注:本文是人工智能研究网的学习笔记
规范化(Normalization)
Normalization: scaling individual to have unit norm
规范化是指,将单个的样本特征向量变换成具有单位长度(unit norm)的特征向量的过程。当你要使用二次形式(quadratic from)如点积或核变换运算来度量任意一堆样本的相似性的时候,数据的规范化会非常的有用
假定是基于向量空间模型,经常被用于文本分类和内容的聚类。
函数normalize提供了快速简单的方法使用L1或L2范数(距离)执行规范化操作:
X = [[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]]
X_normalized = preprocessing.normalize(X, norm='l2')
X_normalized

注意:该函数按行操作,把每一行变成单位长度。使用每一个元素去除以欧式距离。
preprocessing模块也提供了一个类Normalizer实现了规范化操作,该类是一个变换器Transformer,具有Transformer API(尽管fit方法在这种时候是没有用的: 该类是一个静态类因为归一化操作是将每一个样本单独进行变换,不存在在所有样本上的统计学习过程。)
规范化操作类Normalizer作为数据预处理步骤,应该用在Pineline管道流的早期阶段。
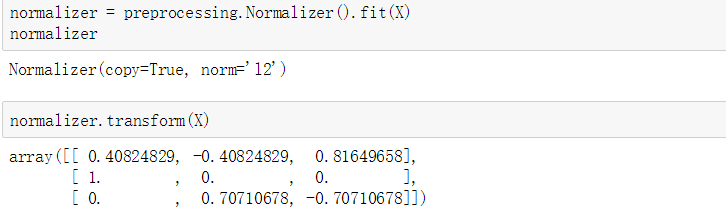
以上的transform过程不依赖于上面的X,也就是说fit是多余的,只是为了整个sklearn的统一。
Sparse input
normalize函数和Normalizer类都接受dense array-like and sparse matrics from scipy.sparse作为输入。
对于稀疏输入,在进入高效的Cython routines处理之前,都会将其转化成CSR(Compressed Sparse Rows)格式(scipy.sparse.csr_matrix),为了避免不必要的数据拷贝,推荐使用CSR格式的稀疏矩阵。
二值化(Binarize)
Binarization: thresholding numerical features to get boolean values
Feature binarization: 将数值型特征取值阈值化转换为布尔型特征取值,这一过程主要是为概率型的学习器(probabilistic estimators)提供数据预处理机制。
概率型学习器(probabilistic estimators)假定输入数据是服从于多变量伯努利分布(multi-variate Bernoulli distribution)的, 概率性学习器的典型的例子是sklearn.neural_network.BrenoulliRBM
在文本处理中,也普遍使用二值特征简化概率推断过程,即使归一化的词频特征或TF-IDF特征的表现比而二值特征稍微好一点。
就像Normalizer,Binarizer也应该用在sklearn.pipeline.Pipeline的早期阶段。fit方法也是什么也不干,有或者没有是一样的。
X = [[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]]
binarizer = preprocessing.Binarizer().fit(X)
print(binarizer)
print('-----')
print(binarizer.transform(X))

binarizer = preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)

就像StandardScaler和Normalizer类一样,preprocessing模块也为我们提供了一个方便的额binarize进行数值特征的二值化。
Sparse input
normalize函数和Normalizer类都接受dense array-like and sparse matrics from scipy.sparse作为输入。
对于稀疏输入,在进入高效的Cython routines处理之前,都会将其转化成CSR(Compressed Sparse Rows)格式(scipy.sparse.csr_matrix),为了避免不必要的数据拷贝,推荐使用CSR格式的稀疏矩阵。