1 生成模型的定义和分类
生成模型是一种无监督学习方法。其定义是给一堆由真实分布产生的训练数据,我们的模型从中学习,然后以近似于真实的分布来产生新样本。

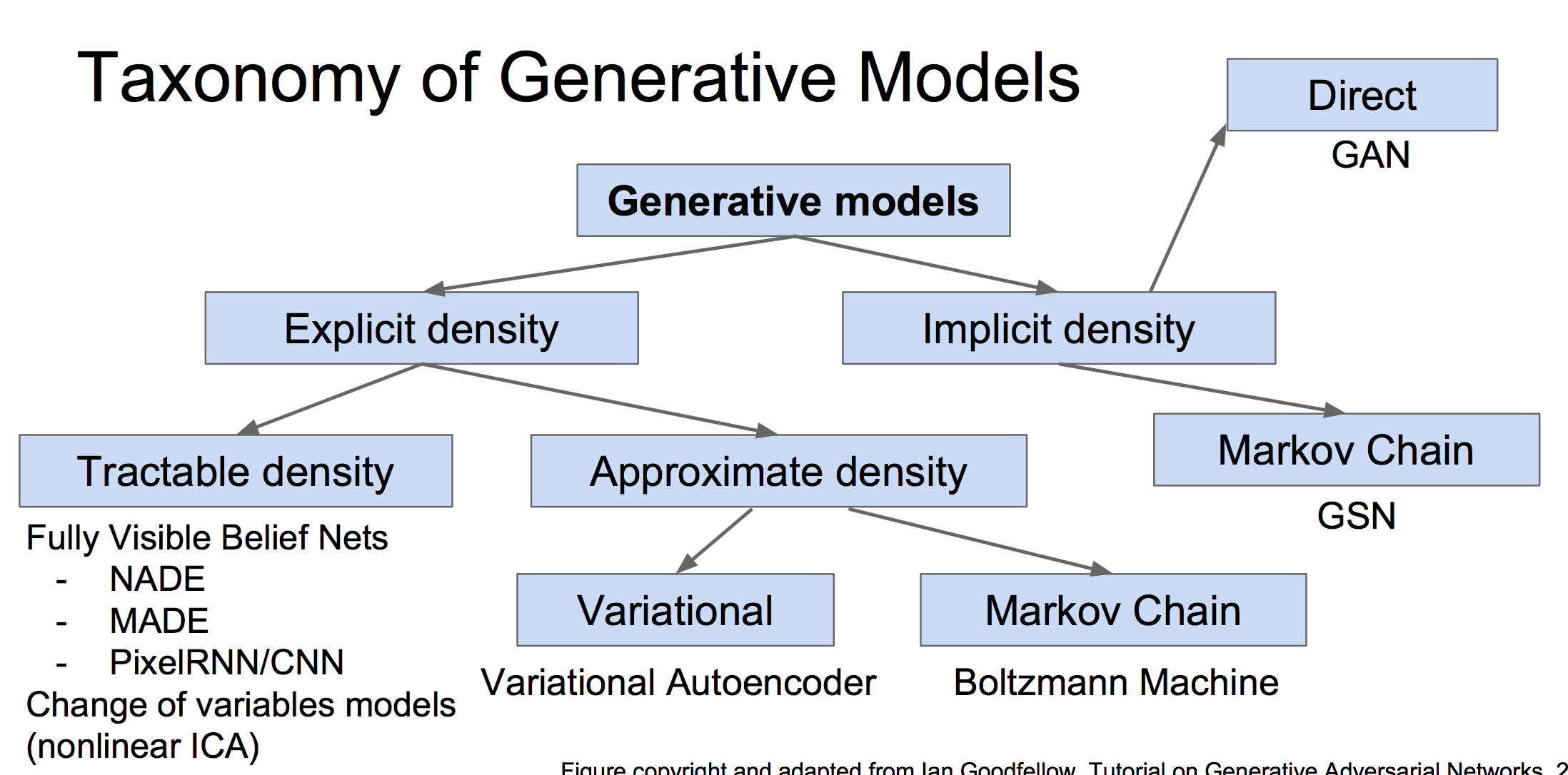
生成模型分为显式和隐式的生成模型:
为什么生成模型重要:
生成样本,着色问题,强化学习应用,隐式表征推断等。
2 PixelRNN and PixelCNN
PixelRNN和PixelCNN是使用 概率链式法则来计算一张图片出现的概率。其中每一项为给定前i-1个像素点后第i个像素点的条件概率分布。这个分布通过神经网络RNN or CNN来建模,再通过最大化图片x的似然来学习出RNN or CNN的参数。

