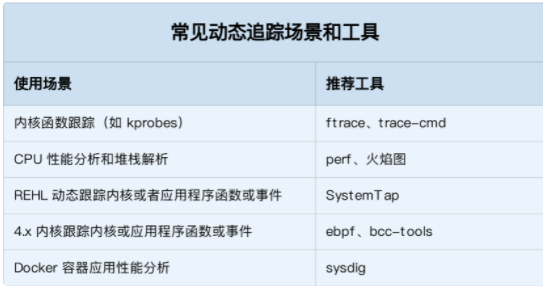
应老朋友请求整理一份 网络编程用到的工具以及socket 编程使用的相关参数
- perf
- systap
- valgrind
- dropwatch
- netstat -s netstat -i ss -s
- ethtool -S
-
ethtool -c 硬中断合并 ethtool -lethtool -g eth0 RingBuffer监控与调优-
ethtool -k -i 查看相关特性 - ip -s addr show dev ens33
-
-
/proc/sys目录可以查看或修改内核参数 -
/proc/cpuinfo可以查看CPU信息 -
/proc/meminfo可以查看内存信息 -
/proc/interrupts统计所有的硬中断 -
/proc/softirqs统计的所有的软中断信息 -
/proc/slabinfo统计了内核数据结构的slab内存使用情况 -
/proc/net/dev可以看到一些网卡统计数据 /sys/class/net/eth0/statistics/包含了网卡的统计信息
-
- /proc/softirqs /proc/interrupts
- ifconfig
- netstat -nat ss
- cat /proc/net/sockstat cat /proc/net/sockstat6
- ifconfig
- ftrace
- free top lsof uptime readelf file nm vmstat pidstat sar ps strace mpstat df du
- valgrind -e -b查看线程调用栈找到性能瓶颈
- 频繁gdb查看调用栈找到性能瓶颈
- 查看内核调用栈找到性能瓶颈
https://www.cnblogs.com/codestack/p/11151950.html
以前的好友让帮忙整理一下tcp socket编程的只是考察点:
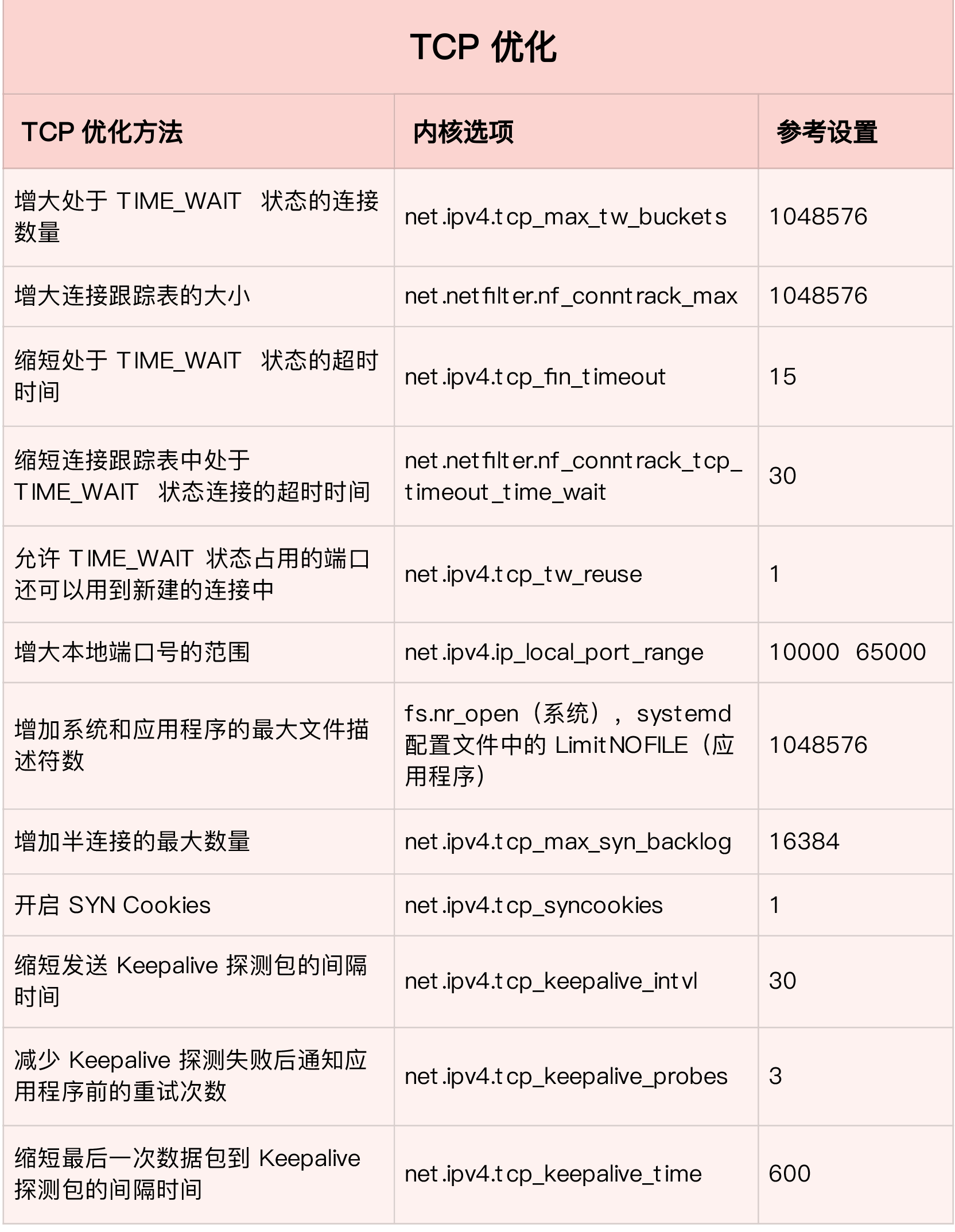
- tcp_syncookies :开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭
- tcp_tw_reuse :开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;要同时开启tcp_tw_reuse选项和tcp_timestamps 选项才可以开启TIME_WAIT重用
-
tcp_tw_recycle :表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭 -
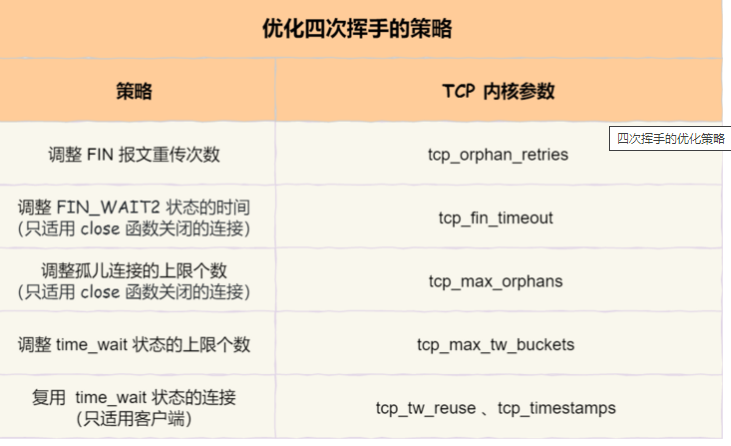
tcp_fin_timeout:表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间 -
tcp_keepalive_time:TCP发送keepalive消息的间隔;缺省值2小时--7200秒 - tcp_keepalive_intvl:当探测没有确认时,重新发送探测的频度。缺省是75秒,当探测被确认后,多长时间再次发送探测:见set_opt
TCP_KEEPIDLE选项,其值保存在tcp_keepalive_time里面 - tcp_keepalive_probes:在认定连接失效之前,发送多少个TCP的keepalive探测包。缺省值是9。这个值乘以tcp_keepalive_intvl之后决定了,一个连接发送了keepalive之后可以有多少时间没有回应。
-
ip_local_port_range :表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000 - tcp_max_syn_backlog :表示SYN队列的长度,默认为1024,决定了系统中处于 SYN_RECV 状态的 TCP 连接数量。
-
tcp_max_tw_buckets: 表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息 -
tcp_syn_retries :在内核放弃建立连接之前发送SYN包的数量,也就是重传次数,指数时间间隔重传 - tcp_synack_retries:决定了内核放弃连接之前发送SYN+ACK包的数量,也就是三次握手中的第二次握手重传的次数
