个人对于选择存储引擎,建表,建索引,sql优化的一些总结,给读者提供一些参考意见
推荐访问我的个人网站,排版更好看: https://chenmingyu.top/mysql-optimize/
存储引擎
mysql中查看支持的引擎的sql:
show engines;
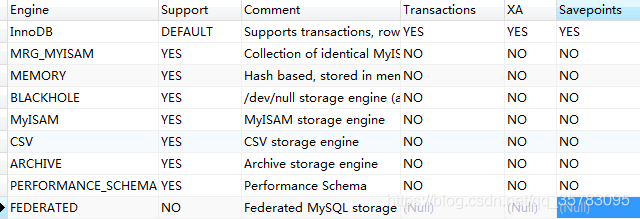
日常工作中使用较多的存储引擎对比:InnoDB,MyISAM
| InnoDB | MyISAM | |
|---|---|---|
| 存储限制 | 64T | 256T |
| 支持事务 | yes | no |
| 支持索引 | yes | yes |
| 支持全文索引 | no | yes |
| 支持数据缓存 | yes | no |
| 支持外键 | yes | no |
| 支持Hash索引 | no | no |
innodb
支持提交、回滚和崩溃恢复能力的事物安全(ACID),支持行锁,支持外键完整性约束
适合场景
- 需要事务处理
- 表数据量大,高并发操作
MyISAM
MyISAM存储引擎提供了高速检索和存储的能力,支持全文索引
适合场景
- 很多count计算的
- 查询非常频繁的
其余几种存储引擎
MEMORY引擎
数据只保存在内存中,因为是在内存中,拥有极高的插入,更新,查询的效率,但是重启后数据都会丢失,表级锁,并发性能低。
MERGE引擎
merge表是一组MyISAM表的组合,所以merge表是没有数据的,对这个表的操作实际上是操作内部的MyISAM表,将多个MyISAM表合并适合做一些报表之类的操作。
ARCHIVE引擎
仅支持插入和查询,使用zlib压缩库,在记录被请求的时候实时压缩,不支持事务,支持行级锁,适合存储大量的日志数据。
个人是推荐Innodb引擎的,公司部门里也是规定新建表的时候必须使用Innodb引擎,Innodb引擎较MyISAM引擎可以提供更多的功能,不是很实时的查询场景可以使用缓存,近实时的查询可以使用es,当然了这只是个人看法,针对不同的场景选择不同的存储引擎还是很有必要滴。所以在知道不同存储引擎的特性之后,才可以根据不同业务需求选择合适的存储引擎。
建表原则
在建表的时候尽量遵循以下原则
-
尽量选择小的数据类型,数据类型选择上尽量tinyint(1字节)>smallint(2字节)>int(4字节)>bigint(8字节),比如逻辑删除yn字段上(1代表可用,0代表)就可以选择tinyint(1字节)类型
-
尽量保证字段数据类型长度固定
-
尽量避免使用null,使用null的字段查询很难优化,影响索引,可以使用0或''代替
-
避免宽表,能拆分就拆分,一个表往往跟一个实体域对应,就像设计对象的时候一样,保持单一原则
-
尽量避免使用text和blob,如果非使用不可,将类型为text和blob的字段在独立成一张新表,然后使用主键对应原表
-
禁止使用float或double类型,这个坑超大,float或double存在精度问题,在进行比较或者加减操作的时候会丢失精度导致数据异常,凡是使用float或double类型的时候考虑下可不可使用int或bigint代替。比如金额,以元为单位使用float或double类型的时候,可以考虑以分为单位使用int,bigint类型代替,然后由业务代码进行单位的转换。
-
每张表都加上createUser,createTime.updateUser,updateTime字段
-
起名字要规范,包括:库名,表名,字段名,索引名
-
查询频繁使用的字段记得加索引
-
尽量避免使用外键,不用外键约束,性能更高,然后数据的完整性有程序进行管理
-
如果表的数量可以预测到非常大,最好在建表的时候,就进行分表,不至于一时间数据量非常大导致效率问题
未完待补充,,,
索引
索引是为来加速对表中数据行中的检索而创建的一种分散的数据结果,是针对表而建立的,它是由数据页面以外的索引页面组成,每个索引页中的行都含有逻辑指针,以便加速检索物理数据,创建索引的目的在于提高查询效率,innodb的索引都是基于b tree实现的
索引类型
普通索引:最基本的索引,无限制
#方式1
CREATE INDEX idx_username ON sys_user(user_name(32));
#方式2
