之前漏了个很重要的东西没说明,因为我使用得不多,但是又非常重要的家伙—元数据。
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据,主要是描述数据属性的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能
如果你进到了公司第一时间找相关负责人那业务元数据看看,有助于你日后的工作,如数据分析,SQL编写等等
元数据的管理最简单的可以使用一些文档记录下来,技术有能力或者时间就自己开发一套元数据管理系统,
或者使用第三方的元数据管理工具。
吐槽:
试想一下,你作为一个新人接手别人的工作,没有文档,程序没有注释,数据库中的表和字段也没有任何描述,你是不是会骂人了?
业务系统发生改变,删除了一个字段,需要数据仓库也做出相应调整的时候,
工程师如何知道改这个字段会对哪些程序产生影响?
源系统表的字段及其含义,源系统数据库的IP、接口人,数据仓库表的字段及其含义,
源表和目标表的对应关系,一个任务对应的源表和目标表,任务之间的依赖关系,
任务每次执行情况等等等等,这些元数据如果都能严格的管控起来,上面的问题肯定不会是问题了。。。
1.元数据说明
元数据分为技术元数据、业务元数、,元数据管理在数据建设起着举足轻重的作用,通常元数据存储在MYSQL数据库中。
1.1元数据记录了哪些信息?
1.数据的表结构:字段信息、分区信息、索引信息等;
2.数据的使用&权限:空间存储、读写记录、修改记录、权限归属、审核记录等其他信息;
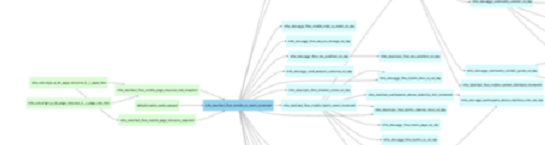
3.数据的血缘关系信息:血缘信息简单的说就是数据的上下游关系,数据从哪里来到哪里去?我们通过血缘关系,可以了解到建立起生产这些数据的任务之间的依赖关系,进而辅助调度系统的工作调度,或者用来判断一个失败或错误的任务可能对哪些下游数据造成影响等等;而在数据排查过程中也可以帮助我们定位问题。
4.数据的业务属性信息:记录这张表的业务用途,各个字段的具体统计口径、业务描述、历史变迁记录、变迁原因等。这部分数据多是我们手动填写,但却能大大提升数据使用过程中的便利性。
2.在数仓的体现如下:
(1)血缘管理
血缘管理可以追溯数据加工整体链路,解析表的来龙去脉,用于支撑各类场景,如:
-
支持上游变更对下游影响的分析与调整
-
监控各节点、各链路任务运行成本,效率
-
监控数据模型的依赖数量,确认哪些是重点模型
如下是某一个数据模型中的血缘图,上下游以不同颜色进行呈现依赖关系如下:
(2)数据知识管理
通过对技术、业务元数据进行清晰、详尽地描述,形成数据知识,给数据人员提供更好的使用向导。
Apache Atlas是Hadoop社区为解决Hadoop生态系统的元数据治理问题而产生的开源项目,它为Hadoop集群提供了包括 数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。