Faster R-CNN(笔记)
Faster R-CNN可以算是深度学习目标检测领域的祖师爷了,至今许多算法都是在其基础上进行延伸和改进的,它的出现,可谓是开启了目标检测的新篇章,其最为突出的贡献之一是提出了 "anchor" 这个东东,并且使用 CNN 来生成region proposal(目标候选区域),从而真正意义上完全使用CNN 来实现目标检测任务(以往的架构会使用一些传统视觉算法如Selective Search来生成目标候选框,而 CNN仅用来提取特征或最后进行分类和回归)。
Faster R-CNN 由 R-CNN 和 Fast R-CNN发展而来,R-CNN是第一次将CNN应用于目标检测任务的家伙,它使用selective search算法获取目标候选区域(region proposal),然后将每个候选区域缩放到同样尺寸,接着将它们都输入CNN提取特征后再用SVM进行分类,最后再对分类结果进行回归,整个训练过程十分繁琐,需要微调CNN+训练SVM+边框回归,无法实现端到端。
selective search:首先通过简单的区域划分算法,将图片划分成很多小区域,再通过相似度和区域大小(小的区域先聚合,这样是防止大的区域不断的聚合小区域,导致层次关系不完全)不断的聚合相邻小区域,类似于聚类的思路。
Fast R-CNN则受到 SPP-Net 的启发,将全图(而非各个候选区域)输入CNN进行特征提取得到 feature map,然后用RoI Pooling将不同尺寸的候选区域(依然由selective search算法得到)映射到统一尺寸。另外,它用Softmax替代SVM用于分类任务,除最后一层全连接层外,分类和回归任务共享了网络权重。
ROI pooling具体操作如下:
- 根据输入image,将ROI映射到feature map对应位置;
