昨天 22:00~22:30 左右与 23:30~00:30 左右,有1台服役多年的阿里云负载均衡突然失灵,造成通过这台负载均衡访问博客站点的用户遭遇 502, 503, 504 ,由此给您带来麻烦,请您谅解。
问题非常奇怪,从表现看,似乎负载均衡与后端服务器之间的内网通信出现了问题。有时健康检查成功,但转发请求到后端服务器会失败;后端服务器明明正常,有时健康检查却失败;最糟糕的时候,所有后端服务器都健康检查失败。而其他使用同样后端服务器的负载均衡都没出现这个问题,最终通过下线这台负载均衡解决了问题。
这台负载均衡是我们 2013 年刚上阿里云时购买的,服役多年,之前从未出现这个问题,现在看来只能被迫让它退役了。

昨天上午发现,我们用于部署除博客站点之外所有其他应用的 docker swarm 集群中所有服务器 CPU 100% 。
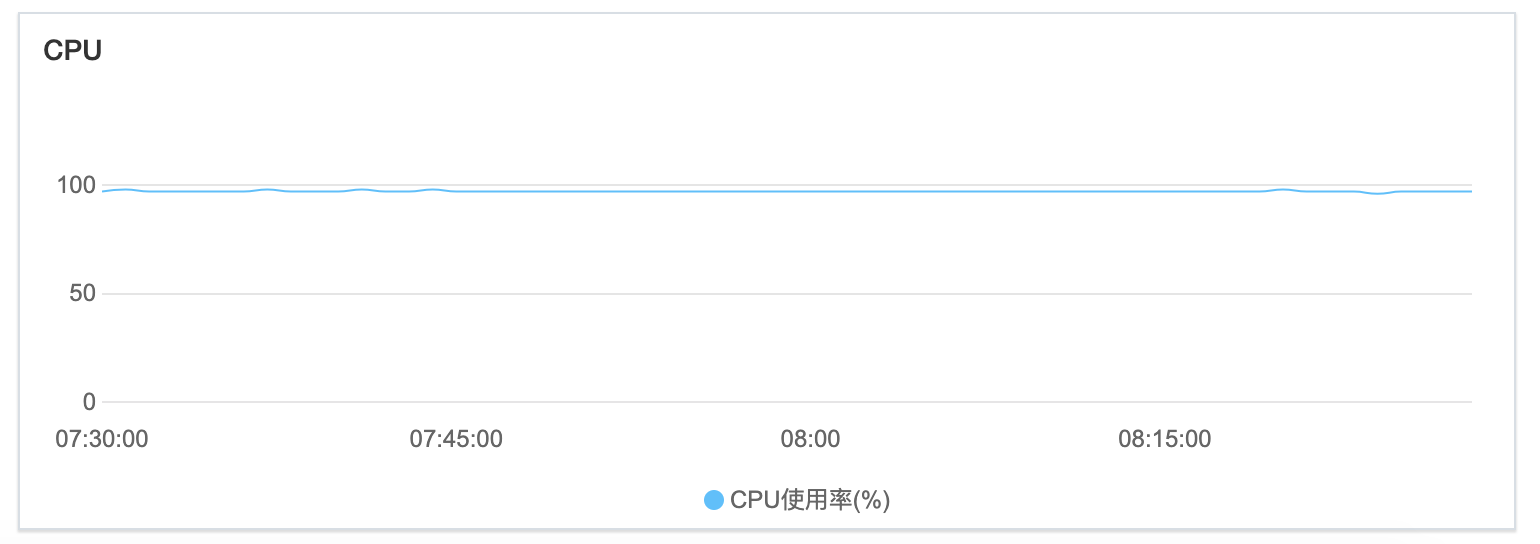
这个 CPU 100% 与通常的 CPU 100% 有很大的不一样,虽然是 100% ,但不影响应用的正常运行。今年3月份也遇到到同样的问题,当时通过 top 命令查看是 sy (system cpu time spent in kernel space) 占用了很多 CPU ,后来通过重启集群中的所有 worker 节点服务器并重新部署应用解决的。
今天早上我们也采取了重启节点服务器的方法,重启后服务器 CPU 恢复了正常。但在操作过程中,闪存应用容器出现了问题,造成 15 分钟左右闪存站点访问不正常,由此给您带来麻烦,请您谅解。
最近,博客站点遭遇多次 DDoS 攻击,最高一次攻击流量达到了近 80G 。一攻击就会被阿里云屏蔽30分钟,虽然我们采取了应急措施,但全部生效要10分钟左右,所以每次受攻击影响的用户可能要10分钟左右才能恢复正常访问,由此给您带来您谅解,请您谅解。
在这个多事之秋,网站出现了很多次故障,给大家带来了很大的麻烦,恳请大家的谅解。
这个多事之秋,对我们也是一种考验,我们会吸取教训,进一步提升自己,在接下来更加努力地和大家共建更加朝气蓬勃的园子。