目前内核已经有filter 功能,但是往往实际运用中需要用到一些定制的filter 功能, 所以这个时候仅仅依靠现有的不能完成,于是就出现了conntrack的扩展功能, 最直接的就是tftp helper功能。
先看数据结构:
/* struct sk_buff { struct nf_conntrack *nfct;//指向struct nf_conn实例 .............. }; */ struct nf_conn {//每个struct nf_conn实例代表一个连接。每个skb都有一个指针,指向和它相关联的连接。 /* Usage count in here is 1 for hash table/destruct timer, 1 per skb, * plus 1 for any connection(s) we are `master' for * * Hint, SKB address this struct and refcnt via skb->nfct and * helpers nf_conntrack_get() and nf_conntrack_put(). * Helper nf_ct_put() equals nf_conntrack_put() by dec refcnt, * beware nf_ct_get() is different and don't inc refcnt. */ struct nf_conntrack ct_general; //对连接的引用计数 spinlock_t lock; u16 cpu; /* These are my tuples; original and reply */ /* Connection tracking(链接跟踪)用来跟踪、记录每个链接的信息(目前仅支持IP协议的连接跟踪)。 每个链接由“tuple”来唯一标识,这里的“tuple”对不同的协议会有不同的含义,例如对tcp,udp 来说就是五元组: (源IP,源端口,目的IP, 目的端口,协议号),对ICMP协议来说是: (源IP, 目 的IP, id, type, code), 其中id,type与code都是icmp协议的信息。链接跟踪是防火墙实现状态检 测的基础,很多功能都需要借助链接跟踪才能实现,例如NAT、快速转发、等等。*/ struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX];//正向和反向的连接元组信息。 /* 这是一个位图,是一个状态域。在实际的使用中,它通常与一个枚举类型ip_conntrack_status(位于include/linux/netfilter_ipv4/ip_conntrack.h,Line33)进行位运算来判断连接的状态。其中主要的状态包括: IPS_EXPECTED(_BIT),表示一个预期的连接 IPS_SEEN_REPLY(_BIT),表示一个双向的连接 IPS_ASSURED(_BIT),表示这个连接即使发生超时也不能提早被删除 IPS_CONFIRMED(_BIT),表示这个连接已经被确认(初始包已经发出) */ /* 可以设置由enum ip_conntrack_status中描述的状态 */ /* Have we seen traffic both ways yet? (bitset) */ unsigned long status;//该连接的连接状态 /* Timer function; drops refcnt when it goes off. */ struct timer_list timeout; //连接垃圾回收定时器 连接跟踪的超时时间 possible_net_t ct_net; /* all members below initialized via memset */ u8 __nfct_init_offset[0]; /*结构ip_conntrack_expect位于ip_conntrack.h,这个结构用于将一个预期的连接分配给现有的连接,也就是说本连接是这个master的一个预期连接*/ /* If we were expected by an expectation, this will be it */ struct nf_conn *master;//如果该连接是期望连接,指向跟其关联的主连接 #if defined(CONFIG_NF_CONNTRACK_MARK) u_int32_t mark; #endif #ifdef CONFIG_NF_CONNTRACK_SECMARK u_int32_t secmark; #endif /* Extensions */ /*指向扩展结构,该结构中包含一些基于连接的功能扩展处理函数 */ struct nf_ct_ext *ext; /* Storage reserved for other modules, must be the last member */ union nf_conntrack_proto proto; /*存储特定协议的连接跟踪信息 也就是不同协议实现连接跟踪的额外参数 */ }; /* Extensions: optional stuff which isn't permanently in struct. */ struct nf_ct_ext { struct rcu_head rcu; u16 offset[NF_CT_EXT_NUM]; u16 len; char data[0]; };


enum nf_ct_ext_id { NF_CT_EXT_HELPER, #if defined(CONFIG_NF_NAT) || defined(CONFIG_NF_NAT_MODULE) NF_CT_EXT_NAT, #endif NF_CT_EXT_SEQADJ, NF_CT_EXT_ACCT, #ifdef CONFIG_NF_CONNTRACK_EVENTS NF_CT_EXT_ECACHE, #endif #ifdef CONFIG_NF_CONNTRACK_ZONES NF_CT_EXT_ZONE, #endif #ifdef CONFIG_NF_CONNTRACK_TIMESTAMP NF_CT_EXT_TSTAMP, #endif #ifdef CONFIG_NF_CONNTRACK_TIMEOUT NF_CT_EXT_TIMEOUT, #endif #ifdef CONFIG_NF_CONNTRACK_LABELS NF_CT_EXT_LABELS, #endif #if IS_ENABLED(CONFIG_NETFILTER_SYNPROXY) NF_CT_EXT_SYNPROXY, #endif NF_CT_EXT_NUM, };
