内存管理
1.页
物理页作为内存管理的基本单位。内存管理单元通常以页为单位进行处理。
通过结构体page来表示系统中的每个物理页。
2.区
由于页位于内存中特定的物理地址上,所以不能将其用于一些特定的任务,故内核把页划分为不同的区。
硬件在内存寻址方面的问题:
- 一些硬件只能通过内存地址来执行直接内存访问(DMA)
- 一些体系结构其内存的物理寻址范围大于虚拟寻址范围,故,内存不能永久地映射到内核空间
解决方法,通过创建三种不同的分区:
- ZONE_DMA--专门执行DMA
- ZONE_NORMAL--正常映射的页
- ZONE_HIGHMEM--高端内存,不能永久映射到内核空间
3.获得页
内核提供了一种请求内存的底层机制,并提供了对它进行访问的几个接口,以页为单位分配内存。
struct page* alloc_pages(unsigned int gfp_mask, unsigned int order) //该函数分配2^order个连续的物理页,并返回第一个页的page结构体 struct page* alloc_page(unsigned int gfp_mask) //order=0 void* page_address(struct page* page) //该函数返回page物理页当前的逻辑地址 unsigned long _get_free_pages(unsigned it gfp_mask, unsigned int order) //该函数分配2^order个连续的物理页,但返回第一个页的逻辑地址 unsigned long _get_free_page(unsigned it gfp_mask) //order=0
4.释放页
申请空间了,自然总要释放掉。
void _free_pages(struct page *page, unsigned int order) void free_pages(unsigned long addr, unsigned int order) void free_page(unsigned long addr) //释放页时,要谨慎,如果释放错误的页,可能会导致系统崩溃
5.kmalloc与vmalloc
kmalloc与malloc类似,可以获得以字节为单位的一块内核内存,并且内存区在物理上是连续的。
void* kmalloc(size_t size, int flags) //flags是分类器标志 void kfree(const void* ptr) //这个要对应使用,谨慎
vmalloc的不同之处在于,分配的内存虚拟地址是连续的,而物理地址则是无需连续的。
void* vmalloc(unsigned long size) void vfree(void* addr)
大多数情况下,只有硬件设备需要得到物理地址连续的内存。vmalloc仅在为了获得大块内存时才使用。
6.Slab层
slab分配器扮演了通用数据结构缓存层的角色,
通过slab层可以缓存频繁分配和释放的数据结构,避免内存碎片,提高性能。
slab层把不同的对象划分为高速缓存组,每个高速缓存都存放不同类型的对象。然后高速缓存又被划分为不同的slab。slab由一个或多个物理上连续的页组成。每个slab有三种状态:满、部分满或空。
//创建高速缓存 kmem_cache_t* kem_cache_create(const char* name...) //销毁高速缓存 int kmem_cache_destroy(kmem_cache_t *cachep) //获取对象 void* kmem_cache_alloc(kmem_cache_t *cachep, int flags) //该函数从给定的高速缓存中返回一个指向对象的指针。如果告诉缓存的所有slab中都没有空闲对象,那么slab层必须通过kmem_getpages获取新的页 //释放对象 void kmem_cache_free(...)
