最近在写游戏服务器网络模块的时候,需要用到内存池。大量玩家通过tcp连接到服务器,通过大量的消息包与服务器进行交互。因此要给每个tcp分配收发两块缓冲区。那么这缓冲区多大呢?通常游戏操作的消息包都很小,大概几十字节。但是在玩家登录时或者卡牌游戏发战报(将整场战斗打完,生成一个消息包),包的大小可能达到30k或者更大,取决于游戏设定。这些缓冲区不可能使用glibc原始的new、delete来分配,这样可能会造成严重的内存碎片,并且效率也不高。
于是我们要使用内存池。并且是等长内存池,即每次分配的内存只能是基数的整数倍。如把内存池基数设置为1024,则每次分配的内存只能是1024,2048,3072,4096...这样利用率高,易管理。boost提供这种内存池,下面我们来看下boost如何实现内存池。(下面的解说需要你先了解一下boost池的源码才能看明白)
boost的池在boost/pool/pool.hpp中实现,我们先把它简化一下:
class PODptr { char * ptr; unsigned int sz; } struct pool:public simple_segregated_storage { PODptr<size_type> list; }
pool只包括一个PODptr的成员list,它其实是一个巧妙的链表。PODptr则是指向一块用new分配出来的原始内存。
假如我们要分配一块等长内存,则要调用ordered_malloc。我们先假设是第一次调用,还不存在缓存。
void *pool:ordered_malloc(n) { char *block = malloc() simple_segregated_storage.add_ordered_block() const PODptr node(); list.add_node(node); return ptr; }
boost先调用malloc来分配一块大内存block,创建了一个PODptr对象node来管理这块内存。这块内存被boost分成下图所示:

node的ptr指向这块内存的起始地址,sz则表示这块内存的大小。在这块内存的末尾,boost预留了一个指针及一个int的位置,这个指针指向下一块block的起始地址,int则存着下一块block的大小。每从系统获取一块block,boost就利用next_ptr把它链接表list里,形成一个链表。
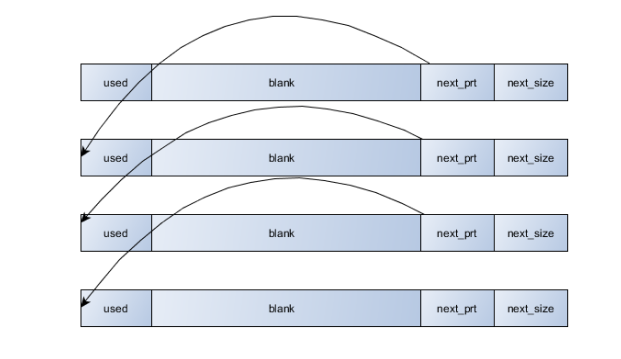
而block里前面这一块空白的内存blank,则通过add_ordered_block交给pool的基类simple_segregated_storage来管理。
struct simple_segregated_storage { void *first }
simple_segregated_storage是管理空白可用的内存块的,它把空白的内存分成等长的小块,然后用链表将它们连接起来,first就是表头。那么,只有一个void指针如何实现一个链表呢?因为simple_segregated_storage管理的内存都是空白的,所以你可以随意往里面写东西。于是simple_segregated_storage把下一块内存写在空白的内存块上:

释放内存时调用ordered_free,原理就是把释放的内存还给simple_segregated_storage,放到链表就好。
于是,boost内存池的原理可以总结为pool先从系统获取一大块内存,simple_segregated_storage把它分成几小块放到链表上,用到时就从链表上取。用没了又重系统取...
