本节课程内容概览:
1.装饰器
2.列表生成式&迭代器&生成器
3.json&pickle数据序列化
1. 装饰器
1.1 定义:
本质上是个函数,功能是装饰其他函数—就是为其他函数添加附加功能
1.2 装饰器原则:
1) 不能修改被装饰函数的源代码;
2) 不能修改被装饰函数的调用方式;
1.3 实现装饰器知识储备:
1.3.1 函数即“变量”
定义一个函数相当于把函数体赋值给了函数名
变量可以指向函数
>>> def func():
...... print("这是一个函数")
>>> print(func)
>>> func()
<function func at 0x0000000000D2CD08>
这是一个函数
#func()是函数调用,而func是函数本身。
#要获得函数调用结果,我们可以把结果赋值给变量:
>>> a = func()
这是一个函数
#函数本身赋值给变量
>>> a = func
<function func at 0x0000000000D2CD08>
#结论:函数本身也可以赋值给变量,即:变量可以指向函数。
#猜想:是否可以通过变量直接调用函数?
>>> a=func
>>> a()
这是一个函数
#说明变量指向了func函数本身,直接调用a()和func()完全相同
1.3.2 高阶函数
高阶函数:能接收函数作为参数的函数。
满足下列条件之一就可成函数为高阶函数
-
某一函数当做参数传入另一个函数中(用处:在不修改被装饰函数源代码的情况下为其添加功能)
>>> def bar(): ......print('in the bar') >>> def foo(func): ......res=func() ......return res >>> foo(bar) in the bar -
函数的返回值包含n个函数,n>0(用处:不修改函数调用方式)
>>>def bar(): ......time.sleep(3) ......print("in the bar") >>> def test2(func): ......print(func) ......return func >>> print(test2(bar)) >>> bar = test2(bar) >>> bar() <function bar at 0x0000000000D6CD08> <function bar at 0x0000000000D6CD08> <function bar at 0x0000000000D6CD08> in the bar
高阶函数示例
- map()
map函数会根据提供的函数对指定序列做映射。
map函数的定义:
map(function, sequence[, sequence, ...]) -> list
通过定义可以看到,这个函数的第一个参数是一个函数,剩下的参数是一个或多个序列,返回值是一个集合。
function可以理解为是一个一对一或多对一函数,map的作用是以参数序列中的每一个元素调用function函数,返回包含每次function函数返回值的list。
>>> def f(x): ...... return x*x >>> r = map(f,[1,2,3,4,5,6,7,8,9]) >>> print(list(r)) [1, 4, 9, 16, 25, 36, 49, 64, 81]
- reduce()
reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算。效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
>>> from functools import reduce
>>> def add(x, y):
......return x + y
>>> print(reduce(add, [1, 3, 5, 7, 9]))
25
- filter()
filter函数会对指定序列执行过滤操作。
filter函数的定义:
filter(function or None, sequence) -> list, tuple, or string
function是一个谓词函数,接受一个参数,返回布尔值True或False。
filter函数会对序列参数sequence中的每个元素调用function函数,最后返回的结果包含调用结果为True的元素。
返回值的类型和参数sequence的类型相同。
>>> def is_odd(n):
...return n % 2 == 1
>>> print(list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15])))
[1, 5, 9, 15]
- sorted()
对列表内容进行正向排序,即可以保留原列表,又能得到已经排序好的列表;
>>> a = {6:2,8:0,1:4,-5:6,99:11,4:22}
>>> print(sorted(a.items())) #按key排序
[(-5, 6), (1, 4), (4, 22), (6, 2), (8, 0), (99, 11)]
>>> print(sorted(a.items(),key=lambda x:x[1])) #按value排序
[(8, 0), (6, 2), (1, 4), (-5, 6), (99, 11), (4, 22)]
1.3.3 嵌套函数
定义:在一个函数体内用def去声明一个新函数
>>> def foo(): #定义函数foo()
...m=3 #定义变量m=3;
...def bar(): #在foo内定义函数bar()
...n=4 #定义局部变量n=4
...print(m+n) #m相当于函数bar()的全局变量
...bar() #foo()函数内调用函数bar()
>>> foo() #调用foo()函数
7
1.3.4 装饰器
高阶函数+嵌套函数=>装饰器
不带参数的装饰器:
#装饰器
import time
def timer(func):
def deco():
start_time=time.time()
func() #执行形参func()
end_time=time.time()
print("func runing time is %s"%(end_time-start_time))
return deco #返回函数deco的内存地址
def test1():
print("in the test1")
time.sleep(1)
