1、报错:“db_lmdb.hpp:14] Check failed:mdb_status ==0(112 vs.0)磁盘空间不足。”
这问题是由于lmdb在windows下无法使用lmdb的库,所以要改成leveldb。
但是要注意:由于backend默认的是lmdb,所以你每一次用到生成的图片leveldb数据的时候,都要把“--backend=leveldb”带上。如转换图片格式时:
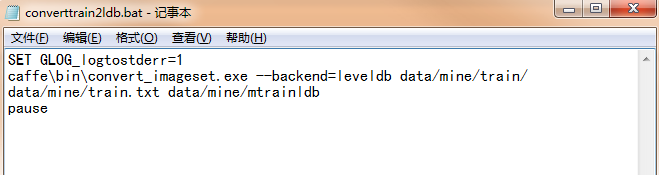
又如计算图像的均值时:
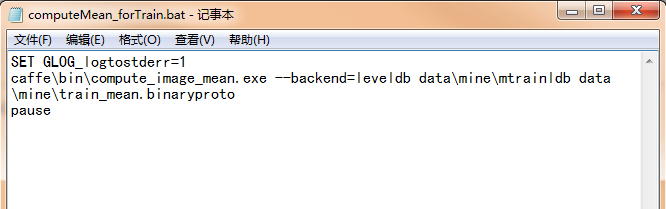
还有在.prototxt中
data_param { source: "./mysample_val_leveldb" batch_size: 100 backend: LEVELDB //这个也要改掉的,原来是LMDB }
2、caffe下使用“bvlc_reference_caffenet”模型进行训练时,出现了“Check failed:data_”
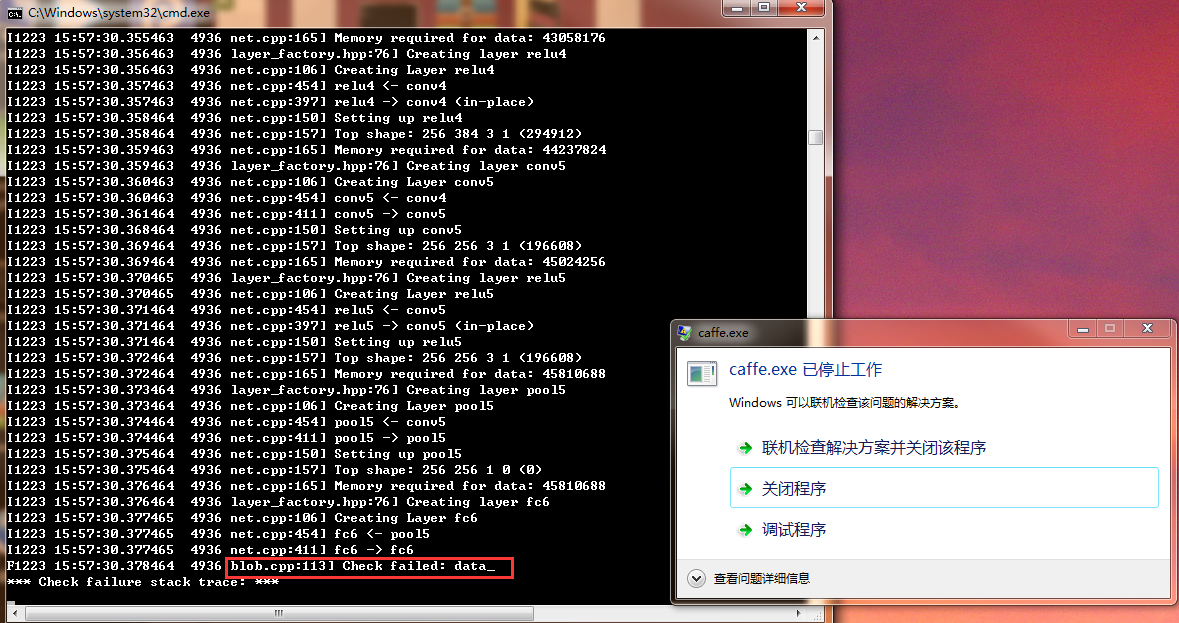
这个问题是由于训练样本的图像尺寸太小了,以至于到pool5池化层的时候输入的尺寸已经小于kernel的大小了,进而下一步输入编程了0x0,因此会报错。
解决的方法是要么在归一化图像尺寸时足够大(小于64*64好像就不行了),要么换用另一种模型(如果图像本身就小,放大图像会丢失图像特征,此时可尝试使用Cifar10模型)
3、caffe训练时遇到loss一直居高不下时:
http://blog.sina.com.cn/s/blog_141f234870102w941.html
我利用caffe训练一个基于AlexNet的三分类分类器,将train_val.prototxt的全连接输出层的输出类别数目改为3,训练一直不收敛,loss很高;当把输出改成4或1000(>3)的时候,网络可以收敛。也就是caffenet结构的输出层的类别数一定要大于我训练集的类别数才可以收敛!后来查了半天才发现原因,让我泪奔。。。
原来我把图像类型的label设置成1,2,3,改成0,1,2后,最后全连接层的输出改为3就OK了。
待更新...!