1 n-gram模型与auto complete
n-gram模型是假设文本中一个词出现的概率只与它前面的N-1个词相关。auto complete的原理就是,根据用户输入的词,将后续出现概率较大的词组显示出来。因此我们可以基于n-gram模型来对用户的输入作预测。
我们的实现方法是:首先用mapreduce在offline对语料库中的数据进行n-gram建模,存到数据库中。然后用户在输入的时候向数据库中查询,获取之后出现的概率较大的词,通过前端php脚本刷新实时显示在界面上。如下所示:
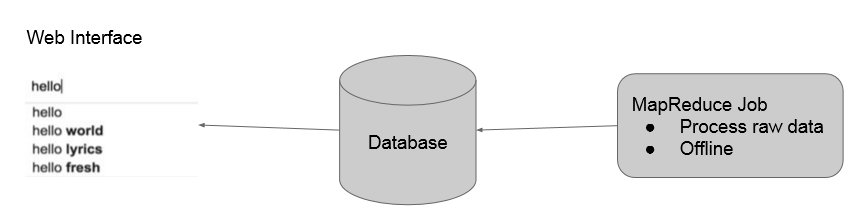
2 mapReduce流程
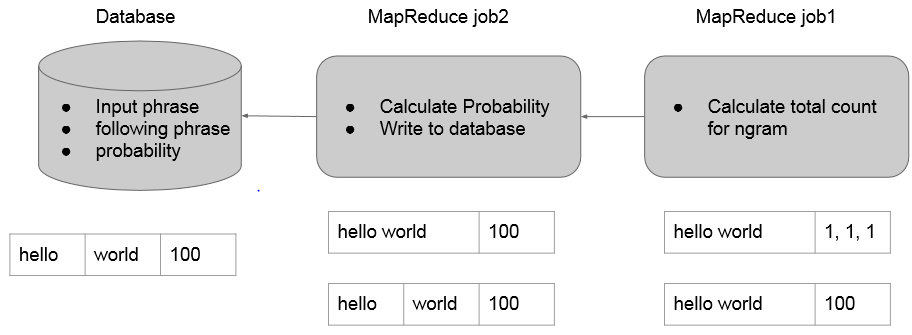
2.1 MR1
mapper负责按句读入语料库中的数据,分别作2~Ngram的切分(1-gram在这里没用),发送给reducer。
reducer则统计所有N-gram出现的次数。(这里就是一个wordcount)
2.2 MR2
mapper负责读入之前生成的N-gram及次数,将最后一个单词切分出来,以前面N-1个单词为key向reducer发送。
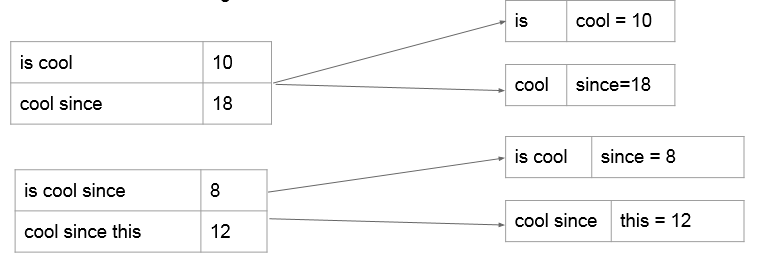
reducer里面得到的就是N-gram概率模型,即已知前N-1个词组成的phrase,最后一个词出现的所有可能及其概率。这里我们不用计算概率,仍然沿用词频能达到相同的效果,因为auto complete关注的是概率之间的相对大小而不是概率值本身。这里我们选择出现概率最大的topk个词来存入数据库,可以用treemap或者priorityQueue来做。

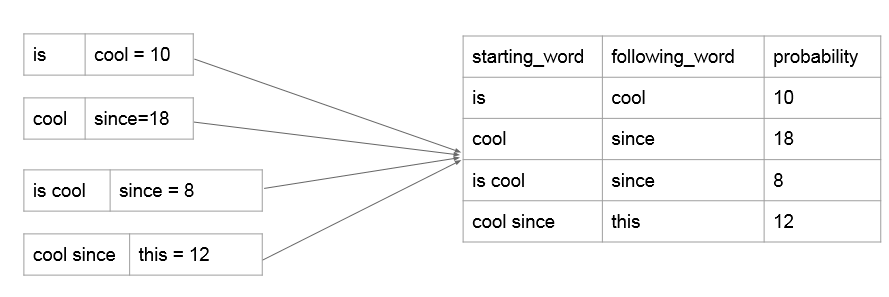
(注:这里的starting_word是1~n-1个词,following_word只能是一个词,因为这样才符合我们N-gram概率模型的意义。)
2.3 如何预测后面n个单词
数据库中的n-gram模型:

如上所述,我们看出使用n-gram模型只能与预测下一个单词。为了预测结果的多样性,如果我们要预测之后的n个单词怎么做?

