一、前言
Elasticsearch 底层依赖于 Lucene 库,而 Lucene 库完全是 Java 编写的,前面的文章都是发送的 RESTful API 请求,其实这些请求最后还是通过 Java 执行的。RESTful API 能做的 Java API 都能做,Java API 比 RESTful API 功能更强大。
1.1 Elasticsearch API 的简单使用方式
1)非客户端方式:通过 HTTP 方式的 JSON 格式进行调用,关于 HTTP 的相关参数可以在 elasticsearch.yml 中设置(出于安全考虑,也可禁用 HTTP 接口,只需在配置文件中将 http.enabled 设置为 false 即可)。
2)客户端方式:对于 Java 来说,Elasticsearch 内置了传输客户端 TransportClient,它是一种轻量型的传输客户端,可被用来向远程集群发送请求。它不加入集群本身,而是把请求转发到集群中的节点上。客户端都使用 Elasticsearch 的传输协议,通过 9300 端口与 Java 客户端进行通信,集群中的各个节点也是通过 9300 端口进行通信。
注意:Elasticsearch 的 9200 端口是 HTTP 端口,9300 端口是 Transport 端口。
Elastic Stack 产品官方参考文档:https://www.elastic.co/guide/index.html
Elasticsearch Clients 客户端参考文档:https://www.elastic.co/guide/en/elasticsearch/client/index.html,可以看出,Elasticsearch 不仅提供了 Java 客户端方式,还提供了其他常见语言客户端的方式,如:Python,Perl,Ruby,JavaScript,Groovy,PHP 等。
Java 客户端目前主要提供两种方式,分别是 Java API 和 Java REST Client:
Java API:https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/index.html,其使用的核心传输对象是 TransportClient。但是 Elastic 官方已经计划在 Elasticsearch 7.0 中废弃 TransportClient,并在 8.0 中完全移除它,并由 Java High Level REST Client 代替。官网声明如下:https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/client.html
Java REST Client:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/index.html,Java REST Client 又分为两种,Java Low Level REST Client 和 Java High Level REST Client。目前官方推荐使用 Java High Level REST Client。
二、搜索过程详解
此处我们依然使用上面提到的 Java API,这也是目前使用最广泛的 Java 客户端。
2.1 添加 Java 客户端 Maven 依赖
根据自己的 Elasticsearch 版本,选择 TransportClient 的版本,此处我们使用的是 5.6.0。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com</groupId> <artifactId>esjavaapi</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>esjavaapi</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>5.6.0</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-api</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> </dependencies> </project>
并添加相应的 log4j 的依赖,用于日志输出。
2.2 Java 客户端实现代码
创建客户端连接Elasticsearch集群,如下:
package tup.es.client; import java.net.InetAddress; import java.net.UnknownHostException; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.InetSocketTransportAddress; import org.elasticsearch.transport.client.PreBuiltTransportClient; public class EsUtils { public static String CLUSTER_NAME = "Banon";//Elasticsearch集群名称 public static String HOST_IP = "192.168.56.110";//Elasticsearch集群节点 public static int TCP_PORT = 9300;//Elasticsearch节点TCP通讯端口 private volatile static TransportClient client;//客户端对象,用于连接到Elasticsearch集群 /** * Elasticsearch Java API 的相关操作都是通过TransportClient对象与Elasticsearch集群进行交互的。 * 为了避免每次请求都创建一个新的TransportClient对象,可以封装一个双重加锁单例模式返回TransportClient对象。 * 即同时使用volatile和synchronized。volatile是Java提供的一种轻量级的同步机制,synchronized通常称为重量级同步锁。 * @author moonxy */ public static TransportClient getSingleTransportClient() { Settings settings = Settings.builder().put("cluster.name", CLUSTER_NAME).build(); try { if(client == null) { synchronized(TransportClient.class) { client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(HOST_IP), TCP_PORT)); } } } catch (UnknownHostException e) { e.printStackTrace(); } return client; } //测试入口 public static void main(String[] args) throws UnknownHostException { TransportClient client = EsUtils.getSingleTransportClient(); GetResponse getResponse = client.prepareGet("books", "IT", "1").get(); System.out.println(getResponse.getSourceAsString()); } }
检索文档并返回:
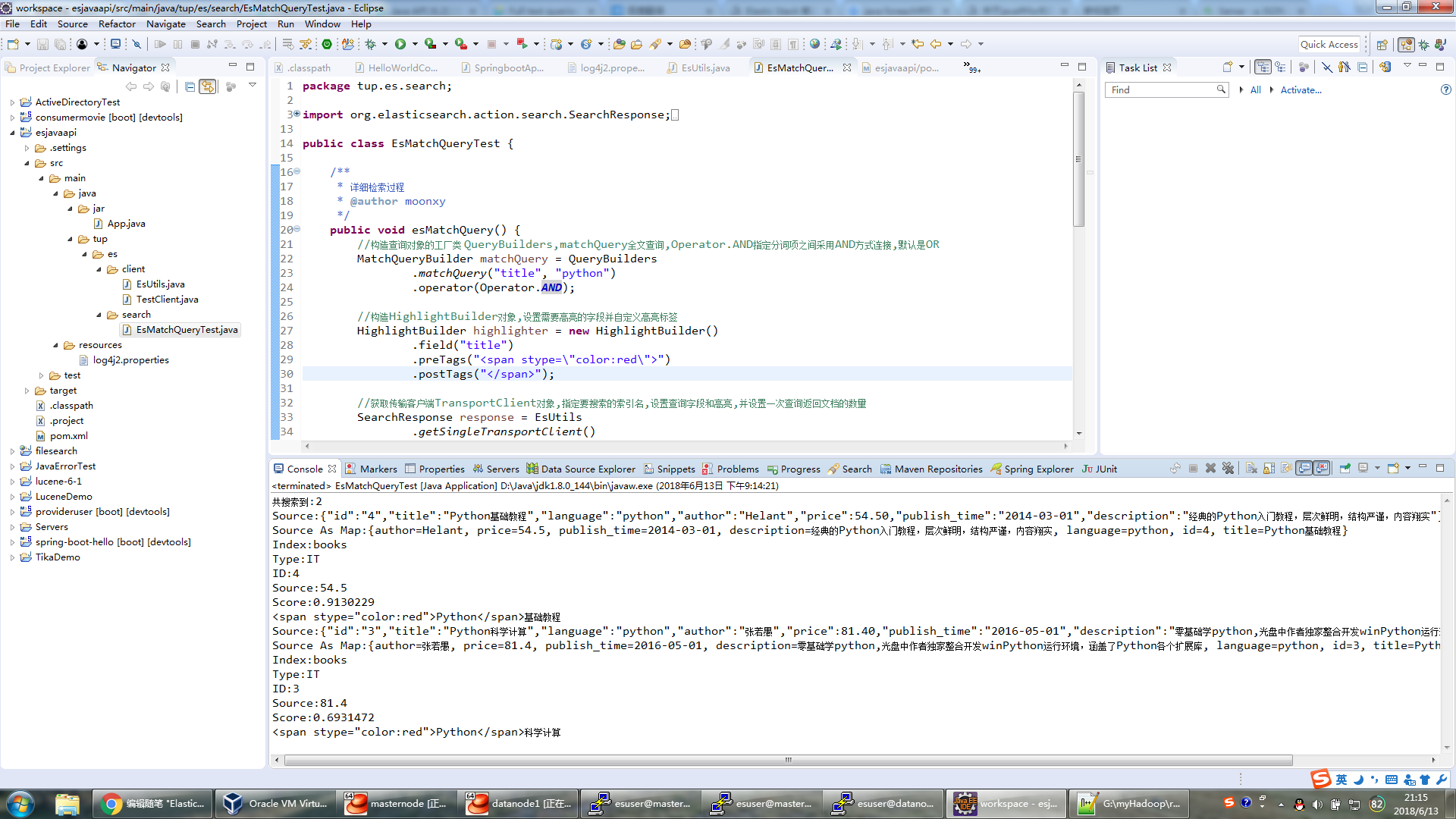
package tup.es.search; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.common.text.Text; import org.elasticsearch.index.query.MatchQueryBuilder; import org.elasticsearch.index.query.Operator; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import tup.es.client.EsUtils; public class EsMatchQueryTest { /** * 详细检索过程 * @author moonxy */ public void esMatchQuery() { //构造查询对象的工厂类 QueryBuilders,matchQuery全文查询,Operator.AND指定分词项之间采用AND方式连接,默认是OR MatchQueryBuilder matchQuery = QueryBuilders .matchQuery("title", "python") .operator(Operator.AND); //构造HighlightBuilder对象,设置需要高亮的字段并自定义高亮标签 HighlightBuilder highlighter = new HighlightBuilder() .field("title") .preTags("<span stype="color:red">") .postTags("</span>"); //获取传输客户端TransportClient对象,指定要搜索的索引名,设置查询字段和高亮,并设置一次查询返回文档的数量 SearchResponse response = EsUtils .getSingleTransportClient() .prepareSearch("books") .setQuery(matchQuery) .highlighter(highlighter) .setSize(100) .get(); //通过上面获得的SearchResponse对象,取得返回结果 SearchHits hits = response.getHits(); //搜索到的结果数 System.out.println("共搜索到:" + hits.getTotalHits()); //遍历SearchHits数组 for (SearchHit hit : hits) { System.out.println("Source:" + hit.getSourceAsString());//返回String类型的文档内容 System.out.println("Source As Map:" + hit.getSource());//返回Map格式的文档内容 System.out.println("Index:" + hit.getIndex());//返回文档所在的索引 System.out.println("Type:" + hit.getType());//返回文档所在的类型 System.out.println("ID:" + hit.getId());//返回文档的id System.out.println("Source:" + hit.getSource().get("price"));//从返回的map中通过key取到value System.out.println("Score:" + hit.getScore());//返回文档的评分 //getHighlightFields()会返回文档中所有高亮字段的内容,再通过get()方法获取某一个字段的高亮片段,最后调用getFragments()方法,返回Text类型的数组 Text[] texts = hit.getHighlightFields().get("title").getFragments(); if(texts != null) { //遍历高亮结果数组,取出高亮内容 for (Text text : texts) { System.out.println(text.string()); } } } } //测试入口 public static void main(String[] args) { new EsMatchQueryTest().esMatchQuery(); } }
