1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
2.用logiftic回归来进行实践操作,数据不限。
1、逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?
(1)逻辑回归是怎么防止过拟合的?
1. 增加样本量,适用任何模型。
2. 如果数据稀疏,使用L1正则,其他情况,用L2要好,可自己尝试。
3. 通过特征选择,剔除一些不重要的特征,从而降低模型复杂度。
4. 检查业务逻辑,判断特征有效性,是否在用结果预测结果等。
5.逻辑回归特有的防止过拟合方法:进行离散化处理,所有特征都离散化。
正则化λλ设置得足够大,权重矩阵W被设置为接近于0的值。实际上是不会发生这种情况的,我们尝试消除或至少减少许多隐藏单元的影响,最终这个网络会变得更简单,这个神经网络越来越接近逻辑回归,我们直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了。神经网络变得更简单了,貌似这样更不容易发生过拟合。
2.用logiftic回归来进行实践操作
我们用泰坦尼克号的存活数据来体现
代码:
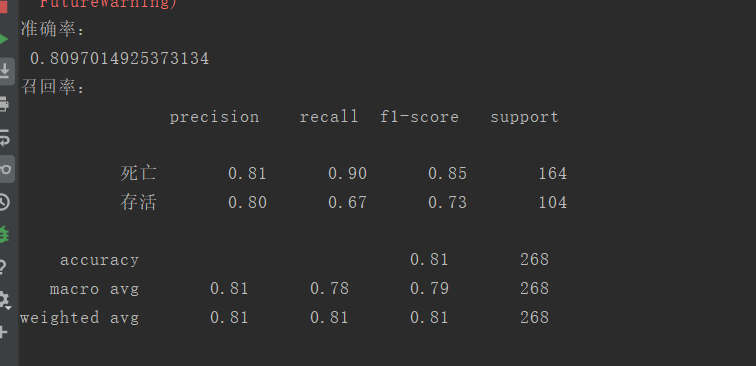
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import classification_report import pandas as pd # 读取titanic_data数据 data = pd.read_csv('./titanic_data.csv') # 数据预处理 data.drop('Age', axis=1, inplace=True)#删除Age这一列 data.drop('PassengerId', axis=1, inplace=True) # 删除PassengerId这一列 data.loc[data['Sex'] == 'male', 'Sex'] = 1 data.loc[data['Sex'] == 'female', 'Sex'] = 0 # 数据分割 x_data = data.iloc[:, 1:] y_data = data.iloc[:, 0] x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3) # 进行标准化处理 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) # 构建和训练模型 LR_model = LogisticRegression() LR_model .fit(x_train, y_train)#训练 LR_model_predict = LR_model.predict(x_test) print('准确率: ', LR_model.score(x_test, y_test)) print('召回率: ', classification_report(y_test, LR_model_predict, labels=[0, 1], target_names=['死亡', '存活']))
运行截图: