尽管深度结构在许多任务中都有效,但它们仍然受到一些重要限制。尤其是,它们容易遭受灾难性的遗忘,即,由于需要新的类而未保留原始训练集时,当要求他们更新模型时,他们的表现很差。本文在语义分割的背景下解决了这个问题。当前的策略无法完成此任务,因为他们没有考虑语义分割的特殊方面:由于每个训练步骤仅为所有可能类别的子集提供注释,因此背景类别的像素(即不属于任何其他像素的像素)类)表现出语义分布偏移。在这项工作中,我们回顾了经典的增量学习方法,提出了一个新的基于蒸馏的框架,该框架明确地说明了这一转变。此外,我们引入了一种新颖的策略来初始化分类器的参数,从而防止偏向于背景类的预测。我们通过对Pascal-VOC 2012和ADE20K数据集进行了广泛评估,证明了我们的方法的有效性,大大优于最新的增量学习方法。
1. Introduction
语义分割是计算机视觉中的一个基本问题。在过去的几年中,由于深度神经网络的出现和大规模的人类注释数据集的出现[11,39],现有技术水平已得到显着改善[20,8,38,19,37] 。当前的方法是通过利用完全卷积网络(FCN)[20]将深层结构从图像级扩展到像素级分类而得出的。多年来,基于FCN的语义分割模型已经以多种方式进行了改进,例如通过利用多尺度表示[19,37],对空间依赖性和上下文提示进行建模[6,5,8]或考虑注意力模型[7]。
尽管如此,当发现新类别时,现有的语义分割方法仍未设计为逐步更新其内部分类模型。虽然深网无疑是强大的,但众所周知,它们在增量学习环境中的能力是有限的[16]。实际上,深层体系结构在更新其参数以学习新类别的同时,还要保留旧版本的良好性能(灾难性的遗忘[23])。
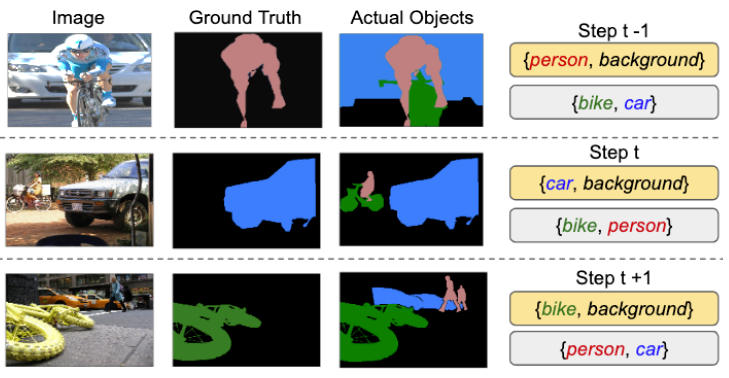
图1:用于语义分段的增量学习中背景类的语义转换的插图。 黄色框表示学习步骤中提供的基本事实,而灰色框表示未标记的类。 由于不同的学习步骤具有不同的标签空间,因此在步骤t,旧类(例如人)和看不见的类(例如汽车)可能会被标记为当前地面真理的背景。 在这里,我们显示了单类学习步骤的具体情况,但我们解决了添加任意数量的类的一般情况。
虽然增量学习的问题已在对象识别[18、17、4、28、15]和检测[32]中得到了传统解决,但对语义分割的关注却很少。在这里,我们填补了这一空白,提出了一种用于语义分割的增量类学习(ICL)方法。受先前关于图像分类的方法的启发[18、28、3],我们通过知识蒸馏来应对灾难性的遗忘[14]。但是,我们认为(并通过实验证明)在这种情况下,仅靠天真的应用先前的知识蒸馏策略是不够的。实际上,语义分割的一个特殊方面是特殊类(背景类)的存在,它表示未分配给任何给定对象类别的像素。虽然此类的存在在一定程度上影响了传统的脱机语义分割方法的设计,但在增量学习环境中却并非如此。如图1所示,可以合理地假设与背景类相关联的语义会随时间变化。换句话说,在学习步骤期间与背景相关联的像素像素可以在后续步骤中被分配给特定的对象类别,反之亦然,从而加剧了灾难性的遗忘。为了克服这个问题,我们通过引入两个新的损失项来适当考虑背景类中的语义分布变化,从而重新审视基于经典蒸馏的增量学习框架[18],从而引入了第一个针对语义分割的ICL方法。我们在两个数据集Pascal-VOC [11]和ADE20K [39]上广泛评估了我们的方法,表明我们的方法以及新颖的分类器初始化策略在很大程度上优于传统的ICL方法。
总而言之,本文的贡献如下:
•我们研究了用于语义分割的增量式课堂学习的任务,尤其是分析了由于背景课堂的存在而引起的分布转移的问题。
•我们提出了一个新的目标函数,并引入了一种特定的分类器初始化策略,以明确应对背景类不断发展的语义。 我们证明了我们的方法极大地减轻了灾难性的遗忘,从而达到了最先进的水平。
