目录
前言
在libevent中使用到了TAILQ数据结构,看了一下其他资料,发现TAILQ这一数据结构不仅仅用于libevent中,在很多其他地方像linux内核中也有使用。它的内部实际上就是一个双向链表,可以实现结点的插入(头插、尾插、指定位置插入)、删除、替换和遍历等功能,不过所有功能都是通过宏函数来实现的,有的地方还是比较难以理解的,下面就来分析一下这一数据结构。
结点定义
TAILQ中涉及到了两个很关键的结构体,如下所示:(queue.h)
-
#define TAILQ_HEAD(name, type)
-
struct name {
-
struct type *tqh_first; /* first element */
-
struct type **tqh_last; /* addr of last next element */
-
}
-
#define TAILQ_ENTRY(type)
-
struct {
-
struct type *tqe_next; /* next element */
-
struct type **tqe_prev; /* address of previous next element */
-
}
先来猜测一下这两个宏定义的作用。在宏定义TAILQ_HEAD下的结构体中,包含了两个结构体成员tqh_first和tqh_last,先不管它们是几级指针,从成员名就能推测,tqh_first应当是和链表第一个元素有关,而tqh_last则和链表最后一个元素相关。再来看宏定义TAILQ_ENTRY,其中也包含了两个结构体成员tqe_next和tqe_prev,从变量名就会发现,二者应当与前后元素相关,这实际上和双向链表中的结点定义是非常相似的。因此,就可以推断,宏定义中所需输入的参数type实际上就是结点类型,这个结点类型应该包含但不限于TAILQ_ENTRY所定义的结构,而TAILQ_HEAD则是对于整个双向链表而言的,用于找到首尾结点元素,因此TAILQ_HEAD中的type也应该是与TAILQ_ENTRY中相同的结点类型。
那么这里为什么TAILQ_HEAD还需要一个参数name呢?前面说了,TAILQ_ENTRY应当包含在结点类型的定义中,结点类型一旦定义好了并定义了一个结点,那么自然而然tqe_next和tqe_prev就都包含在该结点中了,此时TAILQ_ENTRY结构体作为一个匿名结构体即可,因此无需指定name来定义TAILQ_ENTRY结构体的名称;而对于TAILQ_HEAD来说,它是独立的数据类型,用来描述了双向链表的首尾结点,需要用TAILQ_HEAD来定义一个具体的结构体来存放首尾结点指针,因此这里必须指明结构体名name。
根据前面的推测,现在来正式分析一下TAILQ_HEAD与TAILQ_ENTRY中各成员的含义。
对于TAILQ_HEAD宏定义,其中的tqh_first为一级指针,tqh_last为二级指针,也就是说,tqh_first指向一个struct type类型的结点,而tqh_last则是指向一个指向一个struct type类型的结点的指针。TAILQ_ENTRY中的tqe_next和tqe_prev也是类似,这里就不多说了。那么到底各自指向什么呢?如果光是通过代码来推测一级、二级指针各自指向什么,我觉得太麻烦,因此我直接写一个程序先来看看结果如何:
-
-
-
-
using namespace std;
-
-
struct Entry //结点类型
-
{
-
int val;
-
TAILQ_ENTRY(Entry)entry;
-
};
-
-
TAILQ_HEAD(Head, Entry); //名为Head的结构体,指向首尾Entry类型的结点
-
-
int _tmain(int argc, _TCHAR* argv[])
-
{
-
Head Head_h;
-
TAILQ_INIT(&Head_h);
-
-
for (int i = 0; i < 3; i++)
-
{
-
Entry * new_item = (Entry *)malloc(sizeof(Entry));
-
new_item->val = i;
-
TAILQ_INSERT_HEAD(&Head_h, new_item, entry); //头插法插入新结点
-
}
-
Entry* p; //用于遍历时保存当前结点
-
int i = 0;
-
-
cout << "first : " << Head_h.tqh_first << " first addr : " << &Head_h.tqh_first << endl << endl; //打印first的值以及first的地址
-
TAILQ_FOREACH(p, &Head_h, entry) //遍历链表
-
{
-
