Part V. Streaming
版本以2.2的Structured Streaming为主,部分也有后续新版本的说明。
Stream Processing Fundamentals
1.概念
流处理就是不断地整合新数据计算新结果。批量处理是固定输入量计算一次。Structured Stream集合这两个功能并加上交互式查询。
实时计算通常用于notifications/alerting,实时报告,累积ETL,实时决策,更新服务数据(GA),线上ML等。
2.Stream Processing Design Points
Record-at-a-Time Versus Declarative APIs
新的流系统提供declarative APIs,App定义计算什么而不是怎么计算,如DStream,Kafka。
Event Time Versus Processing Time
事件发生的事件和收到数据处理的时间。前者的记录可能乱序,有时差。
Continuous Versus Micro-Batch Execution
前者中,各个节点不断从上游节点接受信息,进行一步计算后向下游节点传递结果。这方式延迟少,但最大吞吐量低(量大的话计算慢,影响下游),且节点不能单独停止。
后者积累小批量数据,然后每批并行计算。可实现高吞吐,且需要更少节点。但有延迟。
3.Spark’s Streaming APIs
包含DStream(纯 micro-batch,declarative API,但不支持event time)和Structured Streaming(在前者基础上增加event time和continuous处理)
DStream的优势在于“high-level API interface and simple exactly-once semantics”。然而它是基于Java/Python对象和函数,与DF相比,难以优化;不支持event time;只能micro-batch
Structured Streaming以Spark的结构化API为基础,支持Spark language API,event time,更多类型的优化,正研发continuous处理(Spark 2.3)。操作跟DF几乎一样,自动转换为累积计算形式,也能导出Spakr SQL所用的表格。
Structured Streaming Basics
1.介绍和概念
Structured Streaming是建立在Spark SQL上的流处理框架,使用结构化API、Catalyst engine。 它确保end-to-end, exactly-once processing as well as fault-tolerance through checkpointing and write-ahead logs.
只需设定batch还是streaming方式,其他代码不用改。
为了整合Spark的其他模块,Structured Streaming可以使用 continous application that is an end-to-end application that reacts to data in real time by combining a variety of tools: streaming jobs, batch jobs, joins between streaming and offline data, and interactive ad-hoc queries.
截止,Spark 2.3加入Continuous Processing,实现1毫秒级别的at-least-once保证,而exactly-once保证要到100毫秒。
核心概念
-
Transformations and Actions:一些查询会受限制(还不能incrementalize),action只有start。
-
输入Sources:Kafka,分布式文件系统,A socket source for testing
-
输出sinks:Kafka,几乎所有文件形式,foreach for computation,console for testing,memory for debugg
-
输出模式(各自适用于不同的查询,“Input and Output”中介绍):append,update(2.1.1,只有被更新的数据才写到外部。如果计算没有聚合,即没有影响到之前的数据,那么就和append一样),complete
-
Triggers:什么时候输出,固定interval或固定量(在某latency下)
-
Event-Time处理:Event-time data,Watermarks(等待时间和output结果的时间)
-
容错:end-to-end exactly-once
2.Transformations and Actions
Streaming DF基本上可使用所有静态Structured APIs(inference要另外开spark.sql.streaming.schemaInference to true)
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream
.queryName("activity_counts") // 类似tempview的表名,用于下面查询
.outputMode("complete")
.format("console") // debug专用
.trigger(Trigger.ProcessingTime("2 seconds")) // 可选
.start()// 批量输出用save
query.awaitTermination()//防止driver在查询过程退出
//执行上面的代码,stream已经运行。下面对output到内存中的table进行查询
for( i <- 1 to 10 ) {
Thread.sleep(1000)
spark.sql("SELECT * FROM activity_counts").show()