7.CPU的分配
一般来说,每个CPU的数据存放在一个数组中。数组中的每一项对应着系统上存在的一个处理器。由于这个数据对于当前处理器是唯一的,其他处理器不能访问它,故不需要加锁进行操作。
使用每个CPU数据可以减少数据锁定(省去数据上锁),大大减少缓存失效(避免同步,不断刷新缓存)。
编译时的每个CPU数据
//创建一个类型为type,名字为name的实例 DECLARE_PER_CPUT(type, name); DEFINE_PER_CPU(type, name); //增加处理器上的name值 get_cput_var(name)++; //激活内核抢占 put_cput_var(name); //增加指定处理器CPU上的name值 per_cpu(name, cpu)++;
运行时的每个CPU数据
//分配对象 void* alloc_percpu(type) void* _alloc_percpu(size_t size, size_t align) //释放对象 void free_percpu(const void*)
进程地址空间
Linux操作系统采用虚拟内存技术,因此,系统中的所有进程之间以虚拟方式共享内存。
现代采用虚拟内存的操作系统通常都使用独立连续的地址空间,而不是分段的。因此,进程地址空间之间彼此互不相干,两个不同的进程可以在它们各自的地址空间的相同地址内存放不同的数据。但是,进程之间也可以选择共享地址空间,这样的进程就是所谓的线程。
进程只能访问有效范围内的内存地址。每个内存区域也具有相应进程必须遵循的特定访问属性,如只读、只写等属性。如果一个进程访问了不在有效范围中的地址,或以不正确的方式访问有效地址,那么内核就会种植该进程,并返回“段错误”信息。
1.内存描述符
//内存描述符结构体 linx/sched.h struct mm_struct{ struct vm_area_struct *mmap; .... }
fork函数通过利用copy_mm函数复制父进程的内存描述符,而子进程中的mm_struct是通过allocate_mm宏从mm_cachep slab缓存中得到的。
如果父进程希望和其子进程共享地址空间,那么在调用clone时,设置CLONE_VM标志,内核就不需要调用alloc_mm函数了,而仅仅需要用copy_mm函数将内存域指向进程的内存描述符。
调用exit_mm函数,销毁内存描述符。
注意:内核线程没有进程地址空间,也没有相关的内存描述符。所以内核线程对应的进程描述符中mm域为NULL,这也正式内核线程的真实含义--没有用户上下文。
2.内存区域
内存区域在内核中经常被称为虚拟内存区域或VMA。
内核将每个内存区域作为一个单独的内存管理对象,每个内存区域都有一直的属性。
//内存区域结构体 struct vm_area_struct{ struct mm_struct *vm_mm; ... }
3.操作内存区域
为了方便执行对内存区域的操作,内核定义了许多的辅助函数。linux/mm.h
//搜索内存区域--通过红黑树 mm/mmap.c struct vm_area_struct *find_vma(struct mm_struct* mm, unsigned long addr) //该函数在指定的地址空间中搜索第一个vm_end大于addr的内存区域 struct vm_area_struct* find_vma_prev(struct mm_struct *mm, unsigned long addr, struct vm_area_struct **pprev) //它返回第一个小于addr的VMA static inline struct vm_area_struct* find_vma_intersection(struct mm_struct *mm, unsigned long start_addr, unsigned long end_addr) //返回第一个和指定地址区间相交的VMA
4.创建删除地址空间
内核使用do_mmap()函数创建一个新的线性地址空间。这可能会导致扩展已存在的内存区域(和一个已经存在的相邻地址空间的访问权限相同)或创建一个新的区域。
//创建地址区间 unsigned long do_mmap(....) void* mmap(..) //删除地址空间 int do_munmap(...) int munmap(...)
5.页表
虽然应用程序操作的对象是映射到物理内存上的虚拟内存,但是处理器直接操作的确实物理内存。所以每当一个程序访问一个虚拟地址时,首先必须将虚拟地址转化为物理地址,然后处理器才能解析地址访问请求。地址的转换工作需要通过查询页表才能完成。也就是说,地址转换需要虚拟地址分段,每段虚拟地址都是一个索引指向页表,而页表项指向下一级别的页表或最终物理页面。
Linux使用三级页表完成地址转换,利用多级页表能够节约地址转换占用的存放空间。
- 顶级页--页全局目录(PGD),指向PMD
- 二级页--中间页目录(PMD),指向页表
- 最低级页--页表,指向物理页
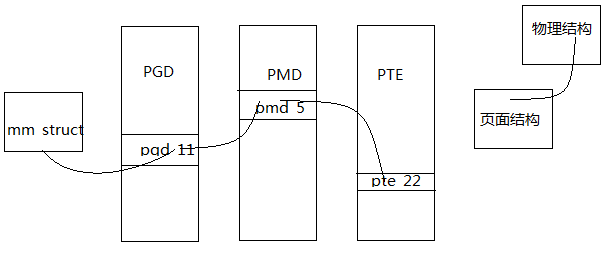
搜索页表的工作是硬件完成的。
由于几乎每次对虚拟内存的访问都需解析它,从而得到物理内存中的对应地址,所以也表操作的性能非常关键。为了加快搜索速度,多数体系结构都实现了一个翻译后缓冲器(translation lookaside buffer,TLB)。