上面说了如何取一块内存,如果我要分配4块大小的内存,boost又是如何处理呢?simple_segregated_storage将一大块内存分成小块时,这些小块内存的地址是连续的。boost会遍历已有的链表,将这些小块插入到合适的位置,保证整条链表节点的地址都是由小到大的。当你要分配多块内存时,boost会遍历链表,对比每个节点和下一个节点的地址是否连续,如果找到合适的大小的连续内存块,则将这几块分配出去。当然,释放的时候也要遍历链表,插入到对应的位置。
我们可以看到,boost等长内存池的实现在分配、释放时都要遍历链表,显示不是最优的。于是我决定重写一个。我重写的理由很简单:boost的库是一个通用的库,但对于我的场景,却不是最优的。根据我的场景,我假定我的缓冲区大小基数为8192,则我需要分配的内存为8k,16k,32k,64k。再大就不处理了,游戏逻辑中64k以上的通信比较罕见,可以当异常处理了。假如我们有5w链接,缓冲区平均大小为16k,则每个链接为32k,这个消耗对于现在的服务器还可能忍受。于是,我把内存池简化一下:以n(1,2,3,4)为下标生成一个数组,每个数组元素是一块链表,对应8k,16k,32k,64k。每次分配直接从链表取,释放时放回对应的链表,无需遍历。


#ifndef __ORDERED_POOL_H__ #define __ORDERED_POOL_H__ /* 等长内存池,参考了boost内存池(boolst/pool/pool.hpp).分配的内存只能是ordered_size * 的n倍。每一个n都形成一个空闲链表,利用率比boost低。 * 1.分配出去的内存不再受池的管理 * 2.所有内存在池销毁时会释放(包括未归还的) * 3.没有约束内存对齐。因此用的是系统默认对齐,在linux 32/64bit应该是OK的 * 4.最小内存块不能小于一个指针长度(4/8 bytes) */ #include <cassert> #include <cstring> typedef int int32; typedef unsigned int uint32; #define array_resize(type,base,cur,cnt,init) if ( (cnt) > (cur) ) { uint32 size = cur > 0 ? cur : 16; while ( size < (uint32)cnt ) { size *= 2; } type *tmp = new type[size]; init( tmp,sizeof(type)*size ); if ( cur > 0) memcpy( tmp,base,sizeof(type)*cur ); delete []base; base = tmp; cur = size; } #define array_zero(base,size) memset ((void *)(base), 0, size) template<uint32 ordered_size,uint32 chunk_size = 512> class ordered_pool { public: ordered_pool(); ~ordered_pool(); char *ordered_malloc( uint32 n = 1 ); void ordered_free ( char * const ptr,uint32 n ); private: typedef void * NODE; NODE *anpts; /* 空闲内存块链表数组,倍数n为下标 */ uint32 anptmax; void *block_list; /* 从系统分配的内存块链表 */ /* 一块内存的指针是ptr,这块内存的前几个字节储存了下一块内存的指针地址 * 即ptr可以看作是指针的指针 * nextof返回这地址的引用 */ inline void * & nextof( void * const ptr ) { return *(static_cast<void **>(ptr)); } /* 把从系统获取的内存分成小块存到链表中 * 这些内存块都是空的,故在首部创建一个指针,存放指向下一块空闲内存的地址 */ inline void *segregate( void * const ptr,uint32 partition_sz, uint32 npartition,uint32 n ) { char *last = static_cast<char *>(ptr); for ( uint32 i = 1;i < npartition;i ++ ) { char *next = last + partition_sz; nextof( last ) = next; last = next; } nextof( last ) = anpts[n]; return anpts[n] = ptr; } }; template<uint32 ordered_size,uint32 chunk_size> ordered_pool<ordered_size,chunk_size>::ordered_pool() : anpts(NULL),anptmax(0),block_list(NULL) { assert( ("ordered size less then sizeof(void *)",ordered_size >= sizeof(void *)) ); } template<uint32 ordered_size,uint32 chunk_size> ordered_pool<ordered_size,chunk_size>::~ordered_pool() { if ( anpts ) delete []anpts; anpts = NULL; anptmax = 0; while ( block_list ) { char *_ptr = static_cast<char *>(block_list); block_list = nextof( block_list ); delete []_ptr; } } /* 分配N*ordered_size内存 */ template<uint32 ordered_size,uint32 