注:本文是人工智能研究网的学习笔记
模型验证方法一览
| 名称 | 模块 |
|---|---|
| 通过交叉验证计算得分 | model_selection.cross_val_score(estimator, X) |
| 对每个输入点产生交叉验证估计 | model_selection.cross_val_predict(estimator, X) |
| 计算并绘制模型的学习率曲线 | model_selection.learning_curve(estimator, X, y) |
| 计算并绘制模型的验证曲线 | model_selection.validation_curve(estimator, ...) |
| 通过排序评估交叉验证defender重要性 | model_selection.permutation_test_score(...) |
通过交叉验证计算得分
cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
参数:
- estimator: 实现了'fit'函数的学习器
- X: array-like,需要学习的数据,可以是列表或者2d数组
- y: 可选的,默认是None,监督学习中样本特征向量的真实目标值
- scroing: srting,callable or None,可选的,默认是None,
一个字符串或者一个scorer可调用对象或者函数,必须实现scorer(estimator, X, y) - cv: int,交叉验证生成器或者一个迭代器,可选的,默认是None,决定交叉验证划分策略
cv的可选项有以下的几种
- None: 使用默认的3-fold交叉验证
- Interger:指定在(Stratified)kfold中使用的‘折’的数量
- 可以用作交叉验证生成器的一个对象
- 一个能够产生train/test划分的迭代器对象
对于integer/None类型的输入,如果estimator是一个分类器并且y是对应的类标签,则默认使用StratifiedKFold,其他的情况默认使用kfold
返回值:
- scores:浮点数组, shape=(len(list(cv)),)每一次交叉验证得分弄成一个数组,默认是三次,三个得分。
from sklearn.model_selection import cross_val_score
import numpy as np
from sklearn import datasets, svm
digits = datasets.load_digits()
X = digits.data
y = digits.target
svc = svm.SVC(kernel='linear') # C 结构因子最小化因子
C_s = np.logspace(-10, 0, 10)
print('参数列表长度:', len(C_s))
scores = list()
scores_std = list()
for C in C_s:
svc.C = C
this_scores = cross_val_score(svc, X, y, n_jobs=4) # 指定并行数量
scores.append(np.mean(this_scores))
scores_std.append(np.std(this_scores))
# 绘制交叉验证曲线
import matplotlib.pyplot as plt
plt.figure(1, figsize=(4,3))
plt.clf()
plt.semilogx(C_s, scores)
plt.semilogx(C_s, np.array(scores) + np.array(scores_std) , 'b--')
plt.semilogx(C_s, np.array(scores) - np.array(scores_std) , 'b--')
locs, labels= plt.yticks()
plt.yticks(locs, list(map(lambda x: "%g" %x, locs)))
plt.ylabel('CV score')
plt.xlabel('Parameter C')
plt.ylim(0, 1.1)
plt.show()

对每个输入点产生交叉验证估计
cross_val_predict(estimator, X, y=None, groups=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', method='predict')
参数:
- method 字符串,可选,默认是'predict'
返回值:
- predictions: ndarray 预测结果
计算并绘制模型的学习率曲线
learning_curve(estimator, X, y, groups=None, train_sizes=array([ 0.1 , 0.325, 0.55 , 0.775, 1. ]), cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=1, pre_dispatch='all', verbose=0)
参数:
- train_sizes: array-like, shape(n_ticks,), dtype=float or int 用于指定训练样本子集的相对数量或者绝对数量,如果是浮点数,将会被视作整体训练集最大数量的百分比,所以必须在(0,1)之间,如果是int整型,就是绝对的数量,不能超过整体训练集的样本量。对于分类问题,训练子集的大小必须能够保证每个类至少有一个样本。
返回值:
- train_sizes_abs
- train_scores
- test_scores
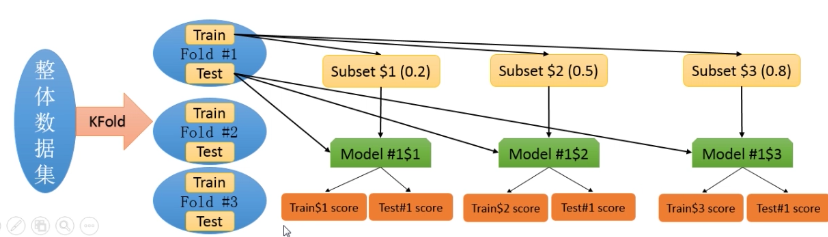
学习率曲线:
计算指定的学习器模型在不同大小的训练集上经过交叉验证的训练得分和测试得分。
首先,用一个交叉验证生成器划分整体数据集K次,每一次都有一个训练集和测试集,然后从第k次的训练集中拿出若干个数量不断增长的子集,在这些子训练集上训练模型。然后在计算模型在对应的子训练集和测试集上的得分。最后,对于在每种子训练集大小下,将K次训练集和测试集得分分别进行平均。
计算并绘制模型的验证曲线
validation_curve(estimator, X, y, param_name, param_range, groups=None, cv=None, scoring=None, n_jobs=1, pre_dispatch='all', verbose=0)
返回值:
- train_scores array.shape(n_ticks, n_cv_folds)
- test_scores
验证曲线:
当某个参数不断变化的时候,在每一个取值上计算出的模型在训练集和测试集上得分,在一个不断变化的参数上计算学习器模型的得分。这类似于只有一个参数的网格搜索。但是这个函数也会计算训练集上的得分。