Console 控制台输出如下:
共搜索到:2 Source:{"id":"4","title":"Python基础教程","language":"python","author":"Helant","price":54.50,"publish_time":"2014-03-01","description":"经典的Python入门教程,层次鲜明,结构严谨,内容翔实"} Source As Map:{author=Helant, price=54.5, publish_time=2014-03-01, description=经典的Python入门教程,层次鲜明,结构严谨,内容翔实, language=python, id=4, title=Python基础教程} Index:books Type:IT ID:4 Source:54.5 Score:0.9130229 <span stype="color:red">Python</span>基础教程 Source:{"id":"3","title":"Python科学计算","language":"python","author":"张若愚","price":81.40,"publish_time":"2016-05-01","description":"零基础学python,光盘中作者独家整合开发winPython运行环境,涵盖了Python各个扩展库"} Source As Map:{author=张若愚, price=81.4, publish_time=2016-05-01, description=零基础学python,光盘中作者独家整合开发winPython运行环境,涵盖了Python各个扩展库, language=python, id=3, title=Python科学计算} Index:books Type:IT ID:3 Source:81.4 Score:0.6931472 <span stype="color:red">Python</span>科学计算
代码截图如下:
使用对应的 RESTful 请求:
GET books/_search { "query": { "match": { "title": "python" } }, "highlight": { "fields": { "title": { "pre_tags": ["<span stype="color:red">"], "post_tags": ["</strong>"] } } } }
返回的响应结果:
{ "took": 15, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 0.9130229, "hits": [ { "_index": "books", "_type": "IT", "_id": "4", "_score": 0.9130229, "_source": { "id": "4", "title": "Python基础教程", "language": "python", "author": "Helant", "price": 54.5, "publish_time": "2014-03-01", "description": "经典的Python入门教程,层次鲜明,结构严谨,内容翔实" }, "highlight": { "title": [ """<span stype="color:red">Python</strong>基础教程""" ] } }, { "_index": "books", "_type": "IT", "_id": "3", "_score": 0.6931472, "_source": { "id": "3", "title": "Python科学计算", "language": "python", "author": "张若愚", "price": 81.4, "publish_time": "2016-05-01", "description": "零基础学python,光盘中作者独家整合开发winPython运行环境,涵盖了Python各个扩展库" }, "highlight": { "title": [ """<span stype="color:red">Python</strong>科学计算""" ] } } ] } }
可以看到使用 RESTful API 和 Java API 返回的结果一致。
三、Java API 详解
上面通过一个例子,演示了如何使用 Java API 客户端连接 Elastisearch 集群和检索数据,下面展示具体的 Java API。
3.1 传输客户端
传输客户端官方文档:TransportClient
// on startup TransportClient client = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new TransportAddress(InetAddress.getByName("host1"), 9300)) .addTransportAddress(new TransportAddress(InetAddress.getByName("host2"), 9300)); // on shutdown client.close();
client 对象知道一个或多个传输地址,通过轮询调度的方式和服务器交互。
3.2 索引管理
索引管理官方文档:Indices Administration
其核心是通过 IndicesAdminClient 对象发送各种索引操作。
3.3 文档管理
文档管理官方文档:Document APIs
主要包括单文档操作 Single document APIs 和多文档操作 Multi-document APIs。
Single document APIs
Multi-document APIs