pixelRNN中,从左上角开始定义为“之前的像素”。由于RNN每个时间步的输出概率都依赖于之前所有输入,因此能够用来表示上面的条件概率分布。

训练这个RNN时,一次前向传播需要从左上到右下串行走一遍,然后根据上面的公式求出似然,并最大化似然以对参数做一轮更新。因此训练非常耗时。
PixelCNN中,使用一个CNN来接收之前的所有像素,并预测下一个像素的出现概率:
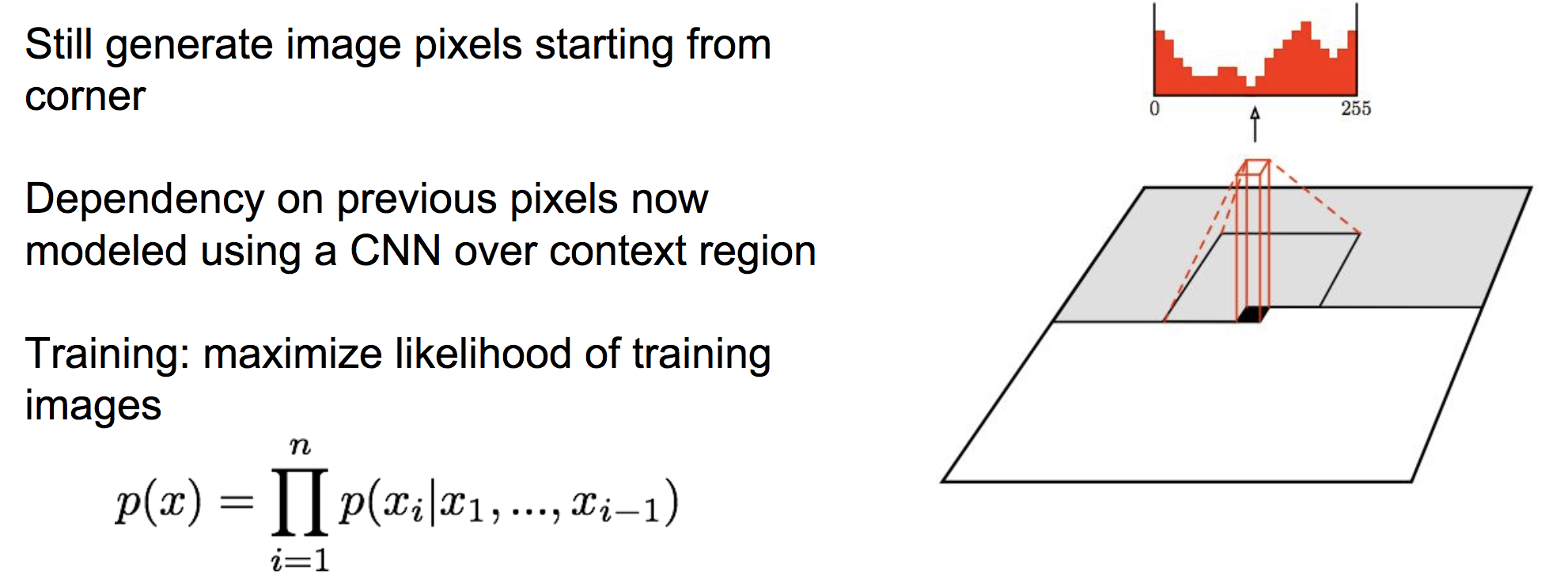
相比于pixelRNN,pixelCNN在训练时可以并行的求出公式中的每一项,然后进行参数更新,因此其训练速度要比pixelRNN快多了。
然而,无论是pixelRNN还是pixelCNN,其在预测时都需要从左上角开始逐个像素点地生成图片,因此预测阶段都比较慢。
3 变分自编码器VAE
参考:这篇博客对VAE的讲解非常好,《只知道GAN你就OUT了——VAE背后的哲学思想及数学原理》http://geek.csdn.net/news/detail/201178
(1)背景:自编码器
自编码器是为了无监督地学习出样本的特征表示,原理如下:
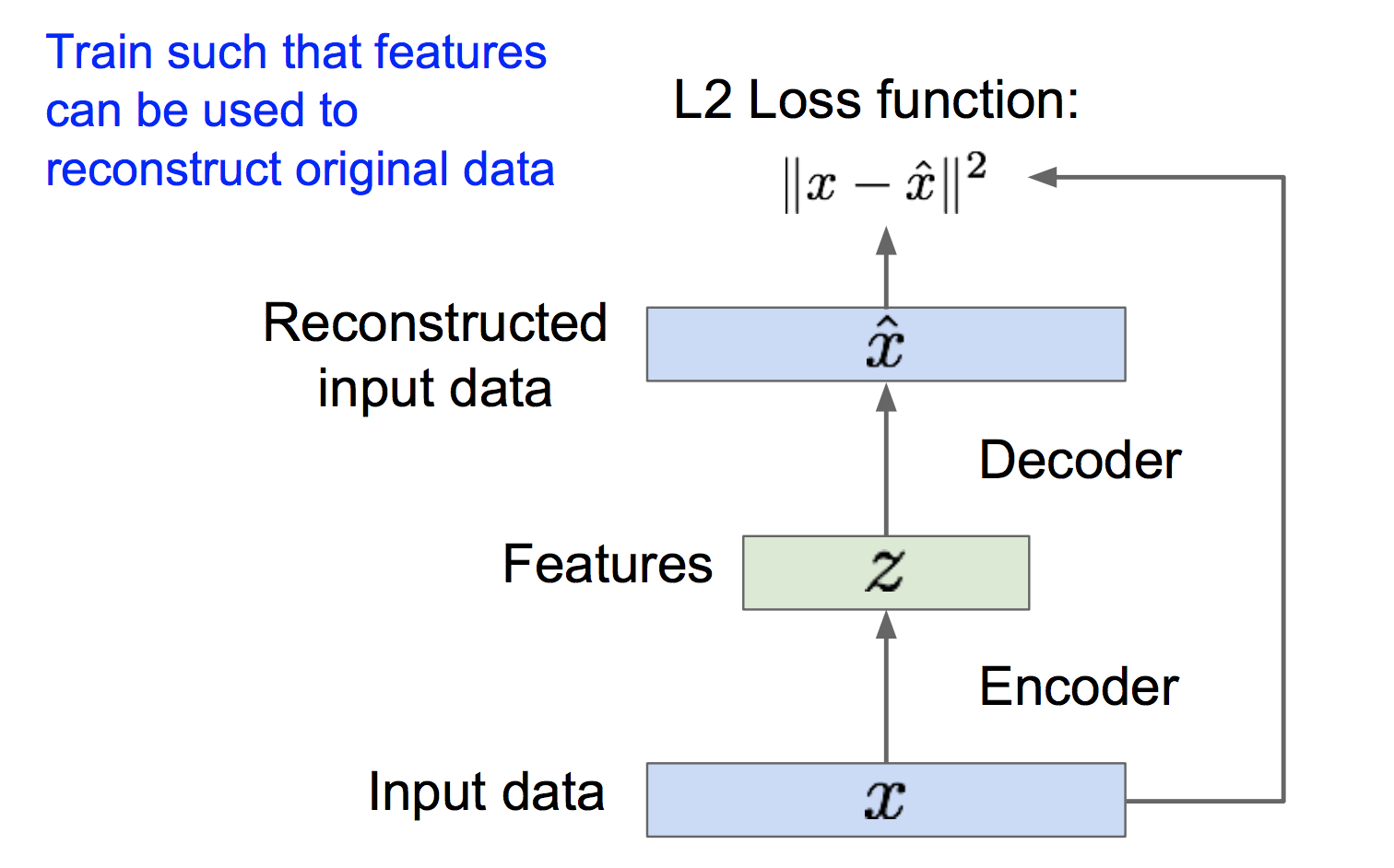
如上图,自编码器由编码器和解码器组成,编码器将样本x映射到特征z,解码器再将特征z映射到重构样本。为了能够使z解码后能够恢复出原来的x,我们最小化x与重构样本之间的l2损失,进而可以训练出编码器和解码器的参数。
