本案例参考自阿里云的视频直播解决方案之视频核心指标监控和视频直播解决方案之直播数字化运营。
基于Kafka + Flink + ELK + Redis实现视频直播数据的实时处理和可视化。
选型仅仅出于练习考虑,Logstash一般会换成flume或者直接用kafka。
模拟的总体流程:通过http请求发送json到Logstash,后者将数据转发到Kafka,然后Flink拉取数据进行处理,结果写入Elasticsearch,最后利用Kibana搭建实时dashboard。
实现功能:
- 视频核心指标监控:房间故障指标、分地域数据延迟情况、网站整体卡顿率、人均卡顿次数
- 直播数字化运营:全站观看直播总人数以及走势、各房间观看人数以及走势、热门直播房间及主播Top10,分类目主播Top10
- 上述功能的dashboard展示
数据产生
数据结构
阿里云上有一些样本数据,可以用于测试。另外由于数据量较少,并不方便后面的kibana可视化,所以我编写了一个python程序模拟产生10W+条数据用于后续的可视化实现。下面只选取了与将要实现的功能相关的指标。
字段 含义
0.roomid 房间号
1.userid 用户id
2.adrop 音频丢帧数量
3.alat 音频帧端到端延迟
4.vdrop 视频丢帧数量
5.vlat 视频帧端到端延迟
6.ublock 上行卡顿次数
7.dblock 下行卡顿次数
8.timestamp 打点时间戳
9.region 地域
我用python对这些csv数据进行了预处理,把原数据转换为json格式,用来模拟一些生产情况.另外,在日期和时间之间的空格换成字母"T",不然下面用curl发送数据会报错。一条数据如下所示:
{"roomid":"4","userid":"74262","adrop":"3","alat":"196","vdrop":"5","vlat":"209","ublock":"37","dblock":"39","region":"shenzhen","timestamp":"2018-12-08T00:00:00"}
通过下面脚本模拟发送http请求。
#!/bin/bash
FILE=$1
while read LINE; do
# curl -XPOST -u live_data:live_data --header "Content-Type: application/json" "http://localhost:8080/" -d ''$LINE''
sleep 0.03s # 如果实现涉及ontime,可以加上这条代码。当然,生产环境下是不需要减慢的,详细看后面flink实现总结。
echo $LINE
done < $FILE
Logstash部分
安装kafkaoutput插件bin/logstash-plugin install logstash-output-kafka
# conf文件
input {
http {
host => "localhost"
port => 8080
id => "live_data_http_input"
user => "live_data"
password => "live_data"
}
}
filter{
mutate {
remove_field => ["@timestamp", "host", "headers", "@version","tags"]
}
}
output {
kafka {
topic_id => "core_metric"
codec => json
}
}
# 测试
output {stdout {} }
Kafka部分
创建两个topic分别代表后面需要处理的两个部分。
# 启动
zkServer.sh start
kafka-server-start.sh $KAFKA_HOME/config/server.properties
# 创建topic
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic core_metric
# 测试
kafka-console-consumer.sh --zookeeper localhost:2181 --topic core_metric
Flink部分
配置/准备代码
下面是两个业务都需要配置的一些准备代码。
private static Logger logger = LoggerFactory.getLogger(CoreMetricMain.class);
private static FastDateFormat TIME_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd'T'HH:mm:ss", Locale.ENGLISH);
private static FastDateFormat INDEX_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd", Locale.ENGLISH);
// Main
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度,设置为1方便调试。
env.setParallelism(1);
// 设置使用eventtime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// checkpoint配置
env.enableCheckpointing(60000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000);
env.getCheckpointConfig().setCheckpointTimeout(10000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 设置statebackend
//env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop100:9000/flink/checkpoints",true));
/**
* 配置KafkaSource,这里原本使用flink内置的json schema,但由于数据的日期有“-”而无法转换
* 所以就用了SimpleStringSchema,后面再利用fastjson进行转换。当然,也可以自定义schema来省
* 去一次转化
*/
String topic = "core_metric";
Properties prop = new Properties();
prop.setProperty("bootstrap.servers", "localhost:9092");
prop.setProperty("group.id", "con1");
prop.setProperty("auto.offset.reset", "latest");
FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011<>(topic, new
SimpleStringSchema(), prop);
DataStreamSource<String> stream = env.addSource(myConsumer);
stream.name("KafkaSource");
// 业务代码...