}
spark.streams.active查看活动的stream
运行情况:每当查询开始,spark就会自动判断是否有新数据,有的话就将它和旧数据结合一起进行计算。但注意的是,旧数据只保留了中间结果,这个中间结果的大小就看后续计算需要用到原数据多少内容而定。比如计算最大值,那么就只需要保存至今见过的最大值的那个数据即可。
transformation细节补充
限制在不断减少。目前的限制:未进行aggregate的stream不能sort,cannot perform multiple levels of aggregation without using Stateful Processing
//所有select和filter都支持
val simpleTransform = streaming.withColumn("stairs", expr("gt like '%stairs%'"))
.where("stairs")
.where("gt is not null")
.select("gt", "model", "arrival_time", "creation_time")
.writeStream
.queryName("simple_transform")
.format("memory")
.outputMode("append")
.start()
//支持大部分Aggregations
val deviceModelStats = streaming.cube("gt", "model").avg()
.drop("avg(Arrival_time)")
.drop("avg(Creation_Time)")
.drop("avg(Index)")
.writeStream.queryName("device_counts").format("memory").outputMode("complete")
.start()
//限制在于multiple “chained” aggregations (aggregations on streaming aggregations) ,但可以通过output到sink后再aggregate来实现
//支持inner join,outer join要定义watermark
val historicalAgg = static.groupBy("gt", "model").avg()
val deviceModelStats = streaming
.drop("Arrival_Time", "Creation_Time", "Index")
.cube("gt", "model").avg()
.join(historicalAgg, Seq("gt", "model")) // inner join
.writeStream
.queryName("device_counts")
.format("memory")
.outputMode("complete")
.start()
3.Input and Output
Sources and Sinks
- File: 保存到csv或parquet
注意添加file到directory要为原子方式,否则Spark会在file未添加完成时就进行操作。在使用文件系统,如本地files或HDFS时,最好在另外一个目录写文件,完成后再移到input目录。
分区发现,在同一目录下,不能有/data/year=2016/和/data/date=2016-04-17/
- Kafka:
val ds1 = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")//连接哪个服务器
.option("subscribe", "topic1,topic2")//也可("subscribePattern", "topic.*")
.load()
使用使用原生Structured API或UDF对信息进行parse。通常用 JSON or Avro来读写Kafka
ds1.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)")//不加"topic"就在后面加.option("topic", "topic1")
.writeStream.format("kafka")
.option("checkpointLocation", "/to/HDFS-compatible/dir")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.start()
kafka的schema为key: binary;value: binary;topic: string;partition: int;offset: long;timestamp: long
读数据有三个选择:
assign:指定topic以及topic的某部分,如 JSON string{"topicA":[0,1],"topicB":[2,4]}
subscribe or subscribePattern:读取多个topics通过一列topics或一种模式(正则表达)
其他选项
startingOffsets and endingOffsets:earliest,latest或JSON string({"topicA":{"0":23,"1":-1},"topicB":{"0":-2}},-1latest,-2earliest)。这仅适用于新的streaming,重新开始时会在结束时的位置开始定位。新发现的分区会在earliest开始,最后位置为查询的范围。
failOnDataLoss:a false alarm,默认true
maxOffsetsPerTrigger:每个触发间隔处理的最大偏移量的速率限制。指定的总偏移量将按不同卷的topicPartitions按比例分割。
还有一些Kafka consumer timeouts, fetch retries, and intervals.