cout << "Node " << i++ << " addr : " << p << endl; //打印结点地址
-
cout << "prev : " << p->entry.tqe_prev << " prev addr : " << &p->entry.tqe_prev << endl; //打印prev的值以及prev地址
-
cout << "next : " << p->entry.tqe_next << " next addr : " << &p->entry.tqe_next << endl << endl; //打印next的值以及next的地址
-
}
-
cout << "last : " << Head_h.tqh_last << " last addr : " << &Head_h.tqh_last << endl; //打印last的值以及last的地址
-
-
system("pause");
-
return 0;
-
}
在该程序中,定义了结点类型为Entry类型,其中包含了一个int型的val变量以及TAILQ_ENTRY所定义的结构体。可以看到,调用TAILQ_HEAD宏函数时,传入的name参数Head最终就成为了TAILQ_HEAD下结构体类型名。然后用Head来定义一个Head_h变量,其中保存的即是双向链表中的首尾结点信息了。接着就是以头插法形式插入三个结点,然后遍历输出各个结点中关键成员的值与地址,结果如下:

通过程序结果显示,可以得出以下结论:
对于每个结点,其prev的值等于前一个结点的next的地址,而next的值则等于下一个结点的地址,换句话说,每个结点的prev二级指针实际上是指向前一个结点的next一级指针变量,而next一级指针则是指向下一个结点;
类似的,first一级指针指向第一个结点,第一个结点的prev二级指针指向first一级指针变量;
last二级指针则是指向最后一个结点的next一级指针变量。
通过一幅图来表达即是:(紫色框表示一个结点,蓝色线表示prev指针指向,绿色线表示next指针指向,黑色线表示first、last指针指向)

从图中可以看出,我们可以将first和last所组成的结构体看做‘头结点’,它与第一个结点相连的同时也指向了最后一个结点的next指针。到此,也就搞清楚了每个指针的指向,接下来看一下TAILQ_QUEUE是如何进行链表操作的。
注:以下将含first以及last指针的变量称为'头结点',将实际意义上的第一个结点称为'首结点'。
链表初始化
链表初始化使用的宏函数为TAILQ_INIT,其定义如下:
-
-
(head)->tqh_first = NULL;
-
(head)->tqh_last = &(head)->tqh_first;
-
} while (0)
链表的初始化实际上只是初始化了‘头结点’,由于头结点的first与首结点相连,而此时链表为空,因此将头结点的first置为NULL,然后将last指针指向了first。这样初始化可以避免尾插结点时对特殊情况进行处理。多次使用的‘->’表明该宏函数传入的参数应当为指向头结点的指针。
链表查询及遍历
链表查询
TAILQ中关于结点的查询的宏定义有以下几种:
-
-
-
-
-
(*(((struct headname *)((head)->tqh_last))->tqh_last))
-
-
/* XXX */
-
-
(*(((struct headname *)((elm)->field.tqe_prev))->tqh_last))
-
-
(TAILQ_FIRST(head) == TAILQ_END(head))
TAILQ_FIRST以及TAILQ_END就不用多说了。TAILQ_NEXT中涉及到了一个参数field,它的意义实际上就像前文例程中定义结点类型Entry中TAILQ_ENTRY型的变量名entry一样,用来访问匿名子结构体成员。如下所示:
struct Entry //结点类型
{
int val;
TAILQ_ENTRY(Entry)entry;
};
这里表示entry是一个拥有first和last两个成员变量的结构体变量,如果这里不定义一个变量entry,那么也就无法访问到结点中的first和last指针,而定义一个entry后,则可以根据entry来访问first和last指针了。因此TAILQ_NEXT中的field参数应当为定义结点结构体时,TAILQ_ENTRY结构体类型的变量。由此可见,一旦需要用到first和last指针,那么就应当传入field参数。
TAILQ_LAST宏函数用于返回尾结点的地址。但是现在关于尾结点只有一个last指针,如何通过last指针获得尾结点的地址呢?回过头继续看这副图:
由图可知,通过last指针只能获得尾结点的next指针的地址,并非是尾结点的地址,而指向尾结点的指针只有前一个结点的next指针,而尾结点的prev指针又刚好指向前一个结点的next指针,也就是说,对于尾结点,prev存放的是前一个结点的next指针的地址,那么(*prev)即是前一个结点的next指针值,而前一个结点的next指针值就是当前结点的地址,因此,(*prev)就是尾结点的地址了,因此现在的问题变成了如何通过last来找到prev。
这里采用的方法是先将last强制转换为头结点类型,由于在内存中next的后面放的是prev,两个指针变量都占8个字节(64位),同样的头结点中的first也是放在last的前面,各自也是占8个字节,因此如果将next和prev看做一个整体,那么其在内存中的布局必定与头结点类型中的first和last内存布局一致。因此通过(struct headname*)last将last指针强制转换为头结点类型后,(struct headname*)last->first实际上还是next,而(struct headname*)last->last则是prev,这样也就通过last找到了prev。
不得不说这种方法很巧妙,我个人一开始想到的办法是直接通过next的地址偏移sizeof(struct headname*)来找到prev,不过这样的话就可能受到内存对齐的影响(比如内存按16字节对齐,那么偏移值应当为16,但是sizeof的大小为4(32bit)或8(64bit),这样就是错误的,并且如果不同的编译器下结果都可能不一样),而这里的方法是直接强制转换为另一个内存布局相同的类型,这样即使在不同环境下内存对齐情况不同,对强转前后两种类型的影响也必定是相同的,二者的内存布局依然相同。
因此现在要根据last来得到尾结点的地址就很简单了,(*prev)找到尾结点地址,为(struct headname*)last->last则是prev的值,替换一下就是*(struct headname*)last->last,将其写规范,即为(*(((struct headname *)((head)->tqh_last))->tqh_last))。
TAILQ_PREV宏函数用于找到前一个结点的地址,其原理与TAILQ_LAST类似,不过需要注意的是,这里传入的参数是当前结点地址,如上图所示,要找到前一个结点的地址,也就是要找到前一个结点的前一个结点的next指针地址,因此先用当前结点的prev找到前一个结点的next指针地址,强转后就可以找到前一个结点的prev指针,通过前一个结点的prev也就能找到前一个结点的前一个结点的next指针了,这样前一个结点的地址也就出来了。
TAILQ_EMPTY用于判断链表是否为空,由于first和last分别为链表的首结点地址以及尾结点的next地址,因此当first为NULL时也就表示整个链表为空了。
链表遍历
链表遍历分为正向遍历和反向遍历,有了上面对链表查询的分析,以下的代码应当非常容易理解了。
-
-
for((var) = TAILQ_FIRST(head);
-
(var) != TAILQ_END(head);
-
(var) = TAILQ_NEXT(var, field))
-
-
-
for((var) = TAILQ_LAST(head, headname);
-
(var) != TAILQ_END(head);
-
(var) = TAILQ_PREV(var, headname, field))
在500万个结点的情况下分别正向、反向遍历,遍历用时如下:
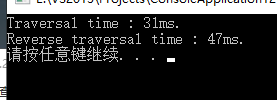
可以发现正向遍历的效率更高,原因在于逆向遍历中的TAILQ_PREV需要进行两次寻址,而正向遍历中的TAILQ_NEXT则只需要进行一次寻址,因此对于数据量大的时候,TAILQ_PREV会明显比TAILQ_NEXT更慢。
插入结点
TAILQ插入结点的方式有4种,分别为头插法TAILQ_INSERT_HEAD、尾插法TAILQ_INSERT_TAIL、前插法TAILQ_INSERT_BEFORE和后插法TAILQ_INSERT_AFTER。
头插法
在分析TAILQ_INSERT_HEAD之前,先来思考一下当在链表头部插入结点时会发生什么:
如下图所示,4号结点是新插入的结点,虚线为插入新结点时需要发生变化的线。
首先第一步是新结点的next应当指向原来的首结点,如图中的绿色虚线;
第二步是将原来的首结点的prev从指向first改为指向新结点的next指针,如图中的蓝色虚线;
第三步是将first指针从指向原来首结点改为指向新结点,如图中黑色虚线;
第四步是将新结点的prev指针指向first,如图蓝色虚线。
在这四步,必须保证第一步在第三步之前,因为第一步中找到原来的首结点时是需要first指向首结点来找到首结点。
当然也会有特殊情况,比如当前链表为空,此时插入一个新结点的话,由于不存在“原来的首结点”,因此第二步应该取消,取而代之的应该是将last指针指向新结点的next指针。