(2)VAE的思想
VAE的思想是,既然我们无法直接获得样本x的分布,那么我们就假设存在一个x对应的隐式表征z,z的分布是一个简单的高斯分布(或者其他简单的分布,总之是人为指定的)。z经过解码网络后,能够映射得到x的近似真实分布。这样的话我们就可以通过在标准正态分布上采样得到z,然后解码得到样本近似分布,再在此分布上采样来生成样本。
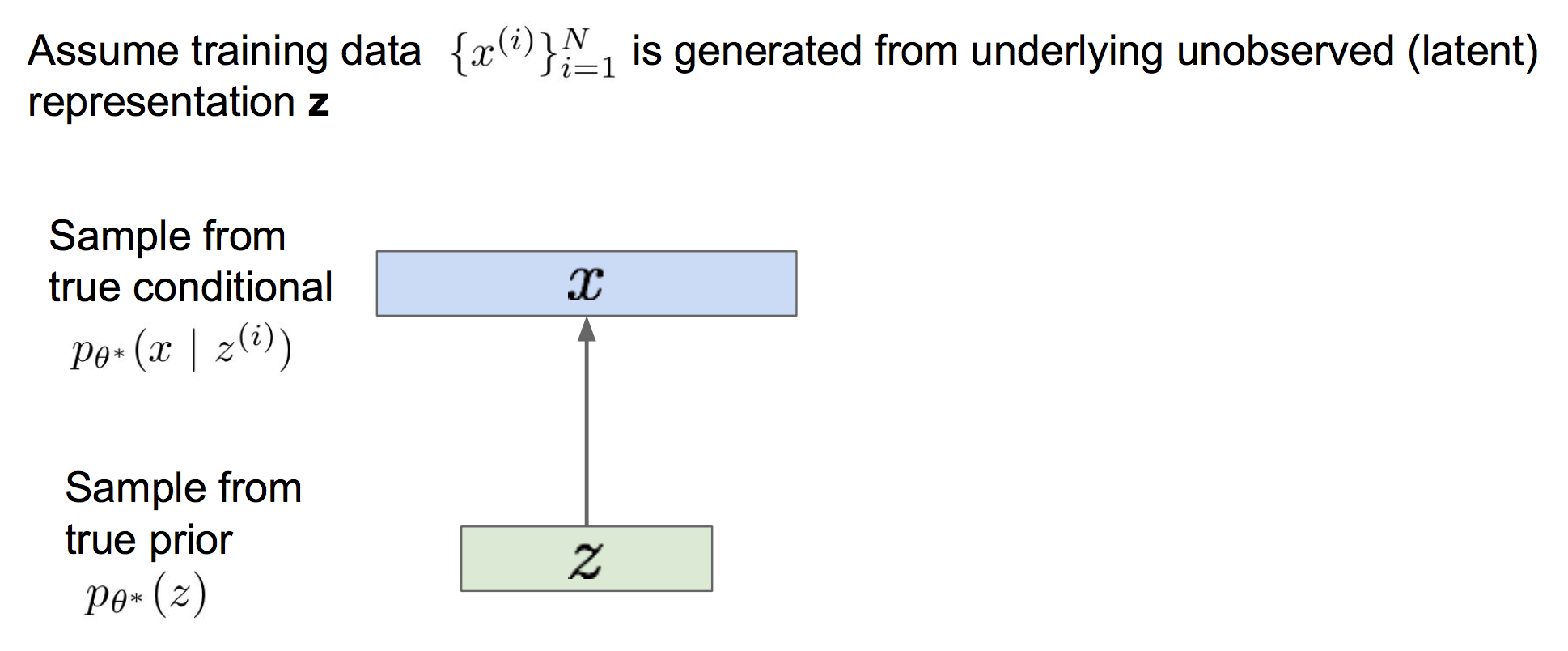
(3)如何训练VAE
现在的问题是,有一堆样本,我们如何从中学习出解码网络的参数,使得在标准高斯分布上采样得到的z,经过解码后得到的x的分布,刚好近似于x的真实分布呢?
