Protocol Buffers是Google跨语言、跨平台的通用序列化库。FlatBuffers同样出自Google,而且也跨语言跨平台,但更强调效率,专门为游戏开发打造。在游戏界混了几年,各种各样的序列化协议都见过,MUD的字符串、Json、二进制、Protocol Buffers,各有各的优缺点。
Protocol Buffers采用的是单个字段压缩到数组的方式。例如:
message CPing
{
int32 x = 1;
int32 y = 2;
int32 z = 3;
int32 way = 4;
}
则字段x的索引为1,y的索引为2,依此类推,最终经过Protocol Buffers把索引、数据都压缩后,在内存中大概是这样排列的:

FlatBuffers则采用内存映射的方式,例如:
table CPing
{
x:int;
y:string;
}
参考C结构体在内存中的结构模型,像int这种内存不变的,称为POD类型,无法预先知道长度的(比如字符串),称为指针类型。FlatBuffers直接把内存中结构体类型直接搬到了序列化内存中。header总是在最前端,记录了各个成员的位置。各个成员的位置如果是POD类型,则记录数据,如果是指针类型,则记录数据位置。然后通过严格的内存对齐参数,用编译器实现跨语言、跨平台。大概是这样:
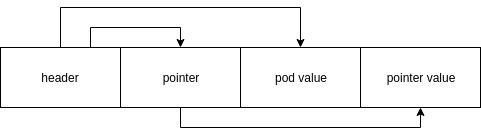
Protocol Buffers和FlatBuffers具体的序列化、反序列化还有很多细节,比如压缩算法、内存如何对齐,这里难以详细说明,有兴趣可以自己去查资料。
我自己业余实现了一个服务器框架,以C++为底层,Lua作为上层逻辑脚本。为了提高开发效率,所有消息到达脚本时都会自动序列化为Lua的table,不需要开发人员去解析数据包。例如:
message CPing
{
int32 x = 1;
int32 y = 2;
int32 z = 3;
int32 way = 4;
}
到达脚本时,就会是一个table,如:
{ x = 999, y = 123, z = 777, way = 0, }
所使用的库为:
Protocol Buffers:https://github.com/cloudwu/pbc
Flatbuffers:https://github.com/changnet/lua_flatbuffers
现在为了测试打包、解包效率,设计了这么一个流程:
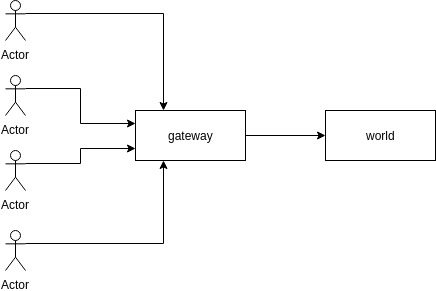
玩家actor的数据包先经过网关gateway,再由网关转发给游戏世界world。然后world会返回数据给gateway,再转发给actor。开启4个进程,每个进程登录2500个玩家,每个玩家1000个数据包,每秒发送8个,所以最快是1000 / 8 = 125秒。系统为ubuntu 14.04,Docker版本 17.03.1-ce, build c6d412e ,程序编译参数为-g0 -O2,所有进程运行在同一Docker中,机器配置为hp probook 4446(cpu为A8-4500m):
CPU MHz: 1400.000 BogoMIPS: 3792.91 Virtualization: AMD-V L1d cache: 16K L1i cache: 64K L2 cache: 2048K NUMA node0 CPU(s): 0-3
数据包为:
// 玩家发包
message CPing
{
int32 x = 1;
int32 y = 2;
int32 z = 3;
int32 way = 4;
}
// 服务器回包
message SPing
{
int32 time = 1;
}
Protocol Buffers的成绩为:
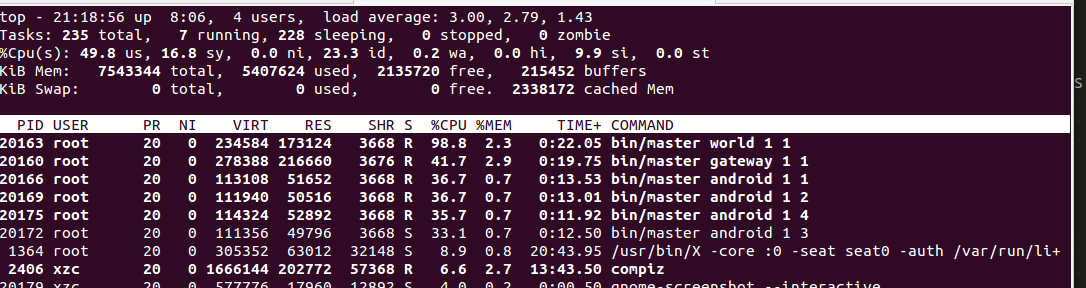
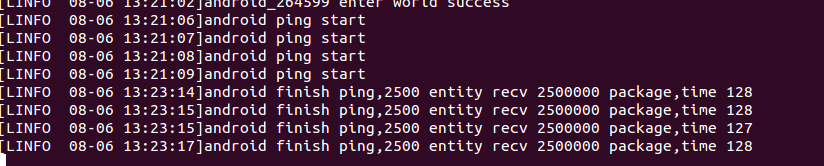
FlatBuffers的成绩为:
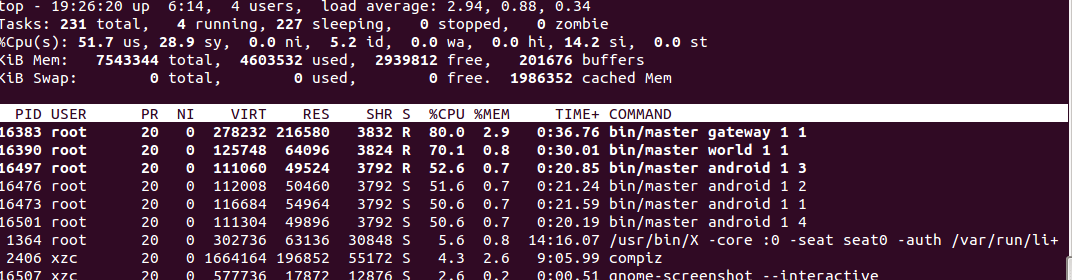

