MapReduce框架主要是map和reduce阶段来计算的,map和reduce是如何协同计算的,下面直接上干货。
1 分片、格式化数据源:
输入Map阶段的数据流,必须经过分片和格式化的操作,即:
-
-
- 分片操作:指的是将源文件划分为相等的小数据块(Hadoop2.x中默认为128M),也就是分片(split),Hadoop会为每一个分片构建一个Map任务,并由该任务运行自定义的map()函数,从而处理分片里的每一条记录;
- 格式化操作:将划分好的数据片(split)格式化为<key,value>形式的数据,其中,key为偏移量,value代表每一行的内容。
-
2 执行MapTask
每个Map任务都有一个内存缓冲区(缓冲区大小为100M),输入的分片Map处理后的中间结果,会写入到缓存中。如果写入的数据达到内存的阈值(80M),则会启动一个线程将磁盘中溢出的内存写入至磁盘中,同时不影响map处理的中间结果继续写入缓存中,在溢写过程中,MapReduce框架会对Key进行排序,如果中间结果比价大,会形成多个溢写文件,则最后合并所有 溢写文件为一个文件。
3 执行Shuffle过程
MapReduce过程中,将map阶段处理的数据如何传递给reduce阶段,这是MapReduce框架中关键的一步,这个过程叫做shuffer。shuffer会将MapTask输出的处理结果数据,分发给ReduceTask,并在分发过程中,对数据Key进行分区和排序。shuffer详细流程如下图:
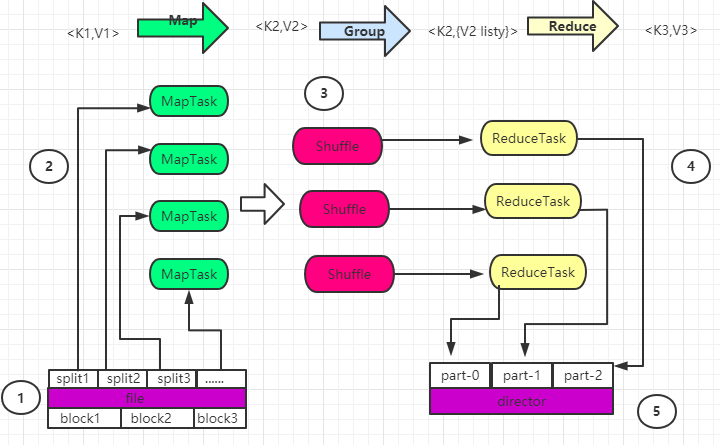
4. 执行ReduceTask
输入ReduceTask的 数据流是<key,{value list}>形式,用户可以自定义reduce函数进行逻辑处理,最终以<key,value>形式输出。
5。 写入文件
MapReduce框架会自动将ReduceTask函数生成的<key,value>数据传入OutputFormat(常用实现类为TextOutputFormat)的write方法,实现文件的写入操作。