KNN算法介绍
KNN算法(K-NearestNeighor Algorithm) 是一种最简单的分类算法。
算法核心:
假设在一个二维坐标平面中已经有了(n)个点,每个点的颜色已知,现在给定查询点(p)的坐标((x,y)),判断(p)的颜色。
对于已知的(n)个点,计算每个点和点(p)的欧几里得距离:
[dis_i=sqrt{(x_i-x)^2+(y_i-y)^2}
]
按照(dis)从小到大排序,选择距离最近的前(k)个点,在这前k个点中统计颜色出现次数最多的点,则点(p)的颜色就被划分为该点的颜色。
数字识别的实现
已有的数据集(TraingData):
若干份txt文件,每份txt文件都是32*32的01矩阵,代表对应的数字,下图中的矩阵就是数字0:

若干份txt文件,是测试数据集,用于校验算法的正确率。
算法流程:
- 将32x32的矩阵转换成1x1024的向量
- 计算输入的数据向量和所有的训练集向量的欧几里得距离。
- 按照欧几里得距离排序,选前K近的,选择出现次数最多的作为数字。
- 计算正确率
代码:
import numpy as np
import os
import operator
#返回inputdata所属的种类
def KNN(inputdata,TrainingSet,lable,k):
m=TrainingSet.shape[0] #训练集大小
difmaze=np.tile(inputdata,(m,1))-TrainingSet #距离矩阵,第i行代表inputdata与第i个训练样例的距离
sqdifmaze=difmaze ** 2## 距离的平方
sqsum=sqdifmaze.sum(axis=1) ## 计算每一行的和
distance=sqsum ** 0.5 ## 欧几里得距离
sorteddistanceID=distance.argsort() ## 欧几里得距离从小到大排序后的下标
classcount={} ## 计数器
for i in range(k): ## 前k近的lable
nowlable=lable[sorteddistanceID[i]] ##对每个label计数
classcount[nowlable]=classcount.get(nowlable,0)+1
sortedClasscount=sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClasscount[0][0] ## 返回出现次数最多的
# 对每个32*32的数字向量化为1*1024的向量
def Vectorfy(filename):
vec=[]
fr=open(filename)
for i in range(32):
lineStr=fr.readline()
for j in range(32):
vec.append(int(lineStr[j]))
return vec;
def Getlable(filename):
return filename[0]
# 获取训练集
def TrainingSet():
Label=[]
traininglst=os.listdir('trainingDigits')
m=len(traininglst)
trainingmat=np.zeros((m,1024))# 训练矩阵
for i in range(m):
filenamestr=traininglst[i]
Label.append(Getlable(filenamestr))
trainingmat[i,:]=Vectorfy('trainingDigits/%s' %filenamestr)
return Label,trainingmat
def Test():#测试测试集
testlst=os.listdir('testDigits')
n=len(testlst)
Lable=[]
testmat=np.zeros((n,1024))
for i in range(0,n):
filenamestr=testlst[i]
Lable.append(Getlable(filenamestr))
testmat[i,:]=Vectorfy('testDigits/%s' %filenamestr)
return Lable,testmat
testlable,testmat=Test()
trainlabel,trainingmat=TrainingSet()
n=testmat.shape[0]
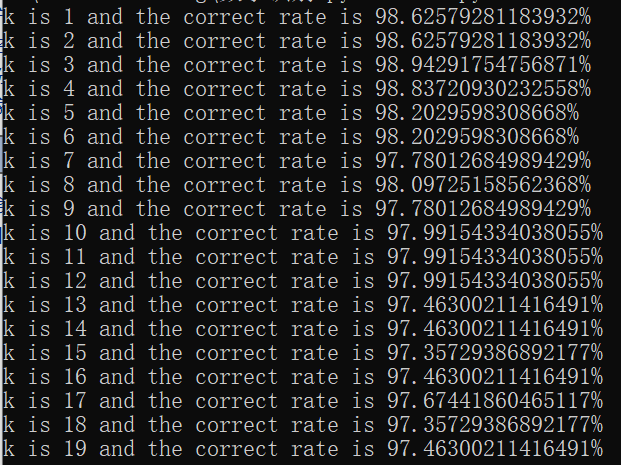
for k in range(1,20):
err=0.0
for i in range(n):
actlable=KNN(testmat[i],trainingmat,trainlabel,k)
#print("The correct answer is %d and the actual answer is %d" %(int(testlable[i]),int(actlable)))
if(testlable[i]!=actlable):
err+=1
print('k is {} and the correct rate is {}%'.format(k,(n-err)*100/n))
不同K下的正确率