头插法TAILQ_INSERT_HEAD宏函数定义如下:
-
-
if (((elm)->field.tqe_next = (head)->tqh_first) != NULL) //如果头结点不为NULL,说明此时链表不为空,同时将新结点elm的next指向当前的头结点
-
(head)->tqh_first->field.tqe_prev = //将原来的首结点的prev指向新结点的next
-
&(elm)->field.tqe_next;
-
else //如果头结点为NULL,说明此时链表为空
-
(head)->tqh_last = &(elm)->field.tqe_next; //last指向新结点的next
-
(head)->tqh_first = (elm); //重新将first指向新结点
-
(elm)->field.tqe_prev = &(head)->tqh_first; //新结点的prev指向first
-
} while (0)
该函数的执行逻辑与前面所说的四步完全一样,这里就不多说了。
尾插法
再来看看从链表尾部插入一个结点时会发生什么:
如下图所示,第一步是先将新结点的next置为NULL;
第二步是将新结点的prev通过last指针指向原来的尾结点的next;
第三步是将原来的尾结点的next由原来的NULL值变为指向新结点;
第四步是将last指针由原来指向原尾结点的next改为指向新结点的next。
再来考虑特殊情况:如果链表本身为空,那么就不存在“原来的尾结点”了,第三步改为first指针指向新结点即可。

尾插法TAILQ_INSERT_TAIL宏函数定义如下:
-
-
(elm)->field.tqe_next = NULL; //将待插入结点的next置为NULL
-
(elm)->field.tqe_prev = (head)->tqh_last; //将待插入结点的prev指针指向当前的last结点地址
-
*(head)->tqh_last = (elm); //将last指向的结点设置为elm
-
(head)->tqh_last = &(elm)->field.tqe_next;
-
} while (0)
在该函数中,基本上是符合前面所说四步的,不过需要注意的是,在第二步中,本身是需要将新结点的prev指向原来尾结点的next,而原来尾结点的next又刚好就是last指针的指向,因此直接将last赋值给prev即可,这样也可以兼容链表为空的情况(链表为空时last是指向first的,此时prev就指向了first);在第三步中,对last进行解引用,由此此时的last指向的是原来尾结点的next,因此*last实际上就是原尾结点的next的值,将新结点的指针(elm)赋值给*last,也就是相当于将原尾结点的next指向了新结点。即使是链表为空,此时的*last也就是first的值,*last = elm即是让first指向了新结点,这样也就兼容了链表为空的情况。
由此可以看出,保证last二级指针在链表为空的情况下指向first是非常重要的,这样可以巧妙地避免链表为空的特殊情况。如果用一般的一级指针,则需要先对链表是否为空进行判断。
前插法
前插法TAILQ_INSERT_BEFORE的宏定义如下:
-
-
-
(elm)->field.tqe_next = (listelm); //新结点的next指向原结点
-
*(listelm)->field.tqe_prev = (elm); //让本该指向原结点的指针指向新结点
-
(listelm)->field.tqe_prev = &(elm)->field.tqe_next; //原结点的prev指向新结点的next
-
} while (0)
可以看到,这里的前插法代码并没有对特殊情况进行特殊处理,前插的特殊情况即是前插的原结点本身就是首结点,此时进行前插就相当于头插。
第一步将新结点的prev指向原结点prev指向的地方,即使链表中只有一个结点,那么新结点的prev指向头结点的first也是没有问题的;第二步将新结点的next指向原结点;第三步中先对原结点的prev解引用,得到的实际上是指向原结点自身的指针,这也是prev作为二级指针指向前一个结点的next指针的好处:*prev是指向当前结点的指针,将elm赋值给*prev的意义,就相当于是将原本该指向原结点的指针让其指向新结点,这样也就避免了特殊情况的处理;最后一步是让原结点的prev指向新结点的next。从而完成结点的前插。
后插法
后插法TAILQ_INSERT_AFTER的宏定义如下:其中head为头结点指针,listelm为原结点,elm为插入结点
-
-
-
(elm)->field.tqe_next->field.tqe_prev = //原结点不是尾结点,就将原结点的后一个结点的prev指向新结点的next