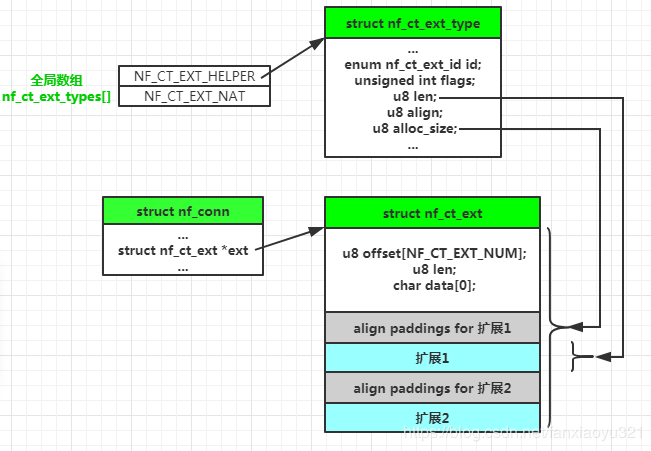
连接跟踪信息块中的ext字段的类型为struct nf_ct_ext,它指向的内存区域包含了一个用于管理扩展信息的头部以及当前添加的所有扩展。
offset[i]表示的ID为i的扩展距离data指针的偏移,len表示ext所指整块内存的长度;每个扩展有两部分组成:为了对齐可能有的paddng以及扩展本身。
扩展具体是什么类型是由注册该扩展的模块决定的,每个需要使用扩展的模块都会有一个ID,
系统中所有的扩展类型保存在全局数组nf_ct_ext_types
struct nf_ct_ext_type { /* Destroys relationships (can be NULL). */ void (*destroy)(struct nf_conn *ct); /* Called when realloacted (can be NULL). Contents has already been moved. */ void (*move)(void *new, void *old); //每种扩展有一个唯一的类型标识,定义见上方 enum nf_ct_ext_id id; unsigned int flags; /* Length and min alignment. */ u8 len;//实际扩展结构的长度 u8 align;///实际扩展结构需要几字节对齐 /* initial size of nf_ct_ext. */
//给连接添加第一个扩展功能时,这时struct nf_ct_ext还没创建, // 需要申请struct nf_ct_ext 和扩展功能私有数据一起的内存大小。 u8 alloc_size;//实际一个扩展结构需要分配的内存大小,由三部分组成:struct nf_ct_ext + 对齐填充 + len };
扩展类型的注册
扩展都是可选的,开启时对应的模块会向连接跟踪子系统注册各自的扩展:以helper为例
/* This MUST be called in process context. */ int nf_ct_extend_register(struct nf_ct_ext_type *type) { int ret = 0; mutex_lock(&nf_ct_ext_type_mutex); //每种类型的扩展只能注册一种 if (nf_ct_ext_types[type->id]) { ret = -EBUSY; goto out; } /* This ensures that nf_ct_ext_create() can allocate enough area before updating alloc_size */ //计算实际需要为扩展结构分配的内存的大小 type->alloc_size = ALIGN(sizeof(struct nf_ct_ext), type->align) + type->len; //将要注册的扩展类型注册到全局数组中 rcu_assign_pointer(nf_ct_ext_types[type->id], type); update_alloc_size(type); out: mutex_unlock(&nf_ct_ext_type_mutex); return ret;
来看下是怎么和conntrack建立连接的:先看数据结构
static struct nf_ct_ext_type helper_extend __read_mostly = { .len = sizeof(struct nf_conn_help), .align = __alignof__(struct nf_conn_help), .id = NF_CT_EXT_HELPER, }; /* nf_conn feature for connections that have a helper */ struct nf_conn_help { /* Helper. if any */ struct nf_conntrack_helper __rcu *helper;//指向相应的Netfiler中注册的helper实例 struct hlist_head expectations; //如果有多个相关联的期望连接,链接起来 /* Current number of expected connections */ u8 expecting[NF_CT_MAX_EXPECT_CLASSES]; /* private helper information. */ char data[]; };
创建新连接函数init_conntrack()中,如果新的连接不是一个期望连接,那么会查找该连接是否有helper模块关注,如果有,那么会调用nf_ct_helper_ext_add()为新的连接跟踪信息块设置ext字段,相关代码如下:
/* Allocate a new conntrack: we return -ENOMEM if classification failed due to stress. Otherwise it really is unclassifiable. */ static struct nf_conntrack_tuple_hash * init_conntrack(struct net *net, struct nf_conn *tmpl, const struct nf_conntrack_tuple *tuple, struct nf_conntrack_l3proto *l3proto, struct nf_conntrack_l4proto *l4proto, struct sk_buff *skb, unsigned int dataoff, u32 hash) { struct nf_conn *ct; struct nf_conn_help *help; struct nf_conntrack_tuple repl_tuple; struct nf_conntrack_ecache *ecache; struct nf_conntrack_expect *exp = NULL; const struct nf_conntrack_zone *zone; struct nf_conn_timeout *timeout_ext; struct nf_conntrack_zone tmp; unsigned int *timeouts; /* 根据tuple制作一个repl_tuple。