我们的方案是最大化样本x的似然P(x)(可以仔细思考下,为什么最大化似然能够使得得到的解码器具有上面的性质)。
对样本x的似然P(x)做一个推导:
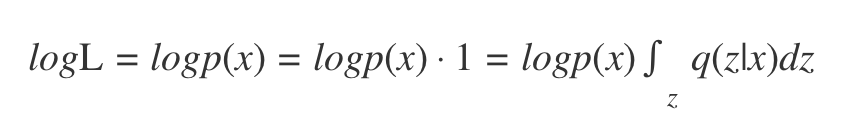
这里引入了一个分布q(z|x),我们可以用一个网络来建模这个分布,也就是后面的编码网络。这里我们暂时只把它当作一个符号,继续推导即可:
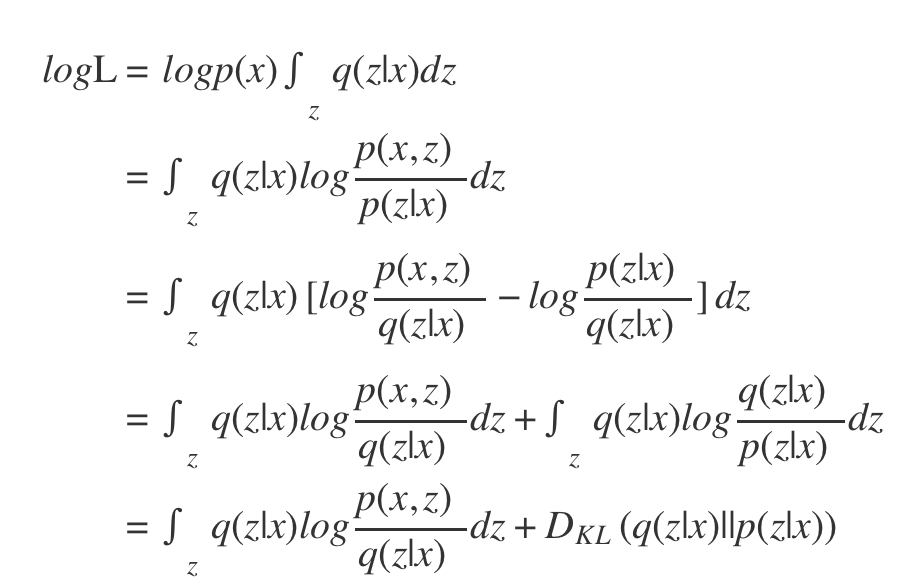
对第一项,我们有:
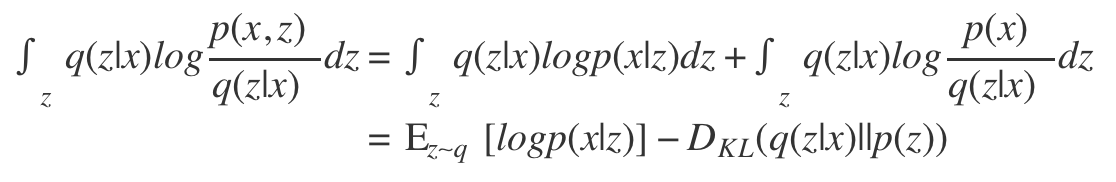
这样我们就得到了VAE的核心等式:
![]()
注意到这个式子的第三项中,含有p(z|x),而
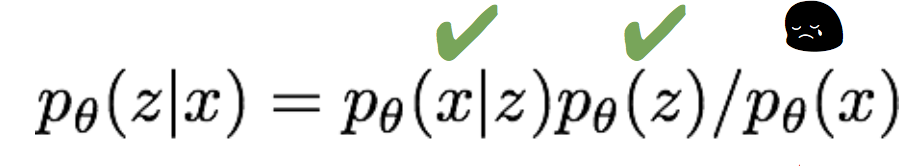
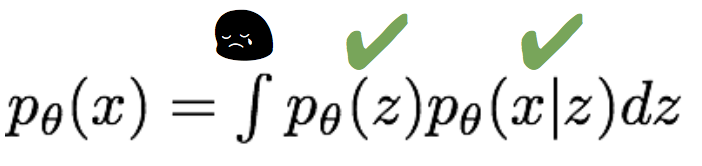
由于这个积分无法求解出来,因此我们没办法求第三项的梯度。幸运的是,由于第三项是一个KL散度,其恒大于等于0,因此前两项的和是似然的一个下界。因此我们退而求其次,来最大化似然的下界,间接达到最大化似然的目的。
现在我们引入编码器网络来对q(z|x)建模,我们的训练框架如下:
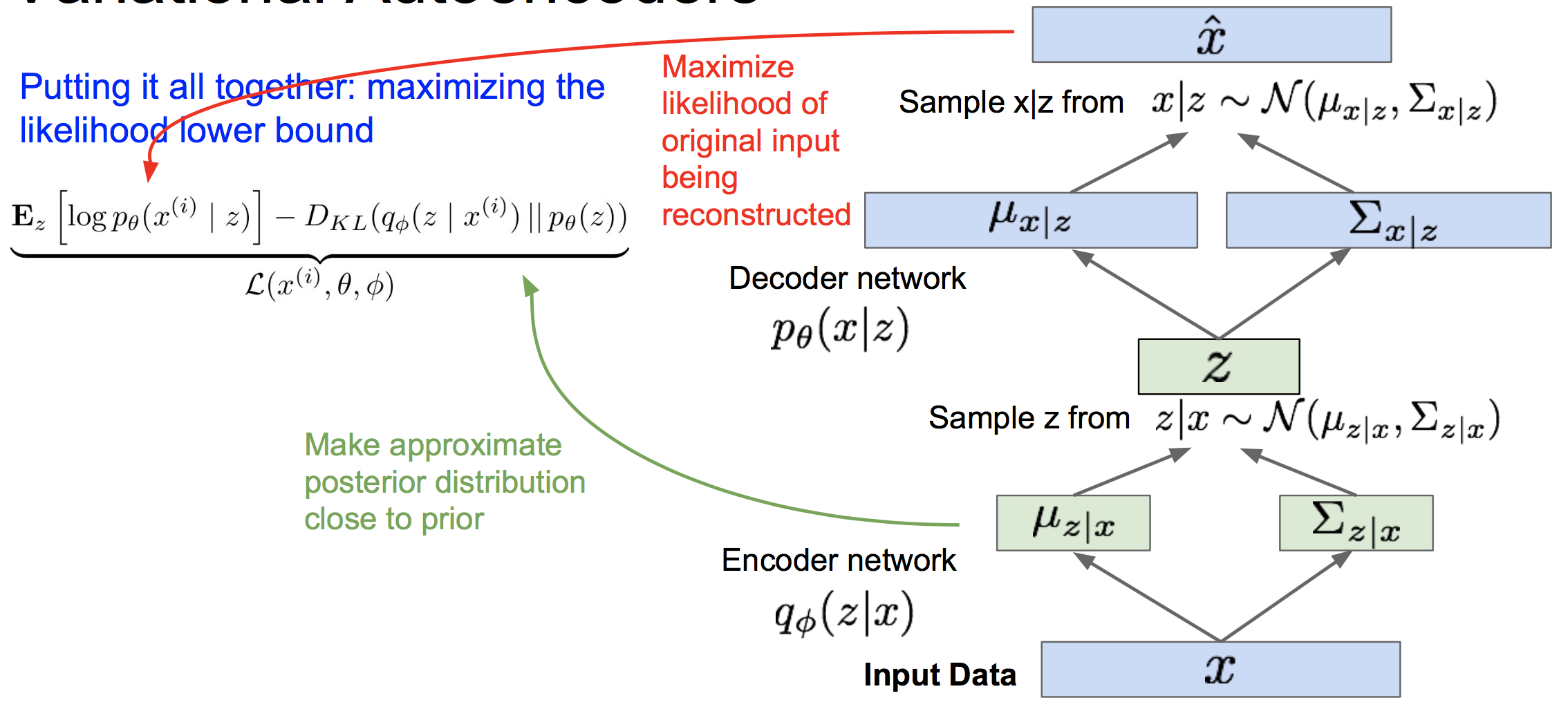