test1 = timer(test1) #重新赋值test1 此时test1=deco的内存地址
test1() #执行test1
###########打印输出###########
#in the test1
#func runing time is 1.0000572204589844
带固定参数的装饰器:
#装饰器
import time
def timer(func):
def deco(name):
start_time=time.time()
func(name) #执行形参func()
end_time=time.time()
print("func runing time is %s"%(end_time-start_time))
return deco #返回函数deco的内存地址
@timer #test1 = timer(test1) test1=deco
def test1(name):
print("in the test1 name %s"%name)
time.sleep(1)
test1("cc") #执行test1
###########打印输出###########
#in the test1 name cc
#func runing time is 1.0000572204589844
带返回值的装饰器:
#装饰器
import time
def timer(func):
def deco(*args,**kwargs):
start_time=time.time()
res = func(*args,**kwargs) #执行形参func()
end_time=time.time()
print("func runing time is %s"%(end_time-start_time))
return res
return deco #返回函数deco的内存地址
@timer #test1 = timer(test1) test1=deco
def test1(name):
print("in the test1 name %s"%name)
time.sleep(1)
return "return form test1"
print(test1("cc")) #执行test1
###########打印输出###########
#in the test1 name cc
#func runing time is 1.0000572204589844
#return form test1
通过以上我们会发现一个问题,选用的装饰器只能选择统一带形参或者统一不带形参;那么问题来了,我想要用一个装饰器,带形参的能调用,不带形参的也能调用,可不可以呢?
带不固定参数的装饰器:
# 装饰器
import time
def timer(func):
def deco(*args, **kwargs):
start_time = time.time()
func(*args, **kwargs) # 执行形参func()
end_time = time.time()
print("func runing time is %s" % (end_time - start_time))
return deco # 返回函数deco的内存地址
@timer # test1 = timer(test1) test1=deco
def test1(name):
print("in the test1 name %s" % name)
time.sleep(1)
@timer
def test2():
print("in the test2 no name")
time.sleep(1)
test1("cc") # 执行test1
test2() # 执行test2
###########打印输出###########
in the test1 name cc
func runing time is 1.0010571479797363
in the test2 no name
func runing time is 1.0000572204589844
终极版装饰器:
import time
user,passwd = 'cc','123123'
def auth(auth_type):
print('auth func:',auth_type)
def outer_wrapper(func):
def wrapper(*args,**kwargs):
print("wrapper func args:",*args,**kwargs)
if auth_type == 'local':
username = input("Username:").strip()
password = input("Password:").strip()
if user == username and passwd == password:
print("User has passed authentication!")
res = func(*args,**kwargs)
print("---after authentication")
return res
else:
exit("Invalid username or password!")
elif auth_type == "ldap":
print("搞毛线ldap,不会。。。")
return wrapper
return outer_wrapper
def index():
print("welcome to index page")
@auth(auth_type='local')#home = wrapper()
def home():
print("welcome to home page")
return "from home"
@auth(auth_type="ldap")
def bbs():
print("welcome to bbs page")
index()
print(home()) #wrapper()
bbs()
2. 迭代器&生成器
2.1 列表生成式
列表生成式,是Python内置的一种极其强大的生成list的表达式。
如果要生成一个list [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9] 可以用 range(1 , 10):
#print(list(range(1,10))) [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果要生成[1x1, 2x2, 3x3, ..., 10x10]怎么做?
