首先用一张表来总说对比
注:pattern 为RegExp的实例, str 为String的实例
| 用法 | 说明 | 返回值 |
|---|---|---|
| pattern.test(str) | 判断str是否包含匹配结果 | 包含返回true,不包含返回false。 |
| pattern.exec(str) | 根据pattern对str进行正则匹配 | 返回匹配结果数组,如匹配不到返回null |
| str.match(pattern) | 根据pattern对str进行正则匹配 | 返回匹配结果数组,如匹配不到返回null |
| str.replace(pattern, replacement) | 根据pattern进行正则匹配,把匹配结果替换为replacement | 一个新的字符串 |
要注意的是:test和exec是正则表达式对象的操作方法,match和replace是字符串的操作方法
另外,这里插入一点,md的表格语法
Markdown 制作表格使用 | 来分隔不同的单元格,使用 - 来分隔表头和其他行。
语法如下:
| 表头 | 表头 |
| ---- | ---- |
| 单元格 | 单元格 |
| 单元格 | 单元格 |
很多教程,都会遗忘一点,什么叫正则实例,首先要弄清正则对象
var reg = /d+/;
//使用dir函数,来查看reg的类型
console.dir(reg)
查看输出结果,完全的了解正则对象
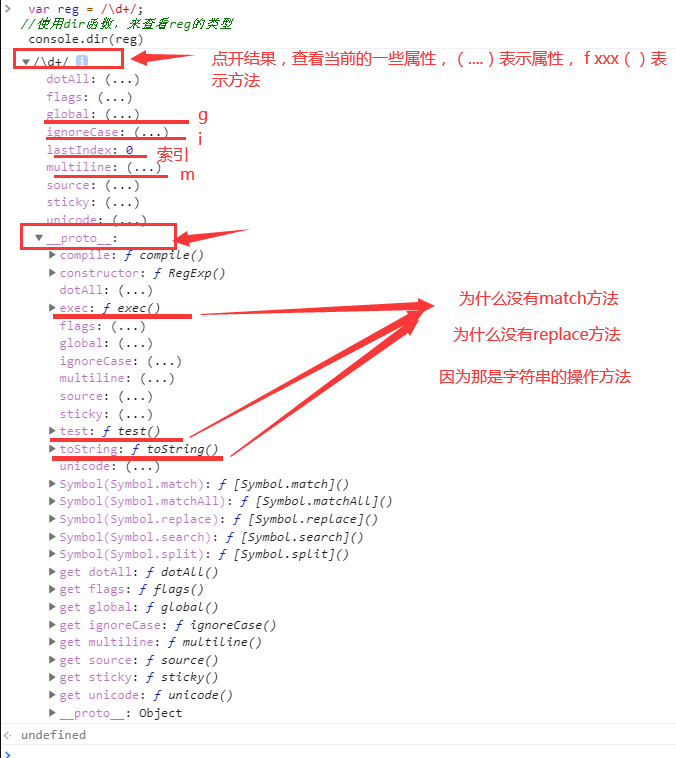
其他三个函数,比较简单吧,这里主要研究 exec方法
首先,语法和中文意思:
reg.exec(str) 就是正则对象,去捕获一个字符串,返回一个数组,数组包含四部分,还是打印一下吧。哦,还是看别人写的优秀教程吧。
exec: 正则捕获
每一次捕获的时候,都是先进行默认的匹配,如果没有匹配成功的,捕获的结果是null;只有有匹配的内容,我们才能捕获到,捕获到的内容是一个数组。
捕获的内容格式
- 捕获的内容是一个数组。
数组中的第一项是当前大正则捕获的内容。
index: 捕获内容在字符串中开始的索引位置。
input: 捕获的原始字符串。
var reg = /d+/;
var str = "derrickrose";
var res = reg.exec(str);
console.log(res); // null
var str = "derrick20rose21";
var res = reg.exec(str);
console.log(res); // [0:"20", index:7, input: "derrick20rose21"]
console.log(reg.lastIndex); // 0
// 第二次通过exec捕获的内容还是第一个内容
var res = reg.exec(str);
console.log(res); // [0:"20", index:7, input: "derrick20rose21"]
console.log(reg.lastIndex); // 0, 说明第二次捕获的时候也是从字符串索引0处开始查找的
正则捕获的特点
- 懒惰性 -> 每一次执行exec,只捕获第一个匹配的内容,在不经过任何处理的情况下,在执行多次捕获后,匹配的还是第一个内容。
lastIndex: 是正则每一次捕获在字符串中开始查找的位置,默认值是0。 - 如何解决懒惰型?-> 在正则的末尾加一个修饰符 "g"。
修饰符: g, i, m:
global(g): 全局匹配。
ignoreCase(i): 忽略大小写匹配。
multiline(m): 多行匹配。
原理: 加了全局修饰符"g",正则每一次捕获结束后,lastIndex的值都变为了最新的值,下一次捕获从最新的位置开始查找,这样就可以把所有需要捕获的内容都获取到了。
var reg = /d+/g;
var str = "derrick20rose21";
console.log(reg.lastIndex); // 0
console.log(reg.exec(str)); // ["20..