ALTER table sys_user ADD INDEX idx_username(user_name(32))
主键索引:一个表只能有一个主键索引,且不能为空
一般建表时同时创建了主键索引
CREATE TABLE `sys_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_name` varchar(32) DEFAULT NULL,
`pass_word` varchar(32) DEFAULT NULL,
`token` varchar(32) DEFAULT NULL,
`token_expire` int(11) DEFAULT NULL,
`yn` smallint(6) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=348007 DEFAULT CHARSET=utf8;
唯一索引:与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
CREATE UNIQUE INDEX idx_token ON sys_user(token_expire)
组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
ALTER TABLE sys_user ADD INDEX idx_un_te (user_name(32),token_expire);
全文索引:用来查找文本中的关键字,而不是直接与索引中的值相比较。只有char、varchar,text 列上可以创建全文索引
CREATE FULLTEXT INDEX idx_ ON sys_user(pass_word)
创建使用索引的原则
- 索引的字段尽量要小,根据索引查询数据的快慢取决于b tree的高度,当数据量恒定的时候,字节越少,存的索引的数量就越多,树的高度就越会越低
- 遵循索引的最左匹配原则
- 注意使用like的时候尽量不要使用“%a%”,这样的不走索引,可以使用“a%”,走索引
- 不要在索引的列上进行计算,比如 select * from sys_user where token_expire+1 = 10000,这样的语句 不会走有索引
- 什么样的字段建索引,就是那种频繁在where,group by,order by中出现的列,最好加上索引
索引的缺点
虽然索引的可以提高查询的效率,但是在进行insert,update,和delete的时候会降低效率,因为在保存数据的同时也会去保存索引。
不要在一个表里建过多的索引,问题跟上面一样,在操作数据的时候效率降低,而且数据量少的表要看情况建索引,如果建索引跟没建索引的效果差不多少的情况下就不要建索引了,如果是数据量大的表,就需要建索引去优化查询效率。
explain分析sql
可以使用explain去分析sql的执行情况,比如
explain select * from sys_user where token_expire = 10000;

在阿里的开发手册中提到过,sql性能优化的标准:至少要达到range,要求ref级别,如果可以是consts最好
说明一下,这里的级别指的就是上图的type字段:
- consts 是指单表中最多只有一个匹配行(主键或唯一索引)
- ref 指的是使用普通索引
- range 是指对索引进行范围查询
sql优化
关于sql语句的优化主要是两方面,一个是在建sql的时候需要注意的问题,另一个就是在发现有慢sql的时候可以根据不同情况进行分析,然后优化sql
优化的建议
-
查询的时候一定要记得使用limit进行限制
-
对于结果只需要一条数据的查询用limit 1进行限制
-
使用count(*)来统计行数或者使用count(主键)来查询,使用count(列)的时候,不会统计此列为null的情况
-
不要使用select * 来查数据,使用select 需要的列名,这样的方式去查询
-
使用join链接代替子查询
-
不要使用外键,外键的约束可以放在程序里解决
-
控制一下in操作的集合数量,不要太大了
-
针对慢查询使用explain去分析原因,然后优化sql,让其尽量走索引
上面说的四个方面就是我目前对于sql优化各个方面的注意事项,希望可以给大家提供一个参考,有问题的可以指出来,交流交流