The Boyer-Moore algorithm is considered as the most efficient string-matching algorithm in usual applications. A simplified version of it or the entire algorithm is often implemented in text editors for the «search» and «substitute» commands.
The algorithm scans the characters of the pattern from right to left beginning with the rightmost one. In case of a mismatch (or a complete match of the whole pattern) it uses two precomputed functions to shift the window to the right. These two shift functions are called the good-suffix shift (also called matching shift and the bad-character shift (also called the occurrence shift).
Assume that a mismatch occurs between the character x[i]=a of the pattern and the character y[i+j]=b of the text during an attempt at position j.
Then, x[i+1 .. m-1]=y[i+j+1 .. j+m-1]=u and x[i]  y[i+j]. The good-suffix shift consists in aligning the segment y[i+j+1 .. j+m-1]=x[i+1 .. m-1] with its rightmost occurrence in x that is preceded by a character different from x[i] (see figure 13.1).
y[i+j]. The good-suffix shift consists in aligning the segment y[i+j+1 .. j+m-1]=x[i+1 .. m-1] with its rightmost occurrence in x that is preceded by a character different from x[i] (see figure 13.1).

Figure 13.1. The good-suffix shift, u re-occurs preceded by a character c different from a.
If there exists no such segment, the shift consists in aligning the longest suffix v of y[i+j+1 .. j+m-1] with a matching prefix of x (see figure 13.2).
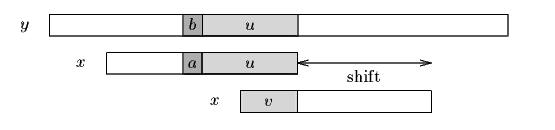
Figure 13.2. The good-suffix shift, only a suffix of u re-occurs in x.
The bad-character shift consists in aligning the text character y[i+j] with its rightmost occurrence in x[0 .. m-2]. (see figure 13.3)
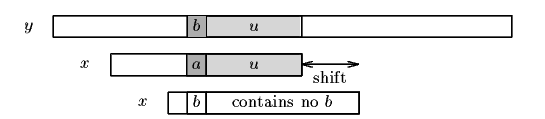
Figure 13.3. The bad-character shift, a occurs in x.
If y[i+j] does not occur in the pattern x, no occurrence of x in y can include y[i+j], and the left end of the window is aligned with the character immediately after y[i+j], namely y[i+j+1] (see figure 13.4).

Figure 13.4. The bad-character shift, b does not occur in x.
Note that the bad-character shift can be negative, thus for shifting the window, the Boyer-Moore algorithm applies the maximum between the the good-suffix shift and bad-character shift. More formally the two shift functions are defined as follows.
The good-suffix shift function is stored in a table bmGs of size m+1.
- Let us define two conditions:
-
 Cs(i, s): for each k such that i < k < m, s
Cs(i, s): for each k such that i < k < m, s  k or x[k-s]=x[k] and
k or x[k-s]=x[k] and - Co(i, s): if s <i then x[i-s] x[i]
Then, for 0  i < m: bmGs[i+1]=min{s>0 : Cs(i, s) and Co(i, s) hold}
i < m: bmGs[i+1]=min{s>0 : Cs(i, s) and Co(i, s) hold}
and we define bmGs[0] as the length of the period of x. The computation of the table bmGs use a table suff defined as follows: for 1 i < m, suff[i]=max{k : x[i-k+1 .. i]=x[m-k .. m-1]}
The bad-character shift function is stored in a table bmBc of size  . For c in
. For c in  : bmBc[c] = min{i : 1 i <m-1 and x[m-1-i]=c} if c occurs in x, m otherwise.
: bmBc[c] = min{i : 1 i <m-1 and x[m-1-i]=c} if c occurs in x, m otherwise.
Tables bmBc and bmGs can be precomputed in time O(m+) before the searching phase and require an extra-space in O(m+). The searching phase time complexity is quadratic but at most 3n text character comparisons are performed when searching for a non periodic pattern. On large alphabets (relatively to the length of the pattern) the algorithm is extremely fast. When searching for am-1b in bn the algorithm makes only O(n / m) comparisons, which is the absolute minimum for any string-matching algorithm in the model where the pattern only is preprocessed.
Preprocessing phase
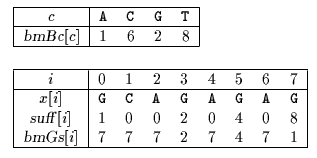
bmBc and bmGs tables used by Boyer-Moore algorithm
译文:
Boyer-Moore(BM)算法,又叫做快速字符串搜索算法,它是一种非常有效的字符串匹配算法。主要应用于一些程序的字符串处理,比如:搜索,替代等。这种算法的时间复杂度低于线性,所以是现在用的最多的一种方法。
BM算法从匹配串(模式串:pattern)的最右端的第一个字符开始从右至左扫描,匹配字符串(text),一旦发生不匹配就用两种规则向右移动模式串,直到匹配。这两种规则分别叫做:好后缀规则(good-suffix shift)、坏字符规则(bad-character shift)。
好后缀规则(good-suffix shift)
假设在模式串的字符x[i]=a,字符串的字符y[i+j]=b处不匹配,即x[i+1 .. m-1]=y[i+j+1 .. j+m-1]=u, and x[i] != y[i+j]。有两种情况发生:
1、如果在x后面的其他位置还包括好后缀u,且与u相邻左端的字符x[i-n]=c不等于x[i]=a,这时把在x后面的其他位置出现的u与y中的u对齐,并比较x[i-n]与y[i+j]。依次类推,示意图如下:
图2.1好后缀规则, u 出现的位置前的字符c!=a
2、如果没有出现与u相同的字符串则找到与u 的后缀相同的x的最长前缀u,向右移动x,使v与y中 u的后缀相对应。示意图如下:
图2.2好后缀规则, 只有u的一部分前缀出现在x中
坏字符规则(bad-character shift)
1、从右到左的扫描过程中,发现x[i]与y[j]不同,如果x中存在一个字符x[k]与y[i]相同,且k<i那么就将直接将x向右移使x[k]与y[i]对齐,然后再从右到左进行匹配。
图2.3坏字符规则,a与b不匹配,b出现在x中
2、如果x中不存在任何与y[i]相同的字符,则直接将x的第一个字符与y[i]的下一个字符对齐,再从右到左进行比较。
图2.4坏字符规则,a与b不匹配,b没有出现在x中
移动规则:
当文本字符串与模式字符不匹配时,根据函数bad-character shift和good-suffix shift计算出的偏移值,取两者中的大者。
1、存放bad-character shift的数组为BadChar[],则BadChar[c]= min{i| 1 ≤i≤m-1 and x[m-1-i]=c},如果c未在模式字符中出现则BadChar[c]=m(m为x的长度)。
2、存放good-suffix shift的数组为GoodSuffix[],则suff[i]=max{k | y[i-k+1 .. i]=x[m-k .. m-1], 1≤ i < m }。即 suff 是 P[0..i]和 T 的最长一般后缀。计算suff数组使得计算GoodSuffix函数变得简洁GoodSuffix[m - 1 - suff[i]] = m - 1–i。
最后取BadChar[c]和GoodSuffix[c]的最大值。