- somaxconn :此参数和tcp_max_syn_backlog 有关联,后者指的是还在三次握手的半连接的上限,该参数指的是处于 ESTABLISHED 等待连接的数量上限。listen(2) 函数中的参数 backlog 同样是指明监听的端口处于 等待连接ESTABLISHED 的数量上限,当 backlog 大于 net.core.somaxconn时,以 net.core.somaxconn 参数为准
- tcp_abort_on_overflow:accept 队列已满,只能丢弃连接吗?默认是丢弃;丢弃连接只是 Linux 的默认行为,我们还可以选择向客户端发送 RST 复位报文,告诉客户端连接已经建立失败。打开这一功能需要将 tcp_abort_on_overflow 参数设置为 1。
- tcp_max_orphans:系统所能处理不属于任何进程的TCP sockets最大数量, 也就是系统允许的孤儿socket数量,each orphan eats up to ~64 KB of unswappable memory, 每个孤儿套接字最多能够吃掉你64K不可交换的内存 ;超过max_orphans 时会直接发出rst报文释放socket
- tcp_orphan_retries:本端试图关闭TCP连接之前重试多少次。缺省值是7,相当于50秒~16分钟(取决于RTO)。如果你的机器是一个重载的WEB服务器,你应该考虑减低这个值,因为这样的套接字会消耗很多重要的资源 ;控制主动关闭段发送FIN,没有收到回应,重复发送FIN的次数。由于发送了FIN,处于FIN_WAIT_1状态
- tcp_retries1:
This is how many retries it does before it * tries to figure out if the gateway is * down. Minimal RFC value is 3; it corresponds * to ~3sec-8min depending on RTO;重传不能无限的进行下去,当重传的次数超过设定的上限时,就会判定连接超时,关闭该连接
此后相应的socket函数,比如connect和send,就会返回-1,errno设为ETIMEDOUT,表示连接;一旦重传超过阈值tcp_retries1,主要的动作就是更新路由缓存。
用以避免由于路由选路变化带来的问题 - tcp_retries2 :重传超过tcp_retries2会直接放弃重传,关闭TCP流 。 代码相关见code1
- wmem_default:内核黙认发送缓冲区 创建socket 设置sk的buf时 会用到!! 见code2
- wmem_max:内核最大发送缓冲区 这些都是对所有的socket哦 udp tcp stcp raw socket 等 对于tcp 择优tcp_rmem 等再次具体设置对比
- rmem_default :内核黙认接收缓冲
- rmem_max :内核最大接收缓冲 16M
- SO_SNDBUF/SO_RCVBUF:是个体化的设置;只会影响到设置过的连接,而不会对其他连接生效;SO_SNDBUF表示这个连接上的内核写缓存上限。实际上,进程设置的SO_SNDBUF也并不是真的上限,
在内核中会把这个值翻一倍再作为写缓存上限使用;这个值也不是可以由着进程随意设置的,它会受制于系统级的上下限,当它大于上面的系统配置wmem_max(net.core.wmem_max)时,
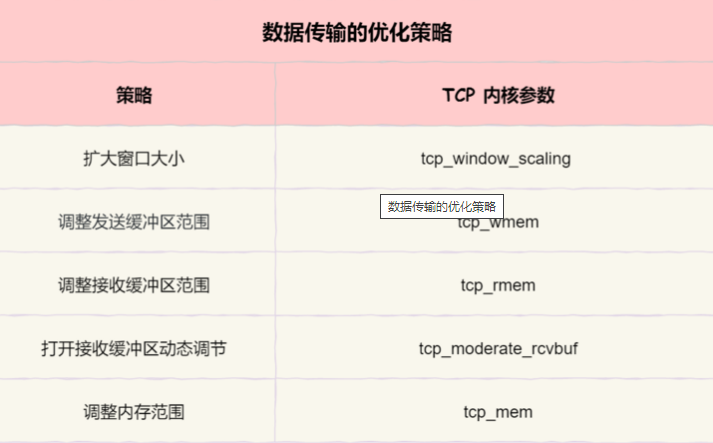
将会被wmem_max替代(同样翻一倍);当它特别小时 也会被最小值替换;SO_RCVBUF 和SO_SNDBUF一样。 - 在并发连接比较少时,把缓存限制放大一些,让每一个TCP连接开足马力工作;当并发连接很多时,此时系统内存资源不足,那么就把缓存限制缩小一些,使每一个TCP连接的缓存尽量的小一些,以容纳更多的连接。linux为了实现这种场景,引入了自动调整内存分配的功能,由tcp_moderate_rcvbuf配置决定,如下:
net.ipv4.tcp_moderate_rcvbuf = 1
默认tcp_moderate_rcvbuf配置为1,表示打开了TCP内存自动调整功能。若配置为0,这个功能将不会生效(慎用)。在编程中对连接设置了SO_SNDBUF、SO_RCVBUF,将会使linux内核不再对这样的连接执行自动调整功能! - 1、https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt 2、http://man7.org/linux/man-pages/man7/tcp.7.html 3
- tcp_wmem: 3个INTEGER变量【min, default, max】; min:为TCP socket预留用于发送缓冲的内存最小值。每个tcp socket都可以在建议以后都可以使用它。默认值为4096(4K)。default:为TCP socket预留用于发送缓冲的内存数量,默认情况下该值会影响其它协议使用的net.core.wmem_default 值,一般要低于net.core.wmem_default的值。默认值为16384(16K);max: 用于TCP socket发送缓冲的内存最大值。该值不会影响net.core.wmem_max,"静态"选择参数SO_SNDBUF则不受该值影响。默认值为131072(128K)
- tcp_rmem:(3个INTEGER变量): min, default, max
min:为TCP socket预留用于接收缓冲的内存数量,即使在内存出现紧张情况下tcp socket都至少会有这么多数量的内存用于接收缓冲,默认值为8K;default:为TCP socket预留用于接收缓冲的内存数量,默认情况下该值影响其它协议使用的 net.core.wmem_default 值。该值决定了在tcp_adv_win_scale、tcp_app_win和tcp_app_win=0默认值情况下,TCP窗口大小为65535。默认值为87380;max:用于TCP socket接收缓冲的内存最大值。该值不会影响 net.core.wmem_max,"静态"选择参数 SO_SNDBUF则不受该值影响。默认值为 128K。默认值为87380*2bytes - tcp_mem:(3个INTEGER变量):[low, pressure, high]
low:当TCP使用了低于该值的内存页面数时,TCP不会考虑释放内存;pressure:当TCP使用了超过该值的内存页面数量时,TCP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态;high:允许所有tcp sockets用于排队缓冲数据报的页面 - netdev_max_backlog:该参数决定了,网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
- tcp_window_scaling:一般来说TCP/IP允许窗口尺寸达到65535字节。对于速度确实很高的网络而言这个值可能还是太小。要支持超过 64KB 的窗口,选项允许设置上G字节的窗口大小,必须启用该值;有利于在带宽*延迟很大的环境中使用。 RFC 1323 定义的 window scaling;
- ip_conntrack_max:最大跟踪连接数
- tcp_sack:启用有选择的应答(1表示启用),通过有选择地应答乱序接收到的报文来提高性能,让发送者只发送丢失的报文段,(对于广域网通信来说)这个选项应该启用,但是会增加对CPU的占用
- tcp_timestamps:以一种比重发超时更精确的方法(请参阅 RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项。
- tcp_mtu_probing:tcp socket 是否开启mtu探测,如果开启了,在满足一定条件下才会发出mtu 探测报文,见之前的文章(没完结):https://www.cnblogs.com/codestack/p/11920465.html
-
TCP_NODELAY :设置TCP_NODELAY 用来关闭Nagle算法 算法,见内核TCP_NAGLE_OFF标志
- TCP_CORK: 设置 TCP_CORK用来开启关闭 cork 算法,见内核TCP_NAGLE_CORK标志 https://www.cnblogs.com/codestack/p/11116663.html
- SO_REUSEADDR:主要用于对TCP套接字处于TIME_WAIT状态下的socket 重复绑定使用
- SO_REUSEPORT:The new socket option allows multiple sockets on the same host to bind to the same port, and is intended to improve the performance of multithreaded network server applications running on top of multicore systems.支持多个进程或者线程绑定到同一端口,提高服务器程序的性能