chunk_size> char *ordered_pool<ordered_size,chunk_size>::ordered_malloc( uint32 n ) { assert( ("ordered_malloc n <= 0",n > 0) ); array_resize( NODE,anpts,anptmax,n+1,array_zero ); void *ptr = anpts[n]; if ( ptr ) { anpts[n] = nextof( ptr ); return static_cast<char *>(ptr); } /* 每次固定申请chunk_size块大小为(n*ordered_size)内存 * 不用指数增长方式因为内存分配过大可能会失败 */ uint32 partition_sz = n*ordered_size; uint32 block_size = sizeof(void *) + chunk_size*partition_sz; char *block = new char[block_size]; /* 分配出来的内存,预留一个指针的位置在首部,用作链表将所有从系统获取的 * 内存串起来 */ nextof( block ) = block_list; block_list = block; /* 第一块直接分配出去,其他的分成小块存到anpts对应的链接中 */ segregate( block + sizeof(void *) + partition_sz,partition_sz, chunk_size - 1,n ); return block + sizeof(void *); } template<uint32 ordered_size,uint32 chunk_size> void ordered_pool<ordered_size,chunk_size>::ordered_free( char * const ptr,uint32 n ) { assert( ("illegal ordered free",anptmax >= n && ptr) ); nextof( ptr ) = anpts[n]; anpts[n] = ptr; } #endif /* __ORDERED_POOL_H__ */
这样,一个简单的内存池就OK了,利用率降低了,但速度上去了。下面我们来与boost(1.59)对比一下:
#include <iostream> #include <cstdio> #include <ctime> #include <cstdlib> #include "ordered_pool.h" //#include <boost/pool/singleton_pool.hpp> #define CHUNK_SIZE 8192 void memory_fail() { std::cerr << "no memory anymore !!!" << std::endl; exit( 1 ); } int main() { std::set_new_handler( memory_fail ); const int max = 10000; ordered_pool<CHUNK_SIZE> pool; char *(list[4][max]) = {0}; clock_t start = clock(); for ( int i = 0;i < max;i ++ ) { list[0][i] = pool.ordered_malloc( 1 ); list[1][i] = pool.ordered_malloc( 2 ); //list[3][i] = pool.ordered_malloc( 4 ); } for ( int i = 0;i < max;i ++ ) { pool.ordered_free( list[0][i],1 ); pool.ordered_free( list[1][i],2 ); //pool.ordered_free( list[3][i],4 ); } std::cout << "my pool run:" << float(clock() - start)/CLOCKS_PER_SEC << std::endl; /* //typedef boost::singleton_pool<char, CHUNK_SIZE> Alloc; boost::pool<> Alloc(CHUNK_SIZE); clock_t _start = clock(); for ( int i = 0;i < 10000;i ++ ) { list[0][i] = (char*)Alloc.ordered_malloc( 1 ); list[1][i] = (char*)Alloc.ordered_malloc( 2 ); //list[3][i] = (char*)Alloc::ordered_malloc( 4 ); } for ( int i = 0;i < 10000;i ++ ) { Alloc.ordered_free( list[0][i],1 ); Alloc.ordered_free( list[1][i],2 ); //Alloc::ordered_free( list[3][i],4 ); } std::cout << "boost run:" << float(clock() - _start)/CLOCKS_PER_SEC << std::endl; */ return 0; }
因为虚拟机只有2G内存,加上ubuntu占用了部分内存,我通过注释代码来分别测试效果。