l = []
for i in range(1,10):
l.append(i*i)
print(l)
####打印输出####
#[1, 4, 9, 16, 25, 36, 49, 64, 81]
而列表生成式则可以用一行语句代替循环生成上面的list:
>>> print([x*x for x in range(1,10)]) [1, 4, 9, 16, 25, 36, 49, 64, 81]
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
>>> print([x*x for x in range(1,10) if x %2 ==0]) [4, 16, 36, 64]
2.2 生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> L = [x * x for x in range(10)] >>> print(L) [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> g = (x * x for x in range(10)) >>> print(g) <generator object <genexpr> at 0x1022ef630>
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素;而generator里的每一个元素我们可以通过next()函数获取:
>>> g = (x * x for x in range(10))
>>> print(g)
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
>>> print(next(g))
0
1
4
9
16
25
36
49
64
81
Traceback (most recent call last):
File "XXX", line 32, in <module>
print(next(g))
StopIteration
上面我们可以看到,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,我们也可以通过for循环去调取元素值:
>>> g = (x * x for x in range(10)) >>> for i in g: >>> print(i) 0 1 4 9 16 25 36 49 64 81
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
#斐波拉契数列
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n += 1
return 'done'
fib(5)
###########打印输出###########
# 1
# 1
# 2
# 3
# 5
仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
#斐波拉契数列
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield(b)
a, b = b, a + b
n += 1
return 'done'
f = fib(5)
print(f)
for i in f:
print(i)
###########打印输出###########
#<generator object fib at 0x000000000110A468>
#1
#1
#2
#3
#5
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。
generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
上面我们会发现:用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
g = fib(6)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e:
print('Generator return value:', e.value)
break
####打印输出####
# g: 1
# g: 1
# g: 2
# g: 3
# g: 5
# g: 8
# Generator return value: done
生成器的特点:
1)生成器只有在调用时才会生成相应的数据;
2)只记录当前位置;
3)只有一个__next__()方法;
还可通过yield实现在单线程的情况下实现并发运算的效果:
import time
def consumer(name):
print("%s 准备吃包子啦!" %name)
while True:
baozi = yield
print("包子[%s]来了,被[%s]吃了!" %(baozi,name))
def producer(name):
c = consumer('A')
c2 = consumer('B')
c.__next__()
c2.__next__()
print("老子开始准备做包子啦!")
for i in range(10):
time.sleep(1)
print("做了2个包子!")
c.send(i)
c2.send(i)
producer("cc")
2.3 迭代器
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable
>>> print(isinstance([],Iterable))
True
>>> print(isinstance({},Iterable))
True
>>> print(isinstance((),Iterable))
True
>>> print(isinstance(set(),Iterable))
True
>>> print(isinstance('abc',Iterable))
True
>>> print(isinstance(100,Iterable))
False
>>> >>> print(isinstance((x for x in range(1,10)),Iterable))
True
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections import Iterator
>>> print(isinstance([],Iterator))
False
>>> print(isinstance({},Iterator))
False
>>> print(isinstance((),Iterator))
False
>>> print(isinstance(set(),Iterator))
False
>>> print(isinstance('abc',Iterator))
False
>>> print(isinstance(100,Iterator))
False
>>> >>> print(isinstance((x for x in range(1,10)),Iterator))
True
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> from collections import Iterator
>>> print(isinstance(iter([]),Iterator))
True
>>> print(isinstance(iter('abc'),Iterator))
True
python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
总结:
1.凡是可作用于for循环的对象都是Iterable类型;
2.凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
3.集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
3.json&pickle数据序列化
json和pickle模块,两个都是用于序列化的模块
• json模块,用于字符串与python数据类型之间的转换
• pickle模块,用于python特有类型与python数据类型之间的转换
3.1 json
3.1.1 什么是json?