- TCP_SYNCNT:syn 重传次数,设置了后对此socket 生效 //内核重传定时器优先使用TCP_SYNCNT socket选项,如果没用采用通用的sysctl 选项
max_retries = icsk->icsk_syn_retries ? : net->ipv4.sysctl_tcp_synack_retries; 或者 retry_until = icsk->icsk_syn_retries ? : net->ipv4.sysctl_tcp_syn_retries; - SO_LINGER:socket层面的选项,通过struct linger结构来设置信息,用于非正常关闭tcp连接, Sets or gets the SO_LINGER option. The argument is a linger structure. struct linger { int l_onoff; /* linger active */ int l_linger; /* how many seconds to linger for */ }; When enabled, a close(2) or shutdown(2) will not return until all queued messages for the socket have been successfully sent or the linger timeout has been reached. Otherwise, the call returns immediately and the closing is done in the background. When the socket is closed as part of exit(2), it always lingers in the background. https://man7.org/linux/man-pages/man7/socket.7.html
- TCP_LINGER2:该选项是TCP层面的,用于设定孤儿套接字在FIN_WAIT2状态的生存时间,该选项可以用来替代系统级别的tcp_fin_timeout配置;https://man7.org/linux/man-pages/man7/tcp.7.html
- SO_SNDBUFFORCE SO_RCVBUFFORCE:so_sndbuff/rcvbuf 可以修改socket的读写缓存buffer,但是受到sysctl_rmem_max*2的限制,不能超过 mem_max*2的大小;SO_SNDBUFFORCE和SO_RCVBUFFORCE,它们不受发送和接收缓冲区大小上限的限制,可设置不小于2K的任意缓冲区大小,Using this socket option, a privileged (CAP_NET_ADMIN) process can perform the same task as SO_RCVBUF, but the rmem_max limit can be overridden.
- SO_ERROR:通常情况下,在一个socket fd上出现错误时,可以通过
getsockopt(fd, SOL_SOCKET, SO_ERROR, (void*) &status, &slen);来获取具体的错误原因!! - SO_RCVTIMEO SO_SNDTIMEO:分别用来设置阻塞socket接收数据超时时间和发送数据超时时间;如果send/rcv返回值为0则为成功,-1为失败,这时可以查看errno来判断失败原因
- TCP_KEEPIDLE:The time (in seconds) the connection needs to remain idle before TCP starts sending keepalive probes, if the socket option SO_KEEPALIVE has been set on this socket. This option should not be used in code intended to be portable. 见tcp_keepalive_time