env.execute("CoreMetric");
视频核心指标监控
业务目标
针对客户端APP的监控,获取以下指标:
- 房间故障,故障包括卡顿、丢帧、音视频不同步等
- 分地域统计数据端到端延迟平均情况
- 统计实时整体卡顿率(出现卡顿的在线用户数/在线总用户数*100%,通过此指标可以衡量当前卡顿影响的人群范围)
- 统计人均卡顿次数(在线卡顿总次数/在线用户数,通过此指标可以从卡顿频次上衡量整体的卡顿严重程度)
// 对从 kafka 中获取的 string 数据进行转换。这里我通过继承 flink 的 Tuple10 来实现一个 MetricRecord 的 DTO 类,
// 在里面增加getter方法,这样在取值时就不需要通过idx来取了,例如 public Integer getRoomid() {return this.f0;}。
// 但后面的代码还要对数据进行各种转换,所以每次都要重新实现一个类也是挺繁琐的事情,看自己的取舍吧。
MapFunction<String, MetricRecord> cleanMapFun = str -> {
JSONObject jsonObject = JSONObject.parseObject(str);
Date parse = TIME_FORMAT.parse(jsonObject.getString("timestamp"));
long time = parse.getTime();
return new MetricRecord(
jsonObject.getInteger("roomid"), jsonObject.getLong("userid"),
jsonObject.getInteger("adrop"), jsonObject.getInteger("alat"),
jsonObject.getInteger("vdrop"), jsonObject.getInteger("vlat"),
jsonObject.getInteger("ublock"), jsonObject.getInteger("dblock"),
time, jsonObject.getString("region"));
};
SingleOutputStreamOperator<MetricRecord> cleanStream = stream.map(cleanMapFun)
// 转换完后就可以抽取时间戳和分配 watermark 了。通过extractTimestamp,每条数据就被flink内部打上时间戳了。
// 下面是 flink 内置的类,也可以自己通过继承AssignerWithPunctuatedWatermarks或AssignerWithPeriodicWatermarks来自定义,区别看后面总结。如果是离线环境,且涉及 ontime 操作,则建议继承AssignerWithPunctuatedWatermarks来抽取时间戳和分配 watermark,因为其他实现可能不能及时推进watermark
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<MetricRecord>(Time.seconds(10)) {
@Override
public long extractTimestamp(MetricRecord record) {
return record.getTimestamp();
}
});
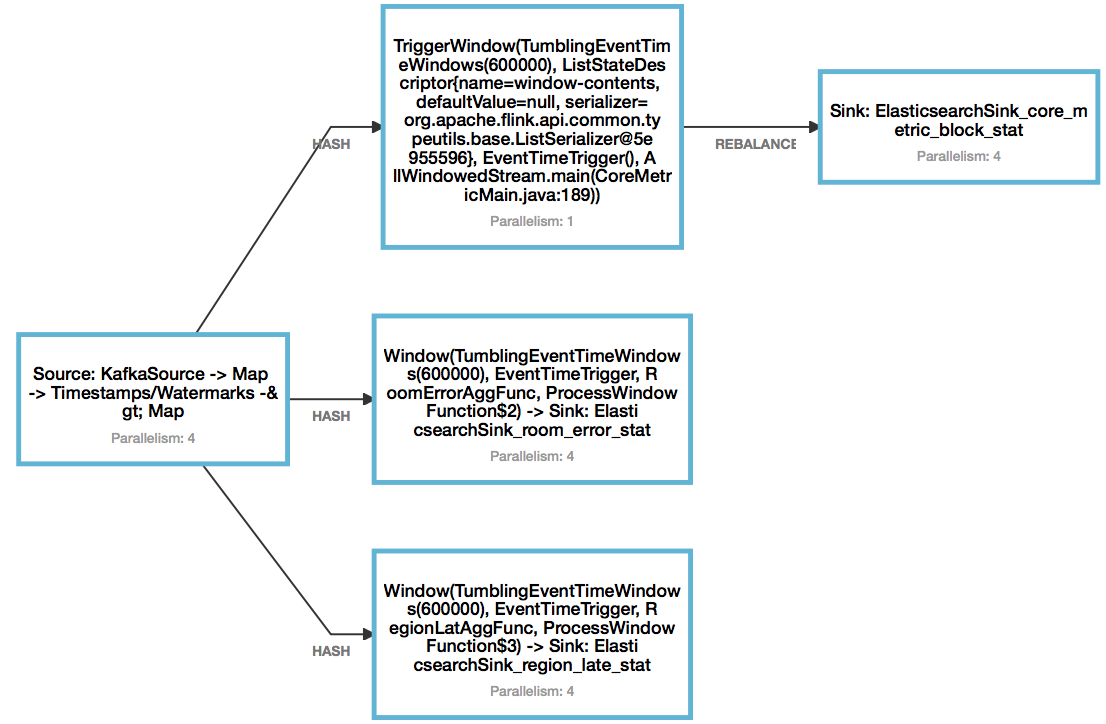
// 第一个功能:每隔10分钟计算一次这10分钟里面每个房间的卡顿、丢帧、音视频不同步等故障指标的和。
// 这里采用aggregate + ProcessWindowFunction 来完成,这样可以一有数据就进行聚合,避免窗口存储完10分钟的数据后才开始计算,但实现也比原来复杂。最后的ProcessWindowFunction仅仅只是补充时间戳作为输出。当然,也可以在aggregate的计算中一直保持时间戳。RoomErrorAggFunc的实现比较简单,可以参考第二个功能的RegionLatAggFunc实现。
SingleOutputStreamOperator<Tuple8<Integer, Integer, Integer, Integer, Integer, Integer, Integer, Long>> roomErrorStat = cleanStream
.keyBy(MetricRecord::getRoomid)
.window(TumblingEventTimeWindows.of(Time.minutes(10)))
.aggregate(new RoomErrorAggFunc(),
new ProcessWindowFunction<Tuple8<Integer, Integer, Integer, Integer, Integer, Integer, Integer, Long>,
Tuple8<Integer, Integer, Integer, Integer, Integer, Integer, Integer, Long>, Integer, TimeWindow>
() {
// 补充 watermark
@Override
public void process(Integer key, Context context,
Iterable<Tuple8<Integer, Integer, Integer, Integer, Integer, Integer, Integer, Long>> elements,
Collector<Tuple8<Integer, Integer, Integer, Integer, Integer, Integer, Integer, Long>> out) {
Tuple8<Integer, Integer, Integer, Integer, Integer, Integer, Integer, Long> res = elements.iterator().next();
res.setField(context.window().getStart(), 7);
out.collect(res);
}
});
// 第二个功能:每隔10分钟计算一次这10分钟各地域的平均延迟情况。