主要是调用L3和L4的invert_tuple方法 */ if (!nf_ct_invert_tuple(&repl_tuple, tuple, l3proto, l4proto)) { pr_debug("Can't invert tuple. "); return NULL; } /* 在cache中申请一个nf_conn结构,把tuple和repl_tuple赋值给ct的tuplehash[]数组, 并初始化ct.timeout定时器函数为death_by_timeout(),但不启动定时器。 * */ zone = nf_ct_zone_tmpl(tmpl, skb, &tmp); ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC, hash); if (IS_ERR(ct)) return (struct nf_conntrack_tuple_hash *)ct; if (tmpl && nfct_synproxy(tmpl)) { nfct_seqadj_ext_add(ct); nfct_synproxy_ext_add(ct); } timeout_ext = tmpl ? nf_ct_timeout_find(tmpl) : NULL; if (timeout_ext) { timeouts = nf_ct_timeout_data(timeout_ext); if (unlikely(!timeouts)) timeouts = l4proto->get_timeouts(net); } else { timeouts = l4proto->get_timeouts(net); } /* 对tcp来说,下面函数就是将L4层字段如window, ack等字段 赋给ct->proto.tcp.seen[0],由于新建立的连接才调这里,所以 不用给reply方向的ct->proto.tcp.seen[1]赋值 */ if (!l4proto->new(ct, skb, dataoff, timeouts)) { nf_conntrack_free(ct); pr_debug("can't track with proto module "); return NULL; } if (timeout_ext) nf_ct_timeout_ext_add(ct, rcu_dereference(timeout_ext->timeout), GFP_ATOMIC); /* 为acct和ecache两个ext分配空间。不过之后一般不会被初始化,所以用不到 */ nf_ct_acct_ext_add(ct, GFP_ATOMIC); nf_ct_tstamp_ext_add(ct, GFP_ATOMIC); nf_ct_labels_ext_add(ct); ecache = tmpl ? nf_ct_ecache_find(tmpl) : NULL; nf_ct_ecache_ext_add(ct, ecache ? ecache->ctmask : 0, ecache ? ecache->expmask : 0, GFP_ATOMIC); local_bh_disable(); /* 会在全局的期望连接链表expect_hash中查找是否有匹配新建tuple的期望连接。第一次过来的数据包肯定是没有的, 于是走else分支,__nf_ct_try_assign_helper()函数去nf_ct_helper_hash哈希表中匹配当前tuple, 由于我们在本节开头提到nf_conntrack_tftp_init()已经把tftp的helper extension添加进去了, 所以可以匹配成功,于是把找到的helper赋值给nfct_help(ct)->helper,而这个helper的help方法就是tftp_help()。 当tftp请求包走到ipv4_confirm的时候,会去执行这个help方法,即tftp_help(),也就是建立一个期望连接 当后续tftp传输数据时,在nf_conntrack_in里面,新建tuple后,在expect_hash表中查可以匹配到新建tuple的期望连接(因为只根据源端口来匹配), 因此上面代码的if成立,所以ct->master被赋值为exp->master,并且,还会执行exp->expectfn()函数,这个函数上面提到是指向nf_nat_follow_master()的, 该函数根据ct的master来给ct做NAT,ct在经过这个函数处理前后的tuple分别为: */ /* 在helper 函数中 回生成expect 并加入全局链表 同时 expect_count++*/ if (net->ct.expect_count) { /* 如果在期望连接链表中 */ spin_lock(&nf_conntrack_expect_lock); exp = nf_ct_find_expectation(net, zone, tuple); /* 如果在期望连接链表中 */ if (exp) { pr_debug("expectation arrives ct=%p exp=%p ", ct, exp); /* Welcome, Mr. Bond. We've been expecting you... */ __set_bit(IPS_EXPECTED_BIT, &ct->status); /* conntrack的master位指向搜索到的expected,而expected的sibling位指向conntrack……..解释一下,这时候有两个conntrack, 一个是一开始的初始连接(比如69端口的那个)也就是主连接conntrack1, 一个是现在正在处理的连接(1002)子连接conntrack2,两者和expect的关系是: 1. expect的sibling指向conntrack2,而expectant指向conntrack1, 2. 一个主连接conntrack1可以有若干个expect(int expecting表示当前数量),这些 expect也用一个链表组织,conntrack1中的struct list_head sibling_list就是该 链表的头。 3. 一个子连接只有一个主连接,conntrack2的struct ip_conntrack_expect *master 指向expect 通过一个中间结构expect将主连接和子连接关联起来 */ /* exp->master safe, refcnt bumped in nf_ct_find_expectation */ ct->master = exp->master; if (exp->helper) {/* helper的ext以及help链表分配空间 */ help = nf_ct_helper_ext_add(ct, exp->helper, GFP_ATOMIC); if (help) rcu_assign_pointer(help->helper, exp->helper); } #ifdef CONFIG_NF_CONNTRACK_MARK ct->mark = exp->master->mark; #endif #ifdef CONFIG_NF_CONNTRACK_SECMARK ct->secmark = exp->master->secmark; #endif NF_CT_STAT_INC(net, expect_new); } spin_unlock(&nf_conntrack_expect_lock); } if (!exp) {// 如果不存在 从新赋值 ct->ext->...