-
&(elm)->field.tqe_next;
-
else //在尾结点后面插入新结点
-
(head)->tqh_last = &(elm)->field.tqe_next; //last指针指向新结点的next
-
(listelm)->field.tqe_next = (elm); //原结点的next指向新结点
-
(elm)->field.tqe_prev = &(listelm)->field.tqe_next; //新结点的prev指向原结点的next
-
} while (0)
后插法需要判断特殊情况,看注释即可。
删除结点
删除节点TAILQ_REMOVE的宏定义如下:
-
-
-
(elm)->field.tqe_next->field.tqe_prev = //让删除结点的下一个结点的prev指向删除结点的前一个结点
-
(elm)->field.tqe_prev;
-
else //删除尾结点
-
(head)->tqh_last = (elm)->field.tqe_prev; //last指向删除结点的prev
-
*(elm)->field.tqe_prev = (elm)->field.tqe_next; //原本应当指向删除结点的指针指向删除结点的next
-
} while (0)
需要注意的是,如果链表中只剩一个结点,当删除这个结点后,由于last会重新指向被删除结点的prev,而该结点的prev必定是指向first的,这样又使得删除结点后的空链表回到最初状态last指向first。
替换结点
替换结点TAILQ_REPLACE的宏定义如下:其中head为头结点指针,elm、elm2分别为被替换结点以及新结点
-
-
if (((elm2)->field.tqe_next = (elm)->field.tqe_next) != NULL) //将被替换结点的next赋值给新结点的next,如果被替换的结点不是尾结点
-
(elm2)->field.tqe_next->field.tqe_prev = //将被替换结点的下一个结点的prev指向新结点的next
-
&(elm2)->field.tqe_next;
-
else //被替换结点为尾结点
-
(head)->tqh_last = &(elm2)->field.tqe_next; //last指向新结点的next
-
(elm2)->field.tqe_prev = (elm)->field.tqe_prev; //被替换结点的prev赋值给新结点的prev
-
*(elm2)->field.tqe_prev = (elm2); //原本指向被替换结点的指针指向新结点
-
} while (0)
总结
TAILQ_QUEUE的本质依然是双向链表,为双向链表定义一个头结点是非常重要的,如果没有头结点,那么在删除或插入结点时还需要去判断结点是否为首结点,以此来处理“当前结点为首结点”的特殊情况;而如果有头结点,那么就完全不用考虑这种特殊情况,因为头结点是必定存在的,即使链表为空它也会在那,如果链表不为空,头结点就会与第一个结点连接起来,逻辑上的第一个结点就称为了物理上的第二个结点,其prev指针是有意义的,这样就可以按照处理普通结点的方式去处理“第一个结点”。头结点的好处在TAILQ_QUEUE中仍然存在,从TAILQ_QUEUE中定义的各个宏函数中可以发现,特殊情况只有链表为空和所处理的结点为尾结点两种情况,完全避免了处理首结点的特殊情况。
实际上,将prev和last定义为一级指针也完全可以避免处理首结点特殊情况,那为什么还要将prev和last定义为二级指针呢?
在一级指针中之所以可以避免处理头结点的特殊情况,是因为头结点与普通结点的类型是完全一样的,因此第一个结点的prev可以直接指向头结点,而在TAILQ中的头结点类型和普通结点类型不一样。在TAILQ中,头结点只定义了两个变量用来找到第一个和最后一个结点,而对于普通结点而言,不光需要找到前驱结点和后驱结点,还需要有结点自身的一些属性(比如说data等等)(当然这里你也可以为头结点强行加上一个变量让它和普通结点类型保持一致,但是TAILQ中并没有这么做)。
在这种头结点类型和普通结点类型不一致的情况下,第一个结点的prev是无法直接指向头结点的,因此就只能让第一个结点的prev指向头结点的first指针(first依然保留一级指针),不过这样一来,第一个结点的prev就变成二级指针了,因此普通结点的prev就应当定义为二级指针了。此时对于普通结点而言,prev为二级指针,next是一级指针,那么prev就应当指向前一个结点的next指针。而将头结点的last也定义为二级指针主要是为了方便用于寻找某一个结点的前一个结点时的类型转换。
转载自:https://blog.csdn.net/qq_28114615/article/details/92777004