQL 5.5.8版本之前是默认的存储引擎,不支持事务,也不支持外键,最大的特 点是速度快,占用资源少。
-
Memory存储引擎:使用系统内存作为存储介质,以便得到更快的响应速度。不过如果mysqld进程崩 溃,则会导致所有的数据丢失,因此我们只有当数据是临时的情况下才使用Memory存储引擎。
-
NDB存储引擎:也叫做NDB Cluster存储引擎,主要用于MySQL Cluster分布式集群环境,类似于Oracle 的RAC集群。
-
Archive存储引擎:它有很好的压缩机制,用于文件归档,在请求写入时会进行压缩,所以也经常用来做 仓库。
需要注意的是,数据库的设计在于表的设计,而在MySQL中每个表的设计都可以采用不同的存储引擎,我 们可以根据实际的数据处理需要来选择存储引擎,这也是MySQL的强大之处。
-
-