xzc@xzc-VirtualBox:~/code/pool$ ./main my pool run:0.035874 xzc@xzc-VirtualBox:~/code/pool$ ./main my pool run:0.035968 xzc@xzc-VirtualBox:~/code/pool$ ./main my pool run:0.027455 xzc@xzc-VirtualBox:~/code/pool$ ./main my pool run:0.03688 boost run:8.42273 xzc@xzc-VirtualBox:~/code/pool$ ./main boost run:8.50574 xzc@xzc-VirtualBox:~/code/pool$ ./main boost run:8.48862 std run:0.004238 xzc@xzc-VirtualBox:~/code/pool$ ./main std run:0.003537 xzc@xzc-VirtualBox:~/code/pool$ ./main std run:0.00356 xzc@xzc-VirtualBox:~/code/pool$ ./main std run:0.003925
测试结果让我大跌眼镜。my pool run是我写的库运行时间,boost run表示boost库的时间,std run则表示glibc new delete的运行时间。可以看到glibc是最优的,其次是我写的库,而boost完全不在一个级别上。考虑到glibc解决不了内存碎片的问题,而且内存池在第一次分配上会吃亏(得先调用一次new从系统获取内存),于是在第一次释放后,再测试一次,这次没有测试glibc
my pool run:0.000949 xzc@xzc-VirtualBox:~/code/pool$ ./main my pool run:0.001046 xzc@xzc-VirtualBox:~/code/pool$ ./main my pool run:0.001133 xzc@xzc-VirtualBox:~/code/pool$ ./main my pool run:0.001005 xzc@xzc-VirtualBox:~/code/pool$ ./main my pool run:0.001074 xzc@xzc-VirtualBox:~/code/pool$ ./main boost run:2.14777 xzc@xzc-VirtualBox:~/code/pool$ ./main boost run:2.15328 xzc@xzc-VirtualBox:~/code/pool$ ./main boost run:2.15201 xzc@xzc-VirtualBox:~/code/pool$ ./main boost run:2.15536
可以看到这次内存池的速度加快了不少,我自己的库已经超过glibc了,但boost的速度依然惨不忍睹。我不得不怀疑是不是我不会用boost。于是在网上(http://tech.it168.com/a2011/0726/1223/000001223399_all.shtml,在cnblogs、oschina、csdn上都没找到更好的测试代码)找了些代码:
#include <iostream> #include <ctime> #include <boost/pool/pool.hpp> #include <boost/pool/object_pool.hpp> using namespace std; using namespace boost; const int MAXLENGTH = 100000; int main ( ) { boost::pool<> p(sizeof(int)); int* vec1[MAXLENGTH]; int* vec2[MAXLENGTH]; clock_t clock_begin = clock(); for (int i = 0; i < MAXLENGTH; ++i) vec1[i] = static_cast<int*>(p.malloc()); for (int i = 0; i < MAXLENGTH; ++i) p.free(vec1[i]); clock_t clock_end = clock(); cout << "程序运行了 " << clock_end-clock_begin << " 个系统时钟" << endl; clock_begin = clock(); for (int i = 0; i < MAXLENGTH; ++i) vec2[i] = new int(); for (int i = 0; i < MAXLENGTH; ++i) delete vec2[i]; clock_end = clock(); cout << "程序运行了 " << clock_end-clock_begin << " 个系统时钟" << endl; return 0; }
原作者的测试环境为测试环境:VS2008,WindowXP SP2,Pentium 4 CPU双核,1.5GB内存,连续申请和连续释放10万块内存。测试结果:
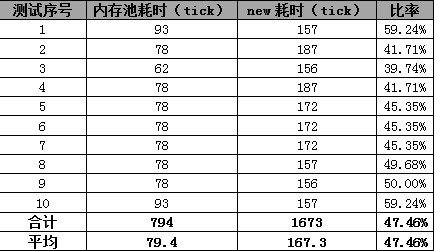
我把这份代码放到我的虚拟机上测试:
g++ -o test test.cpp -lboost_system xzc@xzc-VirtualBox:~/code/pool$ ./test 程序运行了 12781 个系统时钟 程序运行了 7431 个系统时钟 xzc@xzc-VirtualBox:~/code/pool$ ./test 程序运行了 14078 个系统时钟 程序运行了 10028 个系统时钟 xzc@xzc-VirtualBox:~/code/pool$ ./test 程序运行了 11624 个系统时钟 程序运行了 7787 个系统时钟 xzc@xzc-VirtualBox:~/code/pool$ ./test 程序运行了 13270 个系统时钟 程序运行了 9534 个系统时钟 xzc@xzc-VirtualBox:~/code/pool$ ./test 程序运行了 14641 个系统时钟 程序运行了 12354 个系统时钟 xzc@xzc-VirtualBox:~/code/pool$ ./test 程序运行了 14127 个系统时钟 程序运行了 11137 个系统时钟 xzc@xzc-VirtualBox:~/code/pool$ ./test 程序运行了 10371 个系统时钟 程序运行了 6878 个系统时钟
显然boost比glibc还是差得远,可能是glibc和windows的内存分配算法问题。
到此,内存池的测试告一段落。只是boost的性能为何如此不济,实在令我不解。