创建文档 Index API
package tup.es.client; import java.io.IOException; import java.net.InetAddress; import java.net.UnknownHostException; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.InetSocketTransportAddress; import org.elasticsearch.common.xcontent.XContentBuilder; import org.elasticsearch.common.xcontent.XContentFactory; import org.elasticsearch.transport.client.PreBuiltTransportClient; public class TestClient { public static String CLUSTER_NAME = "Banon"; public static String HOST_IP = "192.168.56.110"; public static int TCP_PORT = 9300; public static void main(String[] args) throws IOException { Settings settings = Settings.builder().put("cluster.name", CLUSTER_NAME).build(); TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(HOST_IP), TCP_PORT)); // GetResponse getResponse = client.prepareGet("books", "IT", "1").get(); // System.out.println(getResponse.getSourceAsString()); XContentBuilder builder = XContentFactory.jsonBuilder().startObject() .field("id", "11580657") .field("title", "使用Linux Shell编程") .field("language", "Shell") .field("author", "石庆东") .field("price", 48.30) .field("publish_time", "2014-11-01") .field("description", "《信息科学与技术丛书:实用LinuxShell编程》系统地介绍了在Linux系统中广泛使用的Bash脚本语言。全书内容的安排由浅入深,体系合理。先讲解脚本的概念和学习环境的搭建,接下来介绍Linux的常用命令,然后根据概念之间的依赖关系,讲解Bash环境设置、变量与数组、条件流程控制、循环、函数、正则表达式、文本处理、进程与作业、高级话题等。本书是一本不可多得的shell编程原创读物。") .endObject(); System.out.println(builder.string()); IndexResponse response = client.prepareIndex("books", "IT", "6").setSource(builder).get(); System.out.println(response.status()); } }
控制台返回结果如下:
{"id":"11580657","title":"使用Linux Shell编程","language":"Shell","author":"石庆东","price":48.3,"publish_time":"2014-11-01","description":"《信息科学与技术丛书:实用LinuxShell编程》系统地介绍了在Linux系统中广泛使用的Bash脚本语言。全书内容的安排由浅入深,体系合理。先讲解脚本的概念和学习环境的搭建,接下来介绍Linux的常用命令,然后根据概念之间的依赖关系,讲解Bash环境设置、变量与数组、条件流程控制、循环、函数、正则表达式、文本处理、进程与作业、高级话题等。本书是一本不可多得的shell编程原创读物。"}
CREATED
jsonbuilder 是高度优化的 JSON 生成器。此处使用 Elasticsearch 内置的帮助类 XContentFactory 的 jsonBuilder() 方法,构造出 XContentBuilder 对象,XContentBuilder 对象可以直接写入 Elasticsearch 中。如果需要查看生成的 JSON 内容,可以调用 string() 方法。
3.4 查询检索
查询检索官方文档:Query DSL
主要包括如下类别,这些与 RESTful 中的请求相互对应。
以下分别为全部匹配查询,全文查询,词项查询,符合查询,嵌套(连接)查询,地理位置查询,特殊查询,跨度查询。
- Match All Query
- Full text queries
- Term level queries
- Compound queries
- Joining queries
- Geo queries
- Specialized queries
- Span queries
上面的 Full text queries 全文查询中包括 multi_match query,表示检索多个字段,如下:
QueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery( "java思想", "title", "description");
"java思想" 表示 text,"title" 和 "description" 表示 fields。
3.5 聚合分析
聚合分析官方文档:Aggregations
主要包括如下类别,主要仍然为指标聚合和桶聚合。