- Foreach sink(
foreachPartitions)
要实现ForeachWriter 接口
//每当所output的rows trigger,下面三个方法都会被启动(每个executor中)
//方法要Serializable(UDF or a Dataset map)
datasetOfString.write.foreach(new ForeachWriter[String] {
def open(partitionId: Long, version: Long): Boolean = {
// 完成所有初始化,如database connection,开始transactionsopen
//version是单调递增的ID, on a per-trigger basis
// 返回是否处理这个组rows(比如crash后,如果发现储存系统中已经有对应的version和partitionId,通过返回false来跳过)
}
def process(record: String) = {
// 对每个record的处理
}
def close(errorOrNull: Throwable): Unit = {
//只要open被调用就会启动。
//如果process时出错,如何处理已完成的部分数据
//关闭连接
}
})
错误示范:如果在open之外初始化,则会在driver进行。
- 用于测试的source和sink(不能用于生产,因不提供end-to-end容错)
//Socket source,Unix用nc -lk 9999后在console打字
val socketDF = spark.readStream.format("socket")
.option("host", "localhost").option("port", 9999).load()
//Console sink
activityCounts.format("console").write()
//Memory sink 保存到内存,供后面的代码使用
activityCounts.writeStream.format("memory").queryName("my_device_table")
如果真的想在生产中output为表格,建议用Parquet file sink
Output Modes
Append:将新数据append到Result Table中,并输出新数据。适合只涉及select, where, map, flatMap, filter, join等操作的查询。
Complete:整个Result Table输出,适合有聚合操作时使用。
Update:更新Result Table,且只有更新部分才会输出。
操作与模式匹配,比如append支持不会改变过去数据的操作,除非带有wm,否则不支持aggregation。而且aggregation结果要等到window结束且超过late threshold后才展示。而complete和update还支持没有wm的aggregation。更多的看官网。
sink与模式匹配。Kafka支持全部模式,且为at-least-once,Flie只支持Append,且为exactly-once。其他看官网。
Triggers
默认情况下,前一个trigger完成后马上开始新的。其他选项fixed interval、one-time、Continuous with fixed checkpoint interval(实验阶段)。
//Processing time trigger,如果Spark在100s内没有完成计算,Spark会等待下一个,而不是计算完成后马上计算下一个
activityCounts.writeStream
.trigger(Trigger.ProcessingTime("100 seconds"))//也可以用Duration in Scala or TimeUnit in Java
.format("console")
.outputMode("complete")
.start()
//Once trigger,测试中非常有用,常被用于低频工作(如向总结表格添加新数据)
activityCounts.writeStream
.trigger(Trigger.Once())
.format("console")
.outputMode("complete")
.start()
4.Streaming Dataset API
除了DF,也可以用Dataset的API
case class Flight(DEST_COUNTRY_NAME: String, ORIGIN_COUNTRY_NAME: String,
count: BigInt)
val dataSchema = spark.read
.parquet("/data/flight-data/parquet/2010-summary.parquet/")
.schema