使用sql语句,查询的时候查询匹配"input%"的所有starting_phrase,就可以实现。
3 代码
NGramLibraryBuilder.java


1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.LongWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.Mapper.Context; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 16 17 public class NGramLibraryBuilder { 18 public static class NGramMapper extends Mapper<LongWritable, Text, Text, IntWritable> { 19 20 int noGram; 21 @Override 22 public void setup(Context context) { 23 Configuration conf = context.getConfiguration(); 24 noGram = conf.getInt("noGram", 5); 25 } 26 27 // map method 28 @Override 29 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 30 31 String line = value.toString(); 32 33 line = line.trim().toLowerCase(); 34 line = line.replaceAll("[^a-z]", " "); 35 36 String[] words = line.split("\s+"); //split by ' ', ' '...ect 37 38 if(words.length<2) { 39 return; 40 } 41 42 //I love big data 43 StringBuilder sb; 44 for(int i = 0; i < words.length-1; i++) { 45 sb = new StringBuilder(); 46 sb.append(words[i]); 47 for(int j=1; i+j<words.length && j<noGram; j++) { 48 sb.append(" "); 49 sb.append(words[i+j]); 50 context.write(new Text(sb.toString().trim()), new IntWritable(1)); 51 } 52 } 53 } 54 } 55 56 public static class NGramReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 57 // reduce method 58 @Override 59 public void reduce(Text key, Iterable<IntWritable> values, Context context) 60 throws IOException, InterruptedException { 61 int sum = 0; 62 for(IntWritable value: values) { 63 sum += value.get(); 64 } 65 context.write(key, new IntWritable(sum)); 66 } 67 } 68 69 }
LanguageModel.java
1 import java.io.IOException; 2 import java.util.ArrayList; 3 import java.util.Collections; 4 import java.util.Iterator; 5 import java.util.List; 6 import java.util.Set; 7 import java.util.TreeMap; 8 9 import org.apache.hadoop.conf.Configuration; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.LongWritable; 12 import org.apache.hadoop.io.NullWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.Mapper; 16 import org.apache.hadoop.mapreduce.Reducer; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 19 public class LanguageModel { 20 public static class Map extends Mapper<LongWritable, Text, Text, Text> { 21 22 int threashold; 23 // get the threashold parameter from the configuration 24 @Override 25 public void setup(Context context) { 26 Configuration conf = context.getConfiguration(); 27 threashold = conf.getInt("threashold", 20); 28 } 29 30 31 @Override 32 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 33 if((value == null) || (value.toString().trim()).length() == 0) { 34 return; 35 } 36 //this is cool 20 37 String line = value.toString().trim(); 38 39 String[] wordsPlusCount = line.split(" "); 40 if(wordsPlusCount.length < 2) { 41 return; 42 } 43 44 String[] words = wordsPlusCount[0].split("\s+"); 45 int count = Integer.valueOf(wordsPlusCount[1]); 46 47 if(count < threashold) { 48 return; 49 } 50 51 //this is --> cool = 20 52 StringBuilder sb = new StringBuilder(); 53 for(int i = 0; i < words.length-1; i++) { 54 sb.append(words[i]).append(" "); 55 } 56 String outputKey = sb.toString().trim(); 57 String outputValue = words[words.length - 1]; 58 59 if(!((outputKey == null) || (outputKey.length() <1))) { 60 context.write(new Text(outputKey), new Text(outputValue + "=" + count)); 61 } 62 } 63 } 64 65 public static class Reduce extends Reducer<Text, Text, DBOutputWritable, NullWritable> { 66 67 int n; 68 // get the n parameter from the configuration 69 @Override 70 public void setup(Context context) { 71 Configuration conf = context.getConfiguration(); 72 n = conf.getInt("n", 5); 73 } 74 75 @Override 76 public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { 77 78 //this is, <girl = 50, boy = 60> 79 TreeMap<Integer, List<String>> tm = new TreeMap<Integer, List<String>>(Collections.reverseOrder()); 80 for(Text val: values) { 81 String curValue = val.toString().trim(); 82 String word = curValue.split("=")[0].trim(); 83 int count = Integer.parseInt(curValue.split("=")[1].trim()); 84 if(tm.containsKey(count)) { 85 tm.get(count).add(word); 86 } 87 else { 88 List<String> list = new ArrayList<String>(); 89 list.add(word); 90 tm.put(count, list); 91 } 92 } 93 //<50, <girl, bird>> <60, <boy...