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。这些特性使JSON成为理想的数据交换语言。
JSON建构于两种结构:
1)“名称/值”对的集合(A collection of name/value pairs)。不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组 (associative array)。
2)值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)。
这些都是常见的数据结构。事实上大部分现代计算机语言都以某种形式支持它们。这使得一种数据格式在同样基于这些结构的编程语言之间交换成为可能。
json官方说明参见:http://json.org/
Python操作json的标准api库参考:http://docs.python.org/library/json.html
在python3中import json模块,然后使用dir(json)可以看到json模块提供的函数,下面选几个常用的json处理函数看看用法:
>>> import json >>> print(dir(json)) ['JSONDecodeError', 'JSONDecoder', 'JSONEncoder', '__all__', '__author__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', '_default_decoder', '_default_encoder', 'decoder', 'dump', 'dumps', 'encoder', 'load', 'loads', 'scanner']
3.1.2 dump & dumps
dumps:
先定义一个列表,然后转换看看输出结果:
>>> import json
>>> dir = [{“c”: [1, 2, 3, [4, 5, 6]], “a”: “aaa”, “b”: “bbb”}, 33, “tantengvip”, true]
>>> print(json.dumps(dir))
输出结果:
[{“c”: [1, 2, 3, [4, 5, 6]], “a”: “aaa”, “b”: “bbb”}, 33, “tantengvip”, true]
其实python的列表数据结构跟json数据结果很类似,转换之后大体不变,只是True变成了true,元祖类型的(4,5,6)变成了[4,5,6].
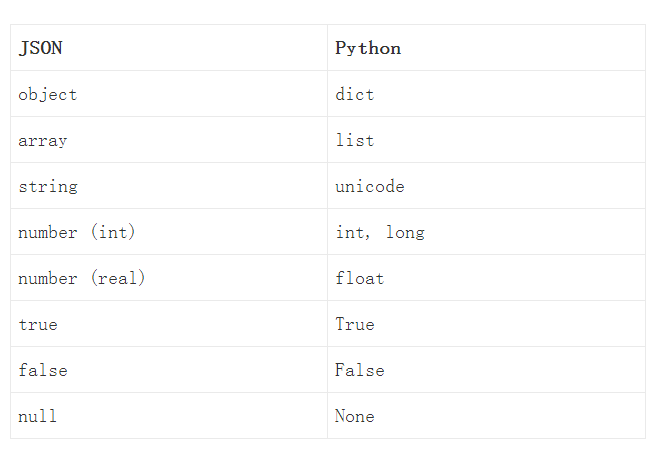
上图展现了python和json类型的转换区别。
dump:
json.dump和json.dumps很不同,json.dump主要用来json文件读写,和json.load函数配合使用。json.dump(x,f),x是对象,f是一个文件对象,这个方法可以将json字符串写入到文本文件中。
>>> import json
>>> dir = {'cc':{'money':1,'sex':'boy'}}
>>> f=open('./eg.txt','w')
>>> json.dump(dir,f)
#生成文件eg.txt,文件内容为 {'cc':{'money':1,'sex':'boy'}}
3.1.3 load & loads
要把JSON反序列化为Python对象,用loads()或者对应的load()方法,前者把JSON的字符串反序列化,后者从文件中读取字符串并反序列化:
load:
针对文件句柄
>>> import json
>>> list = open('./eg.txt')
>>> list1 = json.load(list)
>>> print(list1)
{'cc': {'money': 1, 'sex': 'boy'}}
loads:
针对内存对象,即将Python内置数据序列化为字串
>>> hehe2 = json.loads('["aaa",{"name":"pony"}]')
>>> print(hehe2)
['aaa', {'name': 'pony'}]
3.2 pickle
pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
基本接口:
pickle.dump(obj, file)
注解:将对象obj保存到文件file中去。
file:对象保存到的类文件对象。file必须有write()接口, file可以是一个以'w'方式打开的文件或者一个StringIO对象或者其他任何实现write()接口的对象。如果protocol>=1,文件对象需要是二进制模式打开的。
pickle.load(file)
注解:从file中读取一个字符串,并将它重构为原来的python对象。
file:类文件对象,有read()和readline()接口。
>>> import pickle
>>> d = {'name':'ethan','age':28}
>>> ret = pickle.dumps(d) # ==> pickle将字典、元组、列表转换成二进制
>>> print(ret,type(ret))
>>> l = [11,22,3,45,54]
>>> res = pickle.dumps(l)
>>> print(res)
>>> pickle.dump(d,open('ethan.txt','ab')) # ==> 将字典、元组、列表转换成二进制写入文档
# 注意 dump load 不要一起运行,会报错,一步一步来
>>> f = open('ethan.txt','rb')
>>> r = pickle.loads(f.read()) # ==> 将二进制转换成字典、列表、元组
>>> print(r)