可以看到,两个库的效率相差无几(其实因为发的数据包太简单,完全看不出来),但是Protocol Buffer的world进程使用的cpu较高,而gateway较低,说明打包消耗了更多的cpu和时间,但是转发时流量小,IO更低。而FlatBuffers则反过来了。
上面测试的例子比较简单,都没有数组和字符串,在发送的数据加上数组和字符串:
message CPing
{
int32 x = 1;
int32 y = 2;
int32 z = 3;
int32 way = 4;
repeated int32 target = 5;
string say = 6;
}
发送的时候,数组固定为:{ 1,2,3,4,5,6,7,8,9 }而字符串固定为:"android ping test android ping test android ping test android ping test android ping test"。同时玩家的数量减为5000,进程改为个,依然是每个进程2500个玩家。
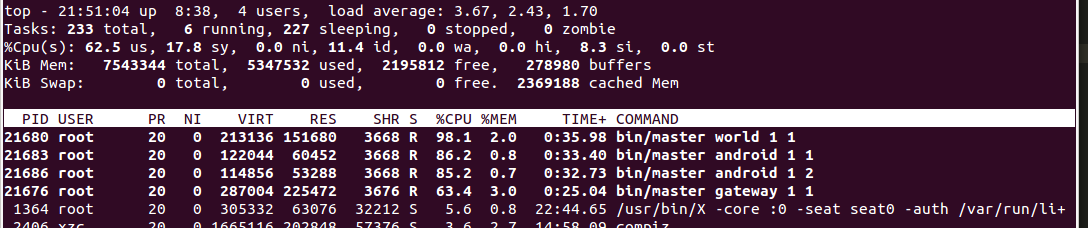
Protocol Buffers成绩:

FlatBuffers成绩为:
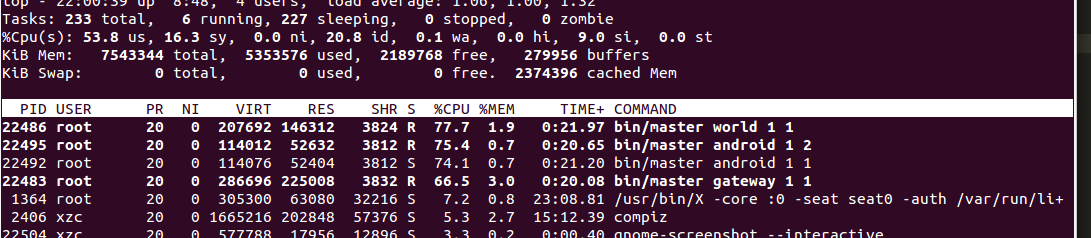

可以看到,加上数组和字符串后,FlatBuffers消耗的cpu资源远小于ProtocolBuffers,但是效率上的差距因为测试的方法不当则看不出来。
看到这里,大家可能很不理解我测试的方式,cpu基本没有跑满过。首先,我没办法让cpu刚好跑满,因为玩家那个进程是采用定时发包的方式来模拟玩家操作而不是echo方式(收到回包后再发包),所以多个玩家进程怼一个服务器进程,只要gateway和world进程有一个吃不消,就会造成数据包堆积。其次,我做这个测试是为了证明这两个库集成到我的框架中后能否达到我期望的效率。再着,这个测试中Lua的gc消耗可能是影响最大的一个因素。所以,这里只是一个参考,如果你要单纯测试这两个库的效率,可以直接测试那两个库(网上已经有不少结果了)。
FlatBuffers的效率要高一些,而Protocol Buffers的流量要小一些,而且Protocol Buffers的使用更加广泛、成熟。项目中使用哪个,就要看个人取舍。其实,我最早写了一个二进制序列化的库,使用Json作为schema文件,也能达到自动打包、解包的效果。但是不能实现版本向后兼容,也不能实现字段冗余,不过效率比这两个都要高。后来我嫌弃自己代码写得烂,就从框架分离出去了,等有时间再整理成一个独立的库,放在https://github.com/changnet/lua_stream。
测试框架代码在https://github.com/changnet/MServer,是一个半成品,一直在忙其他的,没空完善。