sparkcore是做离线批处理
sparksql 是做sql高级查询
sparkshell 是做交互式查询
sparkstreaming是做流式处理
区别:
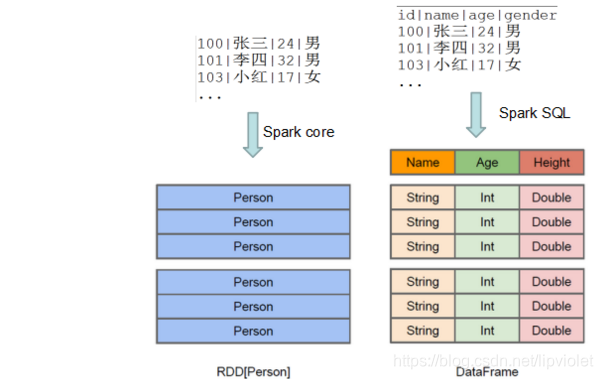
Spark Core :
Spark的基础,底层的最小数据单位是:RDD ; 主要是处理一些离线(可以通过结合Spark Streaming来处理实时的数据流)、非格式化数据。它与Hadoop的MapReduce的区别就是,spark core基于内存计算,在速度方面有优势,尤其是机器学习的迭代过程。
Spark SQL:
Spark SQL 底层的数据处理单位是:DataFrame(新版本为DataSet<Row>) ; 主要是通过执行标准 SQL 来处理一些离线(可以通过结合Spark Streaming来处理实时的数据流)、格式化数据。就是Spark生态系统中一个开源的数据仓库组件,可以认为是Hive在Spark的实现,用来存储历史数据,做OLAP、日志分析、数据挖掘、机器学习等等
Spark Streaming:
Spark Streaming底层的数据处理单位是:DStream ; 主要是处理流式数据(数据一直不停的在向Spark程序发送),这里可以结合 Spark Core 和 Spark SQL 来处理数据,如果来源数据是非结构化的数据,那么我们这里就可以结合 Spark Core 来处理,如果数据为结构化的数据,那么我们这里就可以结合Spark SQL 来进行处理。
联系:
Spark SQL构建在Spark Core之上,专门用来处理结构化数据(不仅仅是SQL)。即Spark SQL是Spark Core封装而来的!
Spark SQL在Spark Core的基础上针对结构化数据处理进行很多优化和改进,
简单来讲:
Spark SQL 支持很多种结构化数据源,可以让你跳过复杂的读取过程,轻松从各种数据源中读取数据。
当你使用SQL查询这些数据源中的数据并且只用到了一部分字段时,SparkSQL可以智能地只扫描这些用到的字段,而不是像SparkContext.hadoopFile中那样简单粗暴地扫描全部数据。
可见,Spark Core与Spark SQL的数据结构是不一样的!