->help->helper = helper __nf_ct_try_assign_helper(ct, tmpl, GFP_ATOMIC); NF_CT_STAT_INC(net, new); } /* Now it is inserted into the unconfirmed list, bump refcount */ nf_conntrack_get(&ct->ct_general); /* 将这个tuple添加到unconfirmed链表中,因为数据包还没有出去, 所以不知道是否会被丢弃,所以暂时先不添加到conntrack hash中 */ nf_ct_add_to_unconfirmed_list(ct); local_bh_enable(); if (exp) { if (exp->expectfn) exp->expectfn(ct, exp); nf_ct_expect_put(exp); } return &ct->tuplehash[IP_CT_DIR_ORIGINAL]; }
// 连接建立时给conntrack添加helper扩展功能 struct nf_conn_help * nf_ct_helper_ext_add(struct nf_conn *ct, struct nf_conntrack_helper *helper, gfp_t gfp) { struct nf_conn_help *help; help = nf_ct_ext_add_length(ct, NF_CT_EXT_HELPER, helper->data_len, gfp); if (help) INIT_HLIST_HEAD(&help->expectations); else pr_debug("failed to add helper extension area"); return help; }
void *__nf_ct_ext_add_length(struct nf_conn *ct, enum nf_ct_ext_id id, size_t var_alloc_len, gfp_t gfp) { struct nf_ct_ext *old, *new; int i, newlen, newoff; struct nf_ct_ext_type *t; /* Conntrack must not be confirmed to avoid races on reallocation. */ NF_CT_ASSERT(!nf_ct_is_confirmed(ct)); //之前该连接跟踪信息块上还没有任何扩展,那么按照注册时的对齐以及 //扩展大小分配内存,对于刚分配的连接跟踪信息块, old = ct->ext; if (!old)/*如果该conntrack的扩展功能的内存还没用申请,就申请内存并添加该扩展功能*/ return nf_ct_ext_create(&ct->ext, id, var_alloc_len, gfp); if (__nf_ct_ext_exist(old, id))//不能在同一个连接上重复添加相同类型的扩展 return NULL; rcu_read_lock();//从全局数组中找到扩展类型,该扩展类型之前已经注册de t = rcu_dereference(nf_ct_ext_types[id]); BUG_ON(t == NULL); newoff = ALIGN(old->len, t->align);//新扩展添加到ext->data数组的末尾,计算偏移量和新的总大小 newlen = newoff + t->len + var_alloc_len; rcu_read_unlock(); //需要重新分配 new = __krealloc(old, newlen, gfp); if (!new) return NULL; if (new != old) { for (i = 0; i < NF_CT_EXT_NUM; i++) { if (!__nf_ct_ext_exist(old, i)) continue; rcu_read_lock(); t = rcu_dereference(nf_ct_ext_types[i]); if (t && t->move)//将之前ext的内容拷贝到新内存区域的开始 t->move((void *)new + new->offset[i], (void *)old + old->offset[i]); rcu_read_unlock(); }//将原来的内存区域释放并ext指向新的内存 kfree_rcu(old, rcu); ct->ext = new; } new->offset[id] = newoff; new->len = newlen; memset((void *)new + newoff, 0, newlen - newoff); return (void *)new + newoff; } static void* nf_ct_ext_create(struct nf_ct_ext **ext, enum nf_ct_ext_id id, gfp_t gfp) { unsigned int off, len; struct nf_ct_ext_type *t; rcu_read_lock(); t = rcu_dereference(nf_ct_ext_types[id]); BUG_ON(t == NULL); off = ALIGN(sizeof(struct nf_ct_ext), t->align); len = off + t->len; rcu_read_unlock(); *ext = kzalloc(t->alloc_size, gfp); if (!*ext) return NULL; (*ext)->offset[id] = off; (*ext)->len = len; return (void *)(*ext) + off; } 当前连接跟踪信息块只关联了一个扩展,分配都很简单