•考虑到不同的实验设置,我们在两个流行的语义细分数据集上对几种先前的ICL方法进行了基准测试。 我们希望我们的结果可以为将来的工作提供参考。
2. Related Works
语义分割是计算机视觉中的一个基本问题。在过去的几年中,由于深度神经网络的出现和大规模的人类注释数据集的出现[11,39],现有技术水平已得到显着改善[20,8,38,19,37] 。当前的方法是通过利用完全卷积网络(FCN)[20]将深层结构从图像级扩展到像素级分类而得出的。多年来,基于FCN的语义分割模型已经以多种方式进行了改进,例如通过利用多尺度表示[19,37],对空间依存关系和上下文提示进行建模[6、5、8]或考虑注意力模型[7]。方法[18]进行细分并设计一种策略来选择旧数据集的相关样本排练。 Taras等。提出了一种类似的分割遥感数据的方法。不同的是,Michieli等。 [24]考虑在特定环境下进行语义分割的ICL,在这种情况下,为旧班级提供la-bels,同时学习新班级。而且,他们假设新颖的类永远不会在以前的学习步骤的像素中作为背景出现。这些假设极大地限制了其方法的适用性。
在这里,我们提出了语义分割中ICL问题的更原则性的表述。与以前的工作相比,我们不将分析局限于医学[26]或遥感数据[33],也没有对标签空间在不同学习步骤之间的变化方式施加任何限制[24]。此外,我们是第一个在常用语义分类基准上提供对最新ICL方法的综合实验评估,并明确引入和解决背景类的语义转换的方法,该问题已被认可,但很大程度上受到监督以前的作品[24]。
增量学习。灾难性的遗忘问题[23]已被广泛研究用于图像分类任务[9]。以前的作品可以分为三类[9]:基于重播的[28、3、31、15、34、25],基于正则化的[17、4、36、18、10]和基于参数隔离的[ 22、21、30]。在基于重放的方法中,先前任务的示例被存储[28、3、15、35]或生成[31、34、25],然后在学习新任务的同时进行重放。基于参数隔离的方法[22、21、30]为每个任务分配参数的子集,以防止遗忘。基于正则化的方法可以分为优先关注和数据关注。前者[36,4,17,1]将知识定义为参数值,通过惩罚旧参数的重要参数的变化来限制新任务的学习。后者[18,10]利用分散[14]并将旧网络和新网络产生的激活之间的距离用作正则化术语,以防止灾难性遗忘。
尽管取得了这些进展,但除图像级分类外,几乎没有其他作品。这个方向的第一项工作是[32],它考虑了对象检测中的ICL,提出了一种基于蒸馏的方法,该方法从[18]改编而来,用于解决新颖的类识别和边界框建议的生成。在这项工作中,我们也采用与[32]类似的方法,并且我们采用蒸馏法。但是,在此我们提议解决建模背景分割的问题,这是语义分割设置所特有的。
模型部分:
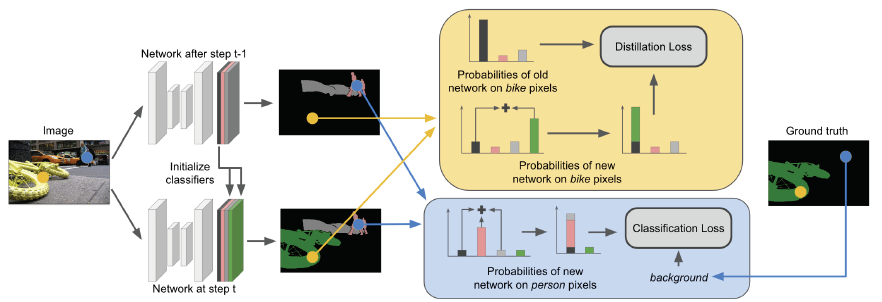
图2:我们的方法概述。 在学习步骤t,旧(顶部)模型和当前(底部)模型处理图像,将图像映射到它们各自的输出空间。 与标准ICL方法一样,我们应用交叉熵损失来学习新的类(蓝色块),并使用蒸馏损失来保留旧知识(黄色块)。 在此框架中,我们通过(i)使用旧背景的权重(左)初始化新分类器来建模跨不同学习步骤的背景的语义变化,(ii)比较十字架中像素级背景的地面真相 -熵,具有背景(黑色)或旧类(粉红色和灰色条)的概率,并且(iii)将蒸馏损失中旧模型给出的背景概率与具有背景或背景的概率相关新类(绿色栏)。
代码:https://github.com/gzb126/MiB
from paper:Modeling the Background for Incremental Learning in Semantic Segmentation