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
- 对每个sections进行max pooling操作;
这样就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
而Faster R-CNN相对于其前辈Fast R-CNN的最大改进就是使用RPN来生成候选区域,摒弃了selective search算法,即完全使用CNN解决目标检测任务,同时整个过程都能跑在GPU上,之前selective search仅在CPU上跑,是耗时的一大瓶颈。
内容来自于:https://mp.weixin.qq.com/s/yMg_WNMQwpjcJgZYwvzXjA
对比一下R-CNN,Fast R-CNN,Faster R-CNN
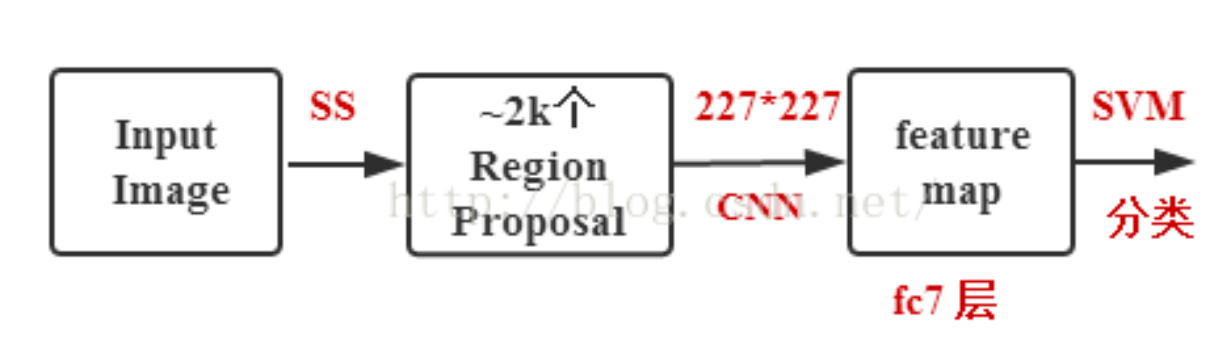
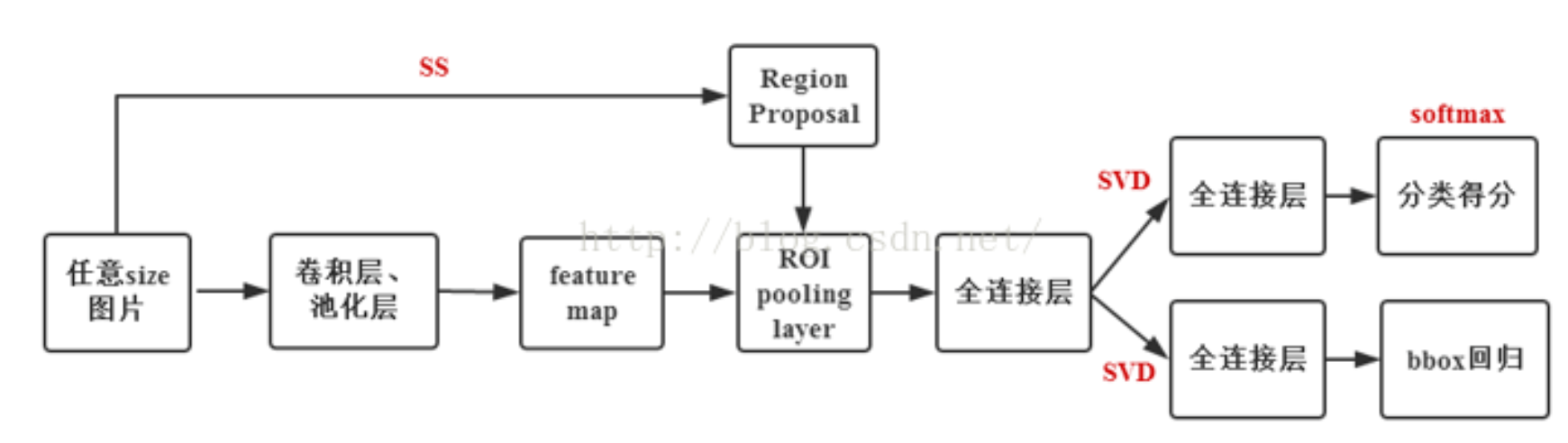
Fast R-CNN的RegionProposal是在feature map之后做的,这样可以不用对所有的区域进行单独的CNN Forward步骤。
Fast R-CNN框架与R-CNN有两处不同:
① 最后一个卷积层后加了一个ROI pooling layer;
② 损失函数使用了multi-task loss(多任务损失)函数,将边框回归直接加到CNN网络中训练。分类Fast R-CNN直接用softmax替代R-CNN用的SVM进行分类。
Fast R-CNN是端到端(end-to-end)的。
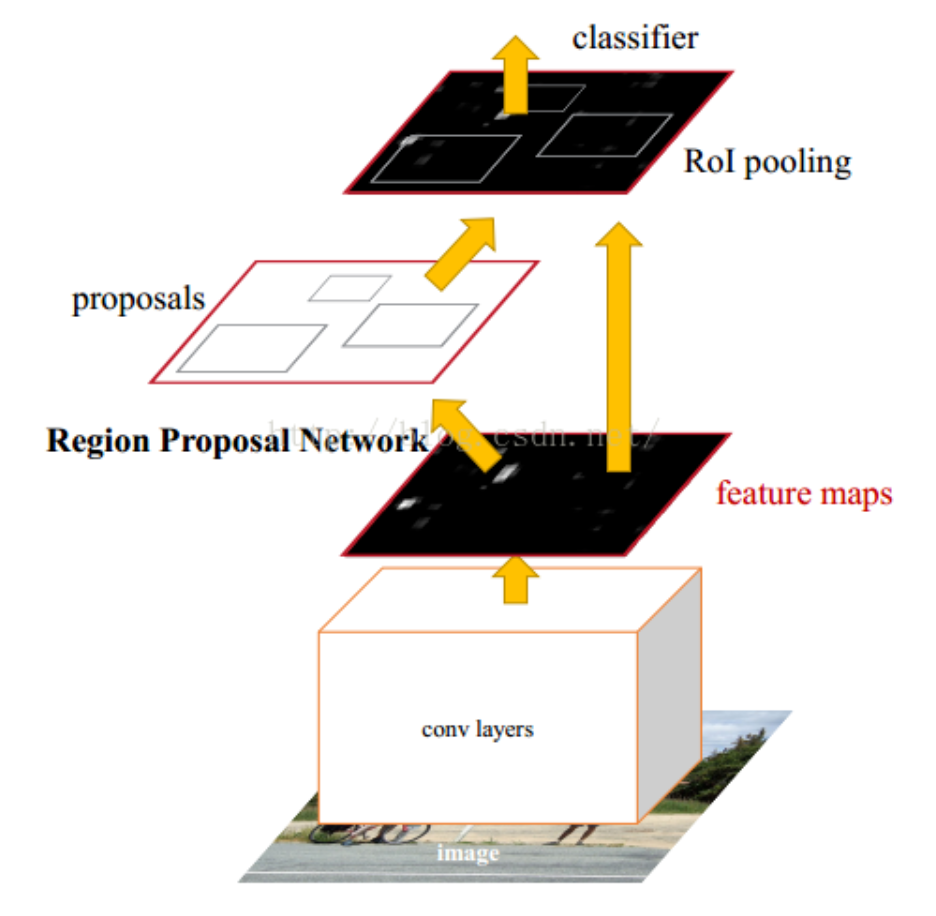

Faster-R-CNN算法由两大模块组成:
1.PRN候选框提取模块;
