1 Hoeffding不等式
假设有一个罐子装满了橙色和绿色的球,为了估计罐子中橙色和绿色的比例,我们随机抓一把球,称为样本:

其中,设罐子中橙色球的比例为μ,样本中橙色球比例为v,样本的大小为N,我们对真实分布μ和样本分布v的差异容忍度为ε,则有下面的不等式成立:
![]()
也就是存在一个概率上界,只要我们保证样本容量N很大,就能使得“μ和v的差异大”这件事的概率是很小的。
2 对于一个假设函数h的情况
如果我们的假设函数h已经确定了,那么我们可以这样把我们的问题对应到罐子模型:每个球表示一个输入x,橙色表示h与真实的函数f预测的值不相同,绿色表示相同,即:

那么罐子中的所有球就是所有可能的输入x,而抓的一把球表示我们的训练集(注意!这里其实是做了一个假设:我们的训练集和测试集都由同一个未知的概率分布P来产生,也就是来源于同一个罐子),那么橙色球占的比例μ就表示我们的假设函数h在真正的输入空间中的预测错误率Eout(我们最后想要降低的),v就表示我们在训练集中的预测错误率Ein(我们的算法能最小化的),由Hoeffding不等式,就能得到:
![]()
也就是说,只要我们能保证训练集的量N足够大,就能保证训练集的错误率与真实的预测错误率是有很大概率接近的。
3 对于有限多个h的情况
上面一节我们证明了,对于一个给定的假设函数h,只要训练集足够大,我们能保证它在训练集上的预测效果与真正的预测效果很大概率是接近的。但是,我们只能保证它们的预测效果接近,也可能预测效果都是坏呢?
我们的机器学习算法是在假设空间里面选一个h,使得这个h在训练集上错误率很小,那么这个h是不是在整个输入空间上错误率也很小呢?这一节我们要证明的就是,对于假设空间只有有限个h时,只要训练集N足够大,这也是很大概率成立的。
首先我们来看这张表:
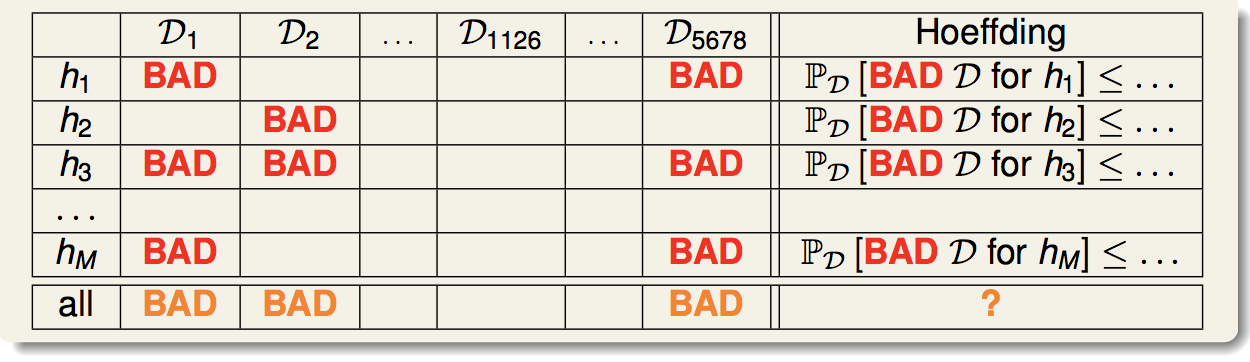
首先,对于一个给定的h,我们可以定义一个概念:“坏的训练集”(对应于表中红色的bad)。所谓坏的训练集,就是h在这个训练集上面的Ein和真实的Eout的差异超过了我们定义的容忍度ε。Hoeffding不等式保证了,对于一个给定的h(表中的一行),选到坏的训练集的概率是很低的。
然后,对于假设空间里面有M个候选的h,我们重新定义“坏的训练集”的概念(对应于表中橙色的bad),只要它对于任何一个h是坏的,那么它就是一个坏的。那么我们选到橙色坏的训练集的概率可以如下推导:

由于M是有限的,只要训练集N足够大,我们选到坏训练集的概率仍然是很小的。也就是说,我们的训练集很大可能是一个好的训练集,所有的h在上面都是好的,算法只要选取一个在训练集上表现好的h,那么它的预测能力也是PAC好的。也就是有不等式:
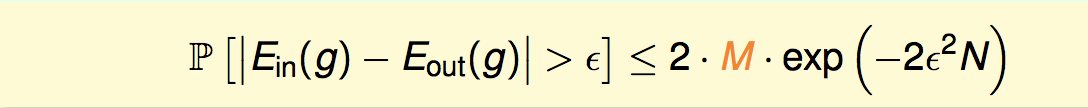
因此机器学习过程如下图:
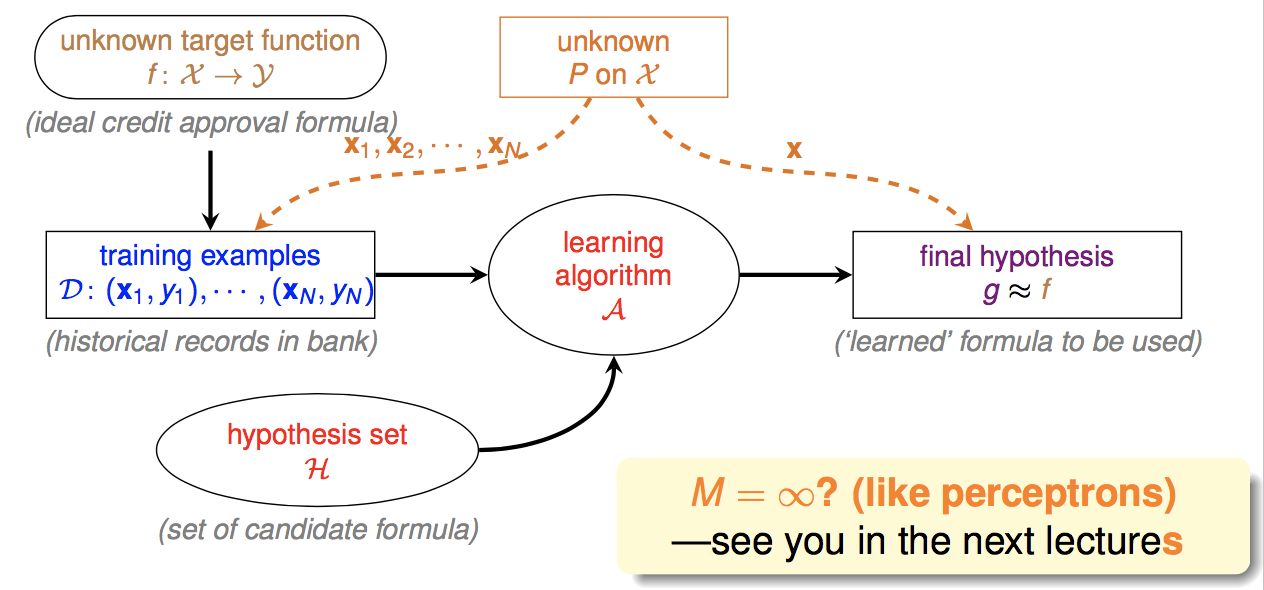
(这里多出来的橙色部分表示,训练集和测试集是由同一个概率分布产生的)
因此当有限个h的情况下,机器学习算法确实是能学到东西的。
之后我们会讨论,当假设空间存在无限个h时,机器学习是否还有效。