这个框架就非常类似于自编码器。其中最大化下界的第一项表示我们要能从解码器最大概率地重构出x,这一步等价于去最小化 ![]() 与样本x的均方误差。最小化下界的第二项则限定了z要遵循我们事先给它指定的分布。
与样本x的均方误差。最小化下界的第二项则限定了z要遵循我们事先给它指定的分布。
需要注意的是,这个框架里面,梯度无法通过“采样“这个算子反向传播到编码器网络,因此我们使用一种叫做重采样的trick。即将z采样的算子分解为:
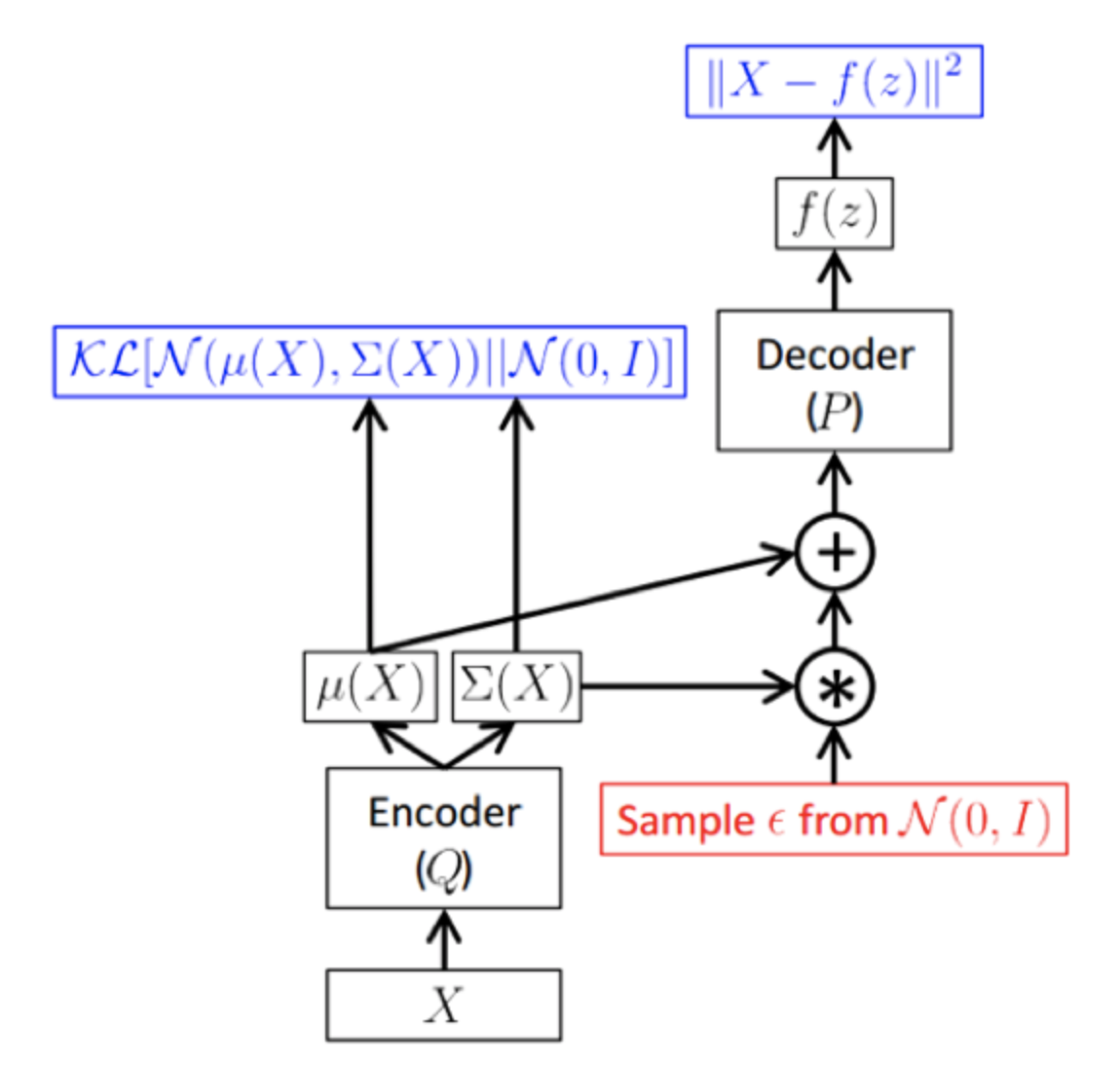
这样梯度不需要经过采样算子就能回流到编码器网络中。