val flightsDF = spark.readStream.schema(dataSchema)
.parquet("/data/flight-data/parquet/2010-summary.parquet/")
val flights = flightsDF.as[Flight]
def originIsDestination(flight_row: Flight): Boolean = {
return flight_row.ORIGIN_COUNTRY_NAME == flight_row.DEST_COUNTRY_NAME
}
flights.filter(flight_row => originIsDestination(flight_row))
.groupByKey(x => x.DEST_COUNTRY_NAME).count()
.writeStream.queryName("device_counts").format("memory").outputMode("complete")
.start()
Event-Time and Stateful Processing
Event Time:接收到信息的时间(Processing time)和实际发生时间(Processing time)有差异。网络传输中只尽量保持信息完整(有时还不完整),但是否按顺序,是否重复等不保证。
Stateful Processing(前一节所讲的):通过microbatch or a record-at-a-time 的方式,更新经过一段时间后的中间信息(state)。当执行这一处理时,Spark将中间信息存到state store(目前为内存),且通过存到checkpoint directory实现容错。
Arbitrary Stateful Processing:自定义储存什么信息,怎样更新和什么时候移除(either explicitly or via a time-out)
1.Event-Time Basics
// 基于event-time的window,words包含timestamp和word两列
word
.withWatermark("timestamp", "30 minutes")//某窗口结果为x,但是部分数据在这个窗口的最后一个timestamp过后还没到达,Spark在这会等30min,过后就不再更新x了。
.dropDuplicates("User", "timestamp")
.groupBy(window(col("timestamp"), "10 minutes"),col("User"))// 10min后再加一个参数变为Sliding windows,表示每隔多久计算一次。
.count()
.writeStream
.queryName("events_per_window")
.format("memory")
.outputMode("complete")
.start()
spark.sql("SELECT * FROM events_per_window")
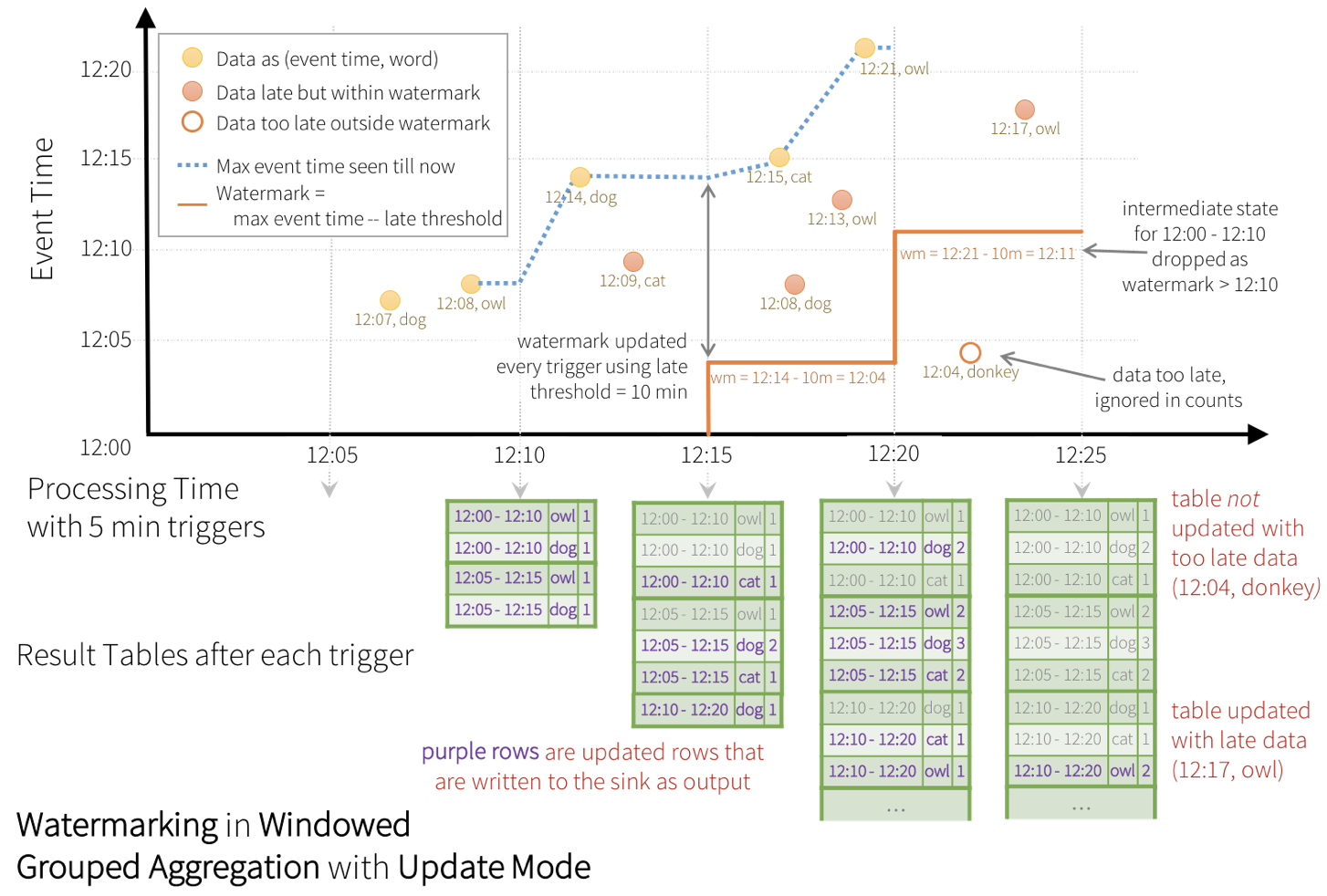
Spark的watermark = max event time seen by the engine - late threshold,相当于Flink的BoundedOutOfOrdernessTximestampExtractor。在window计算被触发时,Spark会删除结束时间低于当前wm的window的中间结果,属于该window的迟到数据“可能”会被忽略,越迟越可能被忽略,删除完后才更新wm,所以即便下一批没有数据加入,Spark所依据的wm也是新的,下下一批wm不变。
上面是update mode,如果是append模式,那么结果要等到trigger后发现window的结束时间低于更新后的水位线时才会出来。另外,max event time seen by the engine - late threshold机制意味着如果下一批计算没有更晚的数据加入,那么wm就不会前进,那么数据的append就会被延后。
Conditions for watermarking to clean aggregation state(as of Spark 2.1.1, subject to change in the future)
- 不支持complete模式。
- groupBy必须包含timestamp列或者window(col(timestamp)),withWatermark中的列要和前面的timestamp列相同
- 顺序必须是先withWatermark再到groupBy
2.Join
前提(inner join中可选,因为join没有交集可以去掉,但outer join必须设置):
- 两个input都要定义watermark。
- join条件:
- Time range join conditions (e.g.
...JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR - Join on event-time windows (e.g.
...JOIN ON leftTimeWindow = rightTimeWindow)
- Time range join conditions (e.g.
支持:
- stream-static:inner、left outer
- stream-stream:inner、outer(必须设置wm和time constraints)
限制:
- join的查询仅限append模式
- join之前不能aggregation
- update mode模式下join之前不能mapGroupsWithState and flatMapGroupsWithState
// 广告影响和点击量
val impressions = spark.readStream. ...
val clicks = spark.readStream. ...
// Apply watermarks on event-time columns
val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
// Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
// a click can occur within a time range of 0 seconds to 1 hour after the corresponding impression
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
"""),
joinType = ".." // "inner", "leftOuter", "rightOuter"
)
在outer join中,如果两个流的其中一个没有新数据,就不会trigger,join结果就会被延迟。
3.Arbitrary Stateful Processing
应用
- 每个key用一个state来计数
- 当计数达到某个值可触发警报
- 维护不确定时间的用户会话并保存这些会话以便稍后执行某些分析。
Time-Outs
给每个组/key配置的一个全局变量,它可以是处理时间(GroupStateTimeout.ProcessingTimeTimeout)或者事件时间(EventTimeTimeout)前者基于system clock,会受时区影响,后者基于数据自身携带的timestamp。
当设置time-out后,在处理值之前先检查超时,即使用state.hasTimedOut标志或检查值迭代器是否为空来获取此信息。 您需要设置一些状态(即,必须定义状态,而不是删除状态)才能设置time-out。time-out的触发时间没有上限,这种情况出现在达到time-out后没有新数据触发查询。
下面是官方例子,利用mapGroupsWithState实现的stateful操作。其中SessionInfo和SessionUpdate都是case class,前者存储state数据,后者是mapGroupsWithState返回的结果。
val sessionUpdates = events
.groupByKey(event => event.sessionId)
.mapGroupsWithState[SessionInfo, SessionUpdate](GroupStateTimeout.ProcessingTimeTimeout) {
case (sessionId: String, events: Iterator[Event], state: GroupState[SessionInfo]) =>
// 处理值之前先检查time-out
if (state.hasTimedOut) {
val finalUpdate =
SessionUpdate(sessionId, state.get.durationMs, state.get.numEvents, expired = true)
state.remove()
finalUpdate
} else {
// 没有超时就先判断是否有相应的state,没有就创建,否则就更新。
val timestamps = events.map(_.timestamp.getTime).toSeq
val updatedSession = if (state.exists) {
val oldSession = state.get
SessionInfo(
oldSession.numEvents + timestamps.size,
oldSession.startTimestampMs,
math.max(oldSession.endTimestampMs, timestamps.max))
} else {
SessionInfo(timestamps.size, timestamps.min, timestamps.max)
}
state.update(updatedSession)
// 设置超时,以便在没有收到数据10秒的情况下会话将过期
state.setTimeoutDuration("10 seconds")
SessionUpdate(sessionId, state.get.durationMs, state.get.numEvents, expired = false)
}
}
mapGroupsWithState: one row per key (or group)
flatMapGroupsWithState: multiple outputs
输出模式
mapGroupsWithState 只支持update模式;flatMapGroupsWithState 支持append(time-out后,即watermark过后才显示结果)和update
mapGroupsWithState例子:
基于user的activity(state)来更新。具体来说,如果收到的信息中,user的activity没变,就检查该信息是否早于或晚于目前所收到的信息,进而得出user某个activity的准确的持续时间(下面设置了GroupStateTimeout.NoTimeout,假设信息传输没丢失,则迟早会收到)。如果activity变了,就更新activity(时间也要重新设置)。如果没有activity,就不变。
//输入row的格式
case class InputRow(user:String, timestamp:java.sql.Timestamp, activity:String)
//表示user状态的格式(储存目前状态)
case class UserState(user:String,
var activity:String,
var start:java.sql.Timestamp,
var end:java.sql.Timestamp)
//基于某row如何更新
def updateUserStateWithEvent(state:UserState, input:InputRow):UserState = {
if (Option(input.timestamp).isEmpty) {
return state
}
if (state.activity == input.activity) {
if (input.timestamp.after(state.end)) {