>> 94 Iterator<Integer> iter = tm.keySet().iterator(); 95 for(int j=0; iter.hasNext() && j<n; j++) { 96 int keyCount = iter.next(); 97 List<String> words = tm.get(keyCount); 98 for(String curWord: words) { 99 context.write(new DBOutputWritable(key.toString(), curWord, keyCount),NullWritable.get()); 100 j++; 101 } 102 } 103 } 104 } 105 }
DBOutputWritable.java
1 import java.sql.PreparedStatement; 2 import java.sql.ResultSet; 3 import java.sql.SQLException; 4 5 import org.apache.hadoop.mapreduce.lib.db.DBWritable; 6 7 public class DBOutputWritable implements DBWritable{ 8 9 private String starting_phrase; 10 private String following_word; 11 private int count; 12 13 public DBOutputWritable(String starting_prhase, String following_word, int count) { 14 this.starting_phrase = starting_prhase; 15 this.following_word = following_word; 16 this.count= count; 17 } 18 19 public void readFields(ResultSet arg0) throws SQLException { 20 this.starting_phrase = arg0.getString(1); 21 this.following_word = arg0.getString(2); 22 this.count = arg0.getInt(3); 23 24 } 25 26 public void write(PreparedStatement arg0) throws SQLException { 27 arg0.setString(1, starting_phrase); 28 arg0.setString(2, following_word); 29 arg0.setInt(3, count); 30 31 } 32 33 }
Driver.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.IntWritable; 6 import org.apache.hadoop.io.NullWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.lib.db.DBConfiguration; 10 import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat; 11 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 12 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 13 14 15 public class Driver { 16 17 public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException { 18 //job1 19 Configuration conf1 = new Configuration(); 20 conf1.set("textinputformat.record.delimiter", "."); 21 conf1.set("noGram", args[2]); 22 23 Job job1 = Job.getInstance(); 24 job1.setJobName("NGram"); 25 job1.setJarByClass(Driver.class); 26 27 job1.setMapperClass(NGramLibraryBuilder.NGramMapper.class); 28 job1.setReducerClass(NGramLibraryBuilder.NGramReducer.class); 29 30 job1.setOutputKeyClass(Text.class); 31 job1.setOutputValueClass(IntWritable.class); 32 33 job1.setInputFormatClass(TextInputFormat.class); 34 job1.setOutputFormatClass(TextOutputFormat.class); 35 36 TextInputFormat.setInputPaths(job1, new Path(args[0])); 37 TextOutputFormat.setOutputPath(job1, new Path(args[1])); 38 job1.waitForCompletion(true); 39 40 //how to connect two jobs? 41 // last output is second input 42 43 //2nd job 44 Configuration conf2 = new Configuration(); 45 conf2.set("threashold", args[3]); 46 conf2.set("n", args[4]); 47 48 DBConfiguration.configureDB(conf2, 49 "com.mysql.jdbc.Driver", 50 "jdbc:mysql://ip_address:port/test", 51 "root", 52 "password"); 53 54 Job job2 = Job.getInstance(conf2); 55 job2.setJobName("Model"); 56 job2.setJarByClass(Driver.class); 57 58 job2.addArchiveToClassPath(new Path("path_to_ur_connector")); 59 job2.setMapOutputKeyClass(Text.class); 60 job2.setMapOutputValueClass(Text.class); 61 job2.setOutputKeyClass(DBOutputWritable.class); 62 job2.setOutputValueClass(NullWritable.class); 63 64 job2.setMapperClass(LanguageModel.Map.class); 65 job2.setReducerClass(LanguageModel.Reduce.class); 66 67 job2.setInputFormatClass(TextInputFormat.class); 68 job2.setOutputFormatClass(DBOutputFormat.class); 69 70 DBOutputFormat.setOutput(job2, "output", 71 new String[] {"starting_phrase", "following_word", "count"}); 72 73 TextInputFormat.setInputPaths(job2, args[1]); 74 job2.waitForCompletion(true); 75 } 76 77 }