- TCP_FASTOPEN:设置值保存在net.ipv4.tcp_fastopen ,通过setsockopt(sfd, IPPROTO_TCP/*SOL_TCP*/, 23/*TCP_FASTOPEN*/, &qlen, sizeof(qlen));设置开启关闭TFO功能
- TCP_DEFER_ACCEPT 优化 使用TCP_DEFER_ACCEPT可以减少用户程序hold的连接数,也可以减少用户调用epoll_ctl和epoll_wait的次数,从而提高了程序的性能。
设置listen套接字的TCP_DEFER_ACCEPT选项后, 只当一个链接有数据时是才会从accpet中返回(而不是三次握手完成)。所以节省了一次读第一个http请求包的过程,减少了系统调
查询资料,TCP_DEFER_ACCEPT是一个很有趣的选项,
Linux 提供的一个特殊 setsockopt , 在 accept 的 socket 上面,只有当实际收到了数据,才唤醒正在 accept 的进程,可以减少一些无聊的上下文切换。代码如下。
val = 5;
setsockopt(srv_socket->fd, SOL_TCP, TCP_DEFER_ACCEPT, &val, sizeof(val)) ;
里面 val 的单位是秒,注意如果打开这个功能,kernel 在 val 秒之内还没有收到数据,不会继续唤醒进程,而是直接丢弃连接。
经过测试发现,设置TCP_DEFER_ACCEPT选项后,服务器受到一个CONNECT请求后,操作系统不会Accept,也不会创建IO句柄。操作系统应该在若干秒,(但肯定远远大于上面设置的1s) 后,
会释放相关的链接。但没有同时关闭相应的端口,所以客户端会一直以为处于链接状态。如果Connect后面马上有后续的发送数据,那么服务器会调用Accept接收这个链接端口。
感觉了一下,这个端口设置对于CONNECT链接上来而又什么都不干的攻击方式处理很有效。我们原来的代码都是先允许链接,然后再进行超时处理,比他这个有点Out了。不过这个选项可能会导致定位某些问题麻烦。
timeout = 0表示取消 TCP_DEFER_ACCEPT选项
性能四杀手:内存拷贝,内存分配,进程切换,系统调用。TCP_DEFER_ACCEPT 对性能的贡献,就在于 减少系统调用了。 - SO_RCVLOWAT/SO_SNDLOWAT:每个套接口都有一个接收low阈值和一个发送low阈值,对于TCP套接口而言,接收缓冲区中的数据必须达到规定数量,内核才通知进程“可读”,才可能触发select或者epoll。每个套接字有一个接收低水位和一个发送低水位。他们由select poll等函数使用。
接收低水位标记是让select返回”可读”时套接字接收缓冲区中所需的数据量。对于TCP,其默认值为1。
发送低水位标记是让select返回”可写”时套接字发送缓冲区中所需的可用空间。对于TCP,其默认值常为2048 - IP_HDRINCL:用于raw socket 编程编写自己的IP数据包首部时,可以在原始套接字上设置套接字选项IP_HDRINCL.在不设置这个选项的情况下,IP协议自动填充IP数据包的首部

code1:
// RTO timer的处理函数是tcp_retransmit_timer(),与tcp_retries1相关的代码调用关系如下 tcp_retransmit_timer() => tcp_write_timeout() // 判断是否重传了足够的久 => retransmit_timed_out(sk, sysctl_tcp_retries1, 0, 0) // 判断是否超过了阈值 // tcp_write_timeout()的具体相关内容 ... if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) { // 如果超时发生在三次握手期间,此时有专门的tcp_syn_retries来负责限定重传次数 ... } else { // 如果超时发生在数据发送期间 // 这个函数负责判断重传是否超过阈值,返回真表示超过。后续会详细分析这个函数 if (retransmits_timed_out(sk, sysctl_tcp_retries1, 0, 0)) { /* Black hole detection */ tcp_mtu_probing(icsk, sk); // 如果开启tcp_mtu_probing(默认关闭)了,则执行PMTU dst_negative_advice(sk); // 更新路由缓存 } ... } -------------------------------- // 依然还是在tcp_write_timeout()中,retry_until一般是tcp_retries2 ... if (retransmits_timed_out(sk, retry_until, syn_set ? 0 : icsk->icsk_user_timeout, syn_set)) { /* Has it gone just too far? */ tcp_write_err(sk); // 调用tcp_done关闭TCP流 return 1; }