SingleOutputStreamOperator<Tuple4<String, Long, Long, Long>> regionLatStat = cleanStream
.keyBy(MetricRecord::getRegion)
.window(TumblingEventTimeWindows.of(Time.minutes(10)))
.aggregate(new RegionLatAggFunc(), new ProcessWindowFunction
// 补充watermark同上
}
});
// RegionLatAggFunc的实现如下
public class RegionLatAggFunc implements AggregateFunction<MetricRecord,
Tuple4<String, Long, Long, Long>, Tuple4<String, Long, Long, Long>> {
/**
* 中间结果
* 0 => region;
* 1 => alat;
* 2 => vlat;
* 3 => count
*
* 最终结果
* 0 => region
* 1 => alat;
* 2 => vlat;
* 3 => location for timestamp
*/
@Override
public Tuple4<String, Long, Long, Long> createAccumulator() {
return new Tuple4<>("", 0L, 0L, 0L);
}
@Override
public Tuple4<String, Long, Long, Long> add(MetricRecord metricRecord, Tuple4<String, Long, Long, Long> accumulator) {
accumulator.setField(metricRecord.getRegion(), 0);
accumulator.setField(metricRecord.getAlat() + accumulator.f1, 1);
accumulator.setField(metricRecord.getVlat() + accumulator.f2, 2);
accumulator.setField(accumulator.f3 + 1, 3);
return accumulator;
}
@Override
public Tuple4<String, Long, Long, Long> merge(Tuple4<String, Long, Long, Long> acc1,
Tuple4<String, Long, Long, Long> acc2) {
acc1.setField(acc1.f0, 0);
acc1.setField(acc1.f1 + acc2.f1, 1);
acc1.setField(acc1.f2 + acc2.f2, 2);
acc1.setField(acc1.f3 + acc2.f3, 3);
return acc1;
}
@Override
public Tuple4<String, Long, Long, Long> getResult(Tuple4<String, Long, Long, Long> accumulator) {
return new Tuple4<>(accumulator.f0, accumulator.f1 / accumulator.f3, accumulator.f2 / accumulator.f3, 0L);
}
}
// 第三和第四个功能可以合在一起实现,每隔10分钟计算一次这10分钟里网站总体的卡顿情况。具体看代码。
SingleOutputStreamOperator<Tuple3<Long, Double, Double>> blockStat = cleanStream
.map(elem -> {
long[] res = new long[3];
res[0] = elem.getUserid();
res[1] = elem.getUblock();
res[2] = elem.getDblock();
return res;
})
.windowAll(TumblingEventTimeWindows.of(Time.minutes(10)))
.process(new ProcessAllWindowFunction<long[], Tuple3<Long, Double, Double>,
TimeWindow>() {
@Override
public void process(Context context, Iterable<long[]> elements,
Collector<Tuple3<Long, Double, Double>> out) throws Exception {
long blockTimes = 0L;
long blockTotal = 0L;
HashSet<Long> visitorSet = new HashSet<>();
for (long[] elem : elements) {
visitorSet.add(elem[0]);
// 功能三
blockTimes += (elem[1] != 0 || elem[2] != 0 ? 1L : 0L);
// 功能四
blockTotal += elem[1] + elem[2];
}
long time = context.window().getStart();
double totalBlockRate = (double) blockTimes / visitorSet.size();
double blockPeruser = (double) blockTotal / visitorSet.size();
out.collect(new Tuple3<>(time, totalBlockRate, blockPeruser));
}
});
目前的实现如下,sink后面再说。这里可以看到第三和第四的实现采用ProcessAllWindowFunction后并行度变为了1,因为它是直接把所有的数据聚合到一起计算的。这样分布式计算就没什么意义了。在第二个业务部分会介绍更可行的方法。