state.end = input.timestamp
}
if (input.timestamp.before(state.start)) {
state.start = input.timestamp
}
} else {
if (input.timestamp.after(state.end)) {
state.start = input.timestamp
state.end = input.timestamp
state.activity = input.activity
}
}
state
}
//基于一段时间的row如何更新
def updateAcrossEvents(user:String,
inputs: Iterator[InputRow],
oldState: GroupState[UserState]):UserState = {
var state:UserState = if (oldState.exists) oldState.get else UserState(user,
"",
new java.sql.Timestamp(6284160000000L),
new java.sql.Timestamp(6284160L)
)
// we simply specify an old date that we can compare against and
// immediately update based on the values in our data
for (input <- inputs) {
state = updateUserStateWithEvent(state, input)
oldState.update(state)
}
state
}
withEventTime
.selectExpr("User as user",
"cast(Creation_Time/1000000000 as timestamp) as timestamp", "gt as activity")
.as[InputRow]
.groupByKey(_.user)
.mapGroupsWithState(GroupStateTimeout.NoTimeout)(updateAcrossEvents)
.writeStream
.queryName("events_per_window")
.format("memory")
.outputMode("update")
.start()
flatMapGroupsWithState例子
基于数量的更新,即某个指标的量达到特定值时更新。下面的代码,DeviceState记录了一段时间(计数未达到500)中,device的名字,数值,和计数。当计算到500时就求均值,并变为输出row,未达到无输出。
//输入row的格式
case class InputRow(device: String, timestamp: java.sql.Timestamp, x: Double)
//表示DeviceState状态的格式(储存目前状态)
case class DeviceState(device: String, var values: Array[Double], var count: Int)
//输出row的格式
case class OutputRow(device: String, previousAverage: Double)
//基于某row如何更新
def updateWithEvent(state:DeviceState, input:InputRow):DeviceState = {
state.count += 1
// maintain an array of the x-axis values
state.values = state.values ++ Array(input.x)
state
}
//基于一段时间的row如何更新
def updateAcrossEvents(device:String, inputs: Iterator[InputRow],
oldState: GroupState[DeviceState]):Iterator[OutputRow] = {//flatMapGroupsWithState要求Iterator?
inputs.toSeq.sortBy(_.timestamp.getTime).toIterator.flatMap { input =>
val state = if (oldState.exists) oldState.get
else DeviceState(device, Array(), 0)
val newState = updateWithEvent(state, input)
if (newState.count >= 500) {
oldState.update(DeviceState(device, Array(), 0))
Iterator(OutputRow(device,
newState.values.sum / newState.values.length.toDouble))
}
else {
oldState.update(newState)
Iterator()//未达到500无输出
}
}
}
withEventTime
.selectExpr("Device as device",
"cast(Creation_Time/1000000000 as timestamp) as timestamp", "x")
.as[InputRow]
.groupByKey(_.device)
.flatMapGroupsWithState(OutputMode.Append,
GroupStateTimeout.NoTimeout)(updateAcrossEvents)//这里NoTimeout表示,如果没达到500,则永远没有结果输出
.writeStream
.queryName("count_based_device")
.format("memory")
.outputMode("append")
.start()
下面这个例子运用了timeout
case class InputRow(uid:String, timestamp:java.sql.Timestamp, x:Double,
activity:String)
case class UserSession(val uid:String, var timestamp:java.sql.Timestamp,
var activities: Array[String], var values: Array[Double])
case class UserSessionOutput(val uid:String, var activities: Array[String],
var xAvg:Double)
def updateWithEvent(state:UserSession, input:InputRow):UserSession = {
// handle malformed dates
if (Option(input.timestamp).isEmpty) {
return state
}
state.timestamp = input.timestamp
state.values = state.values ++ Array(input.x)
if (!state.activities.contains(input.activity)) {