2.Fast R-CNN检测模块。
其中,RPN是全卷积神经网络,用于提取候选框;Fast R-CNN基于RPN提取的proposal检测并识别proposal中的目标。
fasterRCNN代码:resnet50fpn_fasterRCNN,resnet50_fasterRCNN,mobilenetv2_fasterRCNN
 View Code
View Code接着来说一哈
Backbone与Detection head
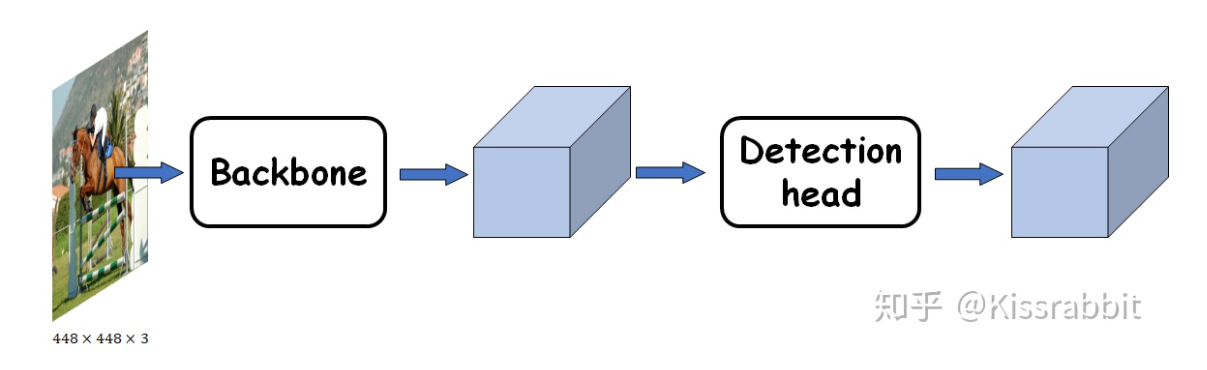
一个分类器:detector=backbone+neck+head
backbone:特征提取
head:实现对物体的定位和分类
neck:这部分的作用就是更好地融合/提取backbone所给出的feature,然后再交由后续的head去检测,从而提高网络的性能
具体参考:https://zhuanlan.zhihu.com/p/93451942
Facebook AI的DETR,一种基于Transformer的目标检测方法
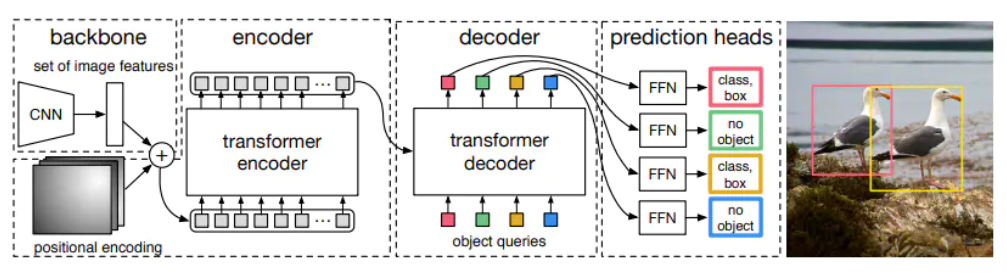
DETR的体系结构
实际上,整个DETR架构很容易理解。它包含三个主要组件:
- CNN骨干网
- 编码器-解码器transformer
- 一个简单的前馈网络
首先,CNN骨干网从输入图像生成特征图。
然后,将CNN骨干网的输出转换为一维特征图,并将其作为输入传递到Transformer编码器。该编码器的输出是N个固定长度的嵌入(向量),其中N是模型假设的图像中的对象数。
Transformer解码器借助自身和编码器-解码器注意机制将这些嵌入解码为边界框坐标。
最后,前馈神经网络预测边界框的标准化中心坐标,高度和宽度,而线性层使用softmax函数预测类别标签。