code2:
void sock_init_data(struct socket *sock, struct sock *sk) { skb_queue_head_init(&sk->sk_receive_queue); skb_queue_head_init(&sk->sk_write_queue); skb_queue_head_init(&sk->sk_error_queue); sk->sk_send_head = NULL; init_timer(&sk->sk_timer); sk->sk_allocation = GFP_KERNEL; sk->sk_rcvbuf = sysctl_rmem_default; sk->sk_sndbuf = sysctl_wmem_default; sk->sk_state = TCP_CLOSE; }
void tcp_init_sock(struct sock *sk) { struct inet_connection_sock *icsk = inet_csk(sk); sk->sk_state = TCP_CLOSE; sk->sk_write_space = sk_stream_write_space; sock_set_flag(sk, SOCK_USE_WRITE_QUEUE); icsk->icsk_sync_mss = tcp_sync_mss; sk->sk_sndbuf = sysctl_tcp_wmem[1]; sk->sk_rcvbuf = sysctl_tcp_rmem[1]; }
ext3:
case TCP_NODELAY: if (val) { /* TCP_NODELAY is weaker than TCP_CORK, so that * this option on corked socket is remembered, but * it is not activated until cork is cleared. * * However, when TCP_NODELAY is set we make * an explicit push, which overrides even TCP_CORK * for currently queued segments. */ tp->nonagle |= TCP_NAGLE_OFF|TCP_NAGLE_PUSH; tcp_push_pending_frames(sk); } else { tp->nonagle &= ~TCP_NAGLE_OFF; } break;
case TCP_CORK: /* When set indicates to always queue non-full frames. * Later the user clears this option and we transmit * any pending partial frames in the queue. This is * meant to be used alongside sendfile() to get properly * filled frames when the user (for example) must write * out headers with a write() call first and then use * sendfile to send out the data parts. * * TCP_CORK can be set together with TCP_NODELAY and it is * stronger than TCP_NODELAY. */ if (val) { tp->nonagle |= TCP_NAGLE_CORK; } else { tp->nonagle &= ~TCP_NAGLE_CORK; if (tp->nonagle&TCP_NAGLE_OFF) tp->nonagle |= TCP_NAGLE_PUSH; tcp_push_pending_frames(sk); } break;
/* Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一 个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。 Nagle算法的规则(可参考tcp_output.c文件里tcp_nagle_check函数注释): (1)如果包长度达到MSS,则允许发送; (2)如果该包含有FIN,则允许发送; (3)设置了TCP_NODELAY选项,则允许发送; (4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送; (5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。 Nagle算法只允许一个未被ACK的包存在于网络,它并不管包的大小,因此它事实上就是一个扩展的停-等协议,只不过它是基于包停-等的,而不 是基于字节停-等的。Nagle算法完全由TCP协议的ACK机制决定,这会带来一些问题,比如如果对端ACK回复很快的话,Nagle事实上不会拼接太多 的数据包,虽然避免了网络拥塞,网络总体的利用率依然很低。 TCP链接的过程中,默认开启Nagle算法,进行小包发送的优化。 2. TCP_NODELAY 选项 默认情况下,发送数据采用Negale 算法。这样虽然提高了网络吞吐量,但是实时性却降低了,在一些交互性很强的应用程序来说是不 允许的,使用TCP_NODELAY选项可以禁止Negale 算法。 此时,应用程序向内核递交的每个数据包都会立即发送出去。需要注意的是,虽然禁止了Negale 算法,但网络的传输仍然受到TCP确认延迟机制的影响。 3. TCP_CORK 选项 (tcp_nopush = on 会设置调用tcp_cork方法,配合sendfile 选项仅在使用sendfile的时候才开启) 所谓的CORK就是塞子的意思,形象地理解就是用CORK将连接塞住,使得数据先不发出去,等到拔去塞子后再发出去。设置该选项后,内核 会尽力把小数据包拼接成一个大的数据包(一个MTU)再发送出去,当然若一定时间后(一般为200ms,该值尚待确认),内核仍然没有组 合成一个MTU时也必须发送现有的数据(不可能让数据一直等待吧)。 然而,TCP_CORK的实现可能并不像你想象的那么完美,CORK并不会将连接完全塞住。内核其实并不知道应用层到底什么时候会发送第二批 数据用于和第一批数据拼接以达到MTU的大小,因此内核会给出一个时间限制,在该时间内没有拼接成一个大包(努力接近MTU)的话,内 核就会无条件发送。也就是说若应用层程序发送小包数据的间隔不够短时,TCP_CORK就没有一点作用,反而失去了数据的实时性(每个小 包数据都会延时一定时间再发送)。 4. Nagle算法与CORK算法区别 Nagle算法和CORK算法非常类似,但是它们的着眼点不一样,Nagle算法主要避免网络因为太多的小包(协议头的比例非常之大)而拥塞,而CORK 算法则是为了提高网络的利用率,使得总体上协议头占用的比例尽可能的小。如此看来这二者在避免发送小包上是一致的,在用户控制的层面上, Nagle算法完全不受用户socket的控制,你只能简单的设置TCP_NODELAY而禁用它,CORK算法同样也是通过设置或者清除TCP_CORK使能或者禁用之, 然而Nagle算法关心的是网络拥塞问题,只要所有的ACK回来则发包,而CORK算法却可以关心内容,在前后数据包发送间隔很短的前提下(很重要, 否则内核会帮你将分散的包发出),即使你是分散发送多个小数据包,你也可以通过使能CORK算法将这些内容拼接在一个包内,如果此时用Nagle 算法的话,则可能做不到这一点。 naggle(tcp_nodelay设置)算法,只要发送出去一个包,并且受到协议栈ACK应答,内核就会继续把缓冲区的数据发送出去。 core(tcp_core设置)算法,受到对方应答后,内核首先检查当前缓冲区中的包是否有1500,如果有则直接发送,如果受到应答的时候还没有1500,则 等待200ms,如果200ms内还没有1500字节,则发送 */ //参考http://m.blog.csdn.net/blog/c_cyoxi/8673645
现在的网卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到网卡中,通过硬件来执行。
- TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在 TCP/UDP 协议中直接发送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由网卡来完成 。
- GSO(Generic Segmentation Offload):在网卡不支持 TSO/UFO 时,将 TCP/UDP 包的分段,延迟到进入网卡前再执行。这样,不仅可以减少 CPU 的消耗,还可以在发生丢包时只重传分段后的包。
- LRO(Large Receive Offload):在接收 TCP 分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO 合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通用,同时支持 TCP 和 UDP。
- RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个 CPU 来处理接收到的网络包。
- VXLAN 卸载:也就是让网卡来完成 VXLAN 的组包功能。
对于网络接口本身,也有很多方法,可以优化网络的吞吐量。比如,
- 开启网络接口的多队列功能。这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行,从而提升网络的吞吐量。
- 增大网络接口的缓冲区大小,以及队列长度等,提升网络传输的吞吐量(注意,这可能导致延迟增大)。
- 使用 Traffic Control 工具,为不同网络流量配置
QoS。
应用层
应用层即我们使用的网络库,常见问题主要有如下
- 网络I/O模型:使用
epoll或者IOCP的方式是否有问题,超过C10K的单机并发数,可考虑改为dpdk或者xdp - 进程工作模型:采用的是主进程+多个worker子进程还是多进程监听相同端口。如果是第一种是否存在进程间通信的延时问题,是否存在不必要的广播,是否出现通信失败导致进程工作阻塞?如果是第二种是否存在请求负载均衡的处理问题?
- 使用长连接取代短连接,可以显著降低 TCP 建立连接的成本。在每秒请求次数较多时,这样做的效果非常明显。
- 使用内存等方式缓存不常变化的数据,可以降低网络 I/O 次数,同时加快应用程序的响应速度。
- 使用 Protocol Buffer 等序列化的方式,压缩网络 I/O 的数据量,可以提高应用程序的吞吐。
- 使用 DNS 缓存、预取、HTTPDNS 等方式,减少 DNS 解析的延迟,也可以提升网络 I/O 的整体速度
套接字
- 在套接字层中,主要优化套接字的缓冲区大小。
链路层
- TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在 TCP/UDP 协议中直接发送大包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分片(按照 MTU 分片)功能,由网卡来完成 。
- GSO(Generic Segmentation Offload):在网卡不支持 TSO/UFO 时,将 TCP/UDP 包的分段,延迟到进入网卡前再执行。这样,不仅可以减少 CPU 的消耗,还可以在发生丢包时只重传分段后的包。LRO(Large Receive Offload):在接收 TCP 分段包时,由网卡将其组装合并后,再交给上层网络处理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不一致,LRO 合并会导致网络包的校验错误。
- GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通用,同时支持 TCP 和 UDP。RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配网络接收进程,这样可以让多个 CPU 来处理接收到的网络包。
- VXLAN 卸载:也就是让网卡来完成 VXLAN 的组包功能。最后,对于网络接口本身,也有很多方法,可以优化网络的吞吐量。
在应用程序中,主要是优化 I/O 模型、工作模型以及应用层的网络协议;
在套接字层中,主要是优化套接字的缓冲区大小;
在传输层中,主要是优化 TCP 和 UDP 协议;
在网络层中,主要是优化路由、转发、分片以及 ICMP 协议;
最后,在链路层中,主要是优化网络包的收发、网络功能卸载以及网卡选项。