console.log(reg.lastIndex); // 9
console.log(reg.exec(str)); // ["21..
console.log(reg.lastIndex); // 15
console.log(reg.exec(str)); // null
- 自己编写程序,获得正则的所有内容,注意,一定不要忘记加 "g"。
var reg = /d+/g;
var str = "derrick20rose21";
var ary = [];
var res = reg.exec(str);
while (res) {
ary.push(res[0]);
res = reg.exec(str);
}
console.log(ary);
- 贪婪性:正则每一次捕获都是按照都是按照最长的结果来捕获的,例如2符合正则,20也符合正则,但是默认的捕获的是20。
var reg = /d+/g; // -> 出现1到第一个0-9之间的数字
var str = "derrick20rose21";
console.log(reg.exec(str)); // ["20".....]
- 如何解决正则的贪婪性 -> 在量词元字符后面添加一个 ? 即可。
? 在正则中有很多的作用:
放在一个普通的元字符后面,代表出现0-1次 /d?/ 出现0-1次数字 -> 数字可能出现也可能不出现。
放在一个量词元字符后面是取消捕获时候的贪婪性。
var reg = /d+?/g;
var str = "derrick20rose21";
console.log(reg.exec(str)); // ["2".....]
var ary = [];
var res = reg.exec(str);
while (res) {
ary.push(res[0]);
res = reg.exec(str);
}
console.log(ary);
字符串中的match方法 -> 把所以和正则匹配的字符都获取到。
var reg = /d+?/g;
var str = "derrick20rose21";
var ary = str.match(reg);
console.log(ary);
虽然在当前的情况下,match比exec更加简洁,但是match中存在一些自己处理不了的问题: 在分组捕获到情况下,match只能捕获到大正则匹配的内容,而对于小正则捕获的内容是无法获取的。
分组捕获
正则分组:
- 改变优先级
- 分组引用
// 2 代表和第二个分组出现一模一样的内容
// 1 代表和第一个分组出现一模一样的内容
// 一模一样: 和对应的分组中的内容的值都要一样
var reg = /^(w)1(w)2$/;
console.log(reg.test("zzff")); // -> true
console.log(reg.test("z0f_")); // -> false
- 分组捕获 -> 正则在捕获的时候,不仅仅把大正则匹配的内容捕获到,而且还可以把小分组匹配的内容捕获到。
(?:)在分组中,?: 的意思是只匹配不捕获。
var reg = /^(d{2})(d{4})(d{4})(d{2})(?:d{2})(d)(?:d|X)$/;
var str = "122726188803810391";
console.log(reg.exec(str)); // -> ary = ["122726188803810391",...]
// 数组中的第一项ary[0]: 大正则匹配的内容
// ary[1]: -> 第一个分组捕获的内容
// ary[2]: -> 第二个分组捕获的内容
// ...
console.log(str.match(reg)); // -> match 和 exec获取的结果是一样的
var reg = /derrick(d+)/g;
var str = "derrick20rose30derrick40";
// 用exec执行三次,每一次不仅仅把大正则匹配的获取到,而且还可以获取第一个分组匹配的内容
console.log(reg.exec(str));
console.log(reg.exec(str));
console.log(reg.exec(str));
// 而match只能捕获大正则匹配的内容
console.log(str.match(reg));
作者:阿九是只大胖喵
链接:https://www.jianshu.com/p/6e77ac888147
来源:简书