state.activities = state.activities ++ Array(input.activity)
}
state
}
def updateAcrossEvents(uid:String,
inputs: Iterator[InputRow],
oldState: GroupState[UserSession]):Iterator[UserSessionOutput] = {
inputs.toSeq.sortBy(_.timestamp.getTime).toIterator.flatMap { input =>
val state = if (oldState.exists) oldState.get else UserSession(
uid,
new java.sql.Timestamp(6284160000000L),
Array(),
Array())
val newState = updateWithEvent(state, input)
if (oldState.hasTimedOut) {
val state = oldState.get
oldState.remove()
Iterator(UserSessionOutput(uid,
state.activities,
newState.values.sum / newState.values.length.toDouble))
} else if (state.values.length > 1000) {
val state = oldState.get
oldState.remove()
Iterator(UserSessionOutput(uid,
state.activities,
newState.values.sum / newState.values.length.toDouble))
} else {
oldState.update(newState)
oldState.setTimeoutTimestamp(newState.timestamp.getTime(), "5 seconds")
Iterator()
}
}
}
withEventTime.where("x is not null")
.selectExpr("user as uid",
"cast(Creation_Time/1000000000 as timestamp) as timestamp",
"x", "gt as activity")
.as[InputRow]
.withWatermark("timestamp", "5 seconds")
.groupByKey(_.uid)
.flatMapGroupsWithState(OutputMode.Append,
GroupStateTimeout.EventTimeTimeout)(updateAcrossEvents)
.writeStream
.queryName("count_based_device")
.format("memory")
.start()
Unsupported Operations
- a chain of aggregations on a streaming DF
- Limit and take first N rows
- Distinct operations
- Sorting operations are supported on streaming Datasets only after an aggregation and in Complete Output Mode.
- Few types of outer joins on streaming Datasets are not supported.
- groupby().count(),不能单count
- writeStream.foreach(...),不能单foreach,而且要实现foreachwriter接口,详细看官网。
- format("console"),不能show()
Starting Streaming Queries
- Details of the output sink: Data format, location, etc.
- Output mode:
- Query name: Optionally, specify a unique name of the query for identification.
- Trigger interval: Optionally, specify the trigger interval. 如果不设定,就是一有数据就处理,处理完再看有没有新数据,然后马上再处理。如果有trigger是在处理计算时出现的,那么处理完当前数据就会马上处理trigger。
- Checkpoint location
Structured Streaming in Production
1.Fault Tolerance and Checkpointing
配置App使用checkpointing and write-ahead logs并配置查询写到checkpoint location(如HDFS)。当遇到failure时,只需重启应用,并保证它指向正确的checkpoint location
checkpoint stores all of the information about what your stream has processed thus far and what the intermediate state it may be storing is
//在运行App前,在writeStream配置
.option("checkpointLocation", "/some/location/")
2.Updating Your Application
增加一个新列或改变UDF不需要新的checkpoint目录,但如果怎加新的聚合键或根本性地改变查询就需要。
infrastructure changes有时只需重启stream,如spark.sql.shuffle.partitions,有时则需重启整个App,如Spark application configurations
3.Metrics and Monitoring
query.status , query.recentProgress(注意Input rate and processing rate和Batch duration)和Spark UI
4.Alerting
feed the metrics to a monitoring system such as the open source Coda Hale Metrics library or Prometheus, or you may simply log them and use a log aggregation system like Splunk.
5.Advanced Monitoring with the Streaming Listener(详细可能要看其他资料)
allow you to receive asynchronous updates from the streaming query in order to automatically output this information to other systems and implement robust monitoring and alerting mechanisms.
// 测试代码
val dir = new Path("/tmp/test-structured-streaming")
val fs = dir.getFileSystem(sc.hadoopConfiguration)
fs.mkdirs(dir)
val schema = StructType(StructField("vilue", StringType) ::
StructField("timestamp", TimestampType) ::
Nil)
val eventStream = spark
.readStream
.option("sep", ";")
.option("header", "false")
.schema(schema)
.csv(dir.toString)
// Watermarked aggregation
val eventsCount = eventStream
.withWatermark("timestamp", "1 hour")
.groupBy(window($"timestamp", "1 hour"))
.count
def writeFile(path: Path, data: String) {
val file = fs.create(path)
file.writeUTF(data)
file.close()
}
// Debug query
val query = eventsCount.writeStream
.format("console")
.outputMode("complete")
.option("truncate", "false")
.trigger(ProcessingTime("5 seconds"))
.start()
writeFile(new Path(dir, "file1"), """
|A;2017-08-09 10:00:00
|B;2017-08-09 10:10:00
|C;2017-08-09 10:20:00""".stripMargin)
query.processAllAvailable()
val lp1 = query.lastProgress
// -------------------------------------------
// Batch: 0
// -------------------------------------------
// +---------------------------------------------+-----+
// |window |count|
// +---------------------------------------------+-----+
// |[2017-08-09 10:00:00.0,2017-08-09 11:00:00.0]|3 |
// +---------------------------------------------+-----+
// lp1: org.apache.spark.sql.streaming.StreamingQueryProgress =
// {
// ...
// "numInputRows" : 3,
// "eventTime" : {
// "avg" : "2017-08-09T10:10:00.000Z",
// "max" : "2017-08-09T10:20:00.000Z",
// "min" : "2017-08-09T10:00:00.000Z",
// "watermark" : "1970-01-01T00:00:00.000Z"
// },
// ...
// }
writeFile(new Path(dir, "file2"), """
|Z;2017-08-09 20:00:00
|X;2017-08-09 12:00:00
|Y;2017-08-09 12:50:00""".stripMargin)
query.processAllAvailable()
val lp2 = query.lastProgress
// -------------------------------------------
// Batch: 1
// -------------------------------------------
// +---------------------------------------------+-----+
// |window |count|
// +---------------------------------------------+-----+
// |[2017-08-09 10:00:00.0,2017-08-09 11:00:00.0]|3 |
// |[2017-08-09 12:00:00.0,2017-08-09 13:00:00.0]|2 |
// |[2017-08-09 20:00:00.0,2017-08-09 21:00:00.0]|1 |
// +---------------------------------------------+-----+
// lp2: org.apache.spark.sql.streaming.StreamingQueryProgress =
// {
// ...
// "numInputRows" : 3,
// "eventTime" : {
// "avg" : "2017-08-09T14:56:40.000Z",
// "max" : "2017-08-09T20:00:00.000Z",
// "min" : "2017-08-09T12:00:00.000Z",
// "watermark" : "2017-08-09T09:20:00.000Z"
// },
// "stateOperators" : [ {
// "numRowsTotal" : 3,
// "numRowsUpdated" : 2
// } ],
// ...
// }
writeFile(new Path(dir, "file3"), "")
query.processAllAvailable()
val lp3 = query.lastProgress
// -------------------------------------------
// Batch: 2
// -------------------------------------------
// +---------------------------------------------+-----+
// |window |count|
// +---------------------------------------------+-----+
// |[2017-08-09 10:00:00.0,2017-08-09 11:00:00.0]|3 |
// |[2017-08-09 12:00:00.0,2017-08-09 13:00:00.0]|2 |
// |[2017-08-09 20:00:00.0,2017-08-09 21:00:00.0]|1 |
// +---------------------------------------------+-----+
// lp3: org.apache.spark.sql.streaming.StreamingQueryProgress =
// {
// ...
// "numInputRows" : 0,
// "eventTime" : {
// "watermark" : "2017-08-09T19:00:00.000Z"
// },
// "stateOperators" : [ ],
// ...
// }
query.stop()
fs.delete(dir, true)
Dstream
代码编写步骤:定义输入源 -> 定义transformation -> 启动,停止
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream/ textFileStream //等方法创造streams
val res = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
ssc.start()
ssc.awaitTermination()
只有一个context,它停止后就不能再启动。一个StreamingContext只能在一个JVM运行。StreamingContext和SparkContext可以分开停止,例如停止一个StreamingContext后可以开启一个新的StreamingContext。
setMaster中,local[n]要大于receivers的数量,receivers一个占一个线程。
textFileStream中,处理的文件格式要一致,文件的添加是原子性的,即把写好的文件放到一个文件夹中,或把文件重命名为要处理的文件。另外文件只会被处理一次,后续修改不起作用。