(4)VAE的优缺点

4 生成式对抗网络 GAN
(1)理解GAN如何工作
相比变分自编码器,理解GAN如何工作非常简单。在GAN中我们定义了两个网络:生成器和判别器。
判别器负责辨别哪些样本是生成器生成的假样本,哪些是从真实训练集中抽出来的真样本。
生成器负责利用随机噪声z生成假样本,它的职责是生成尽可能真的样本以骗过判别器。
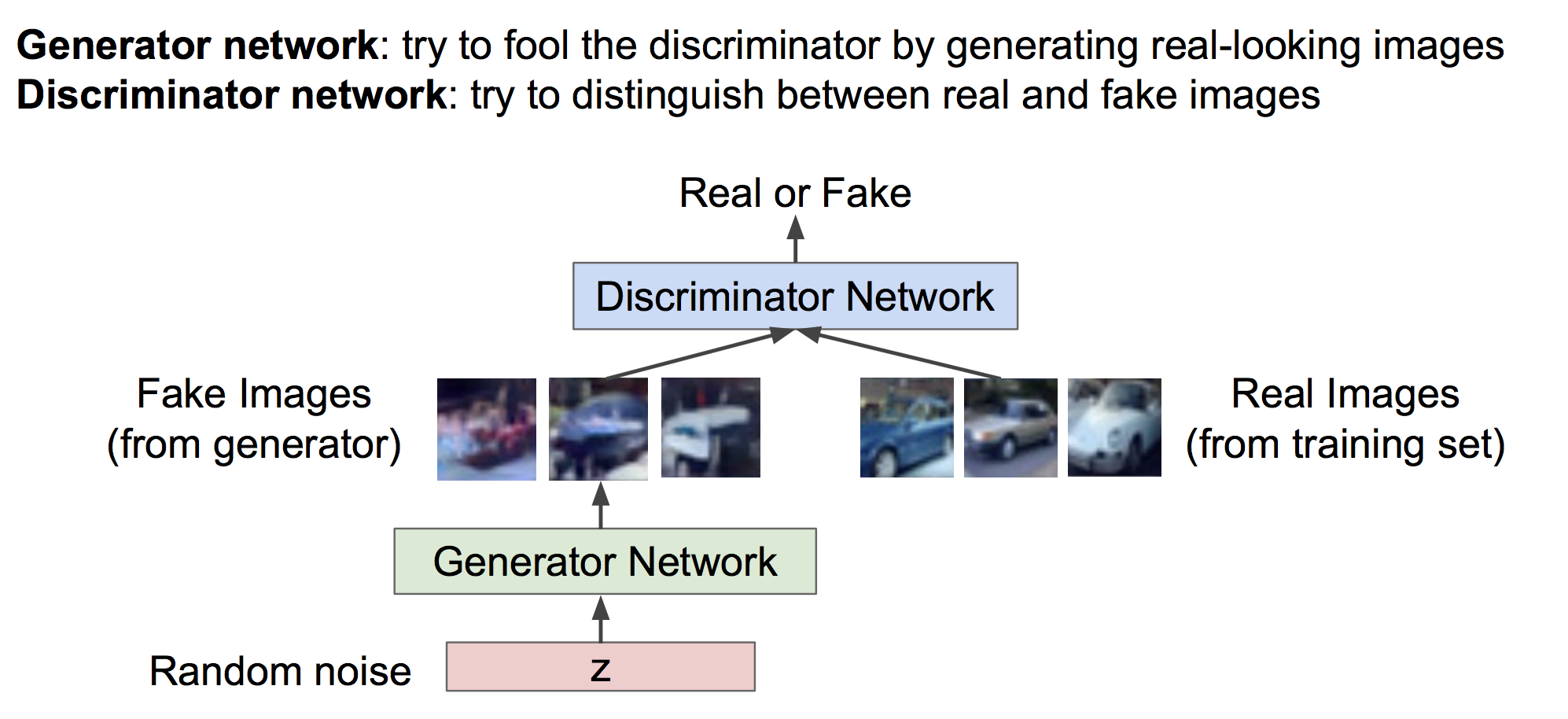
这种对抗形式的目标可以写成如下形式:

因此训练GAN的方法是交替的训练生成器和判别器,在生成器上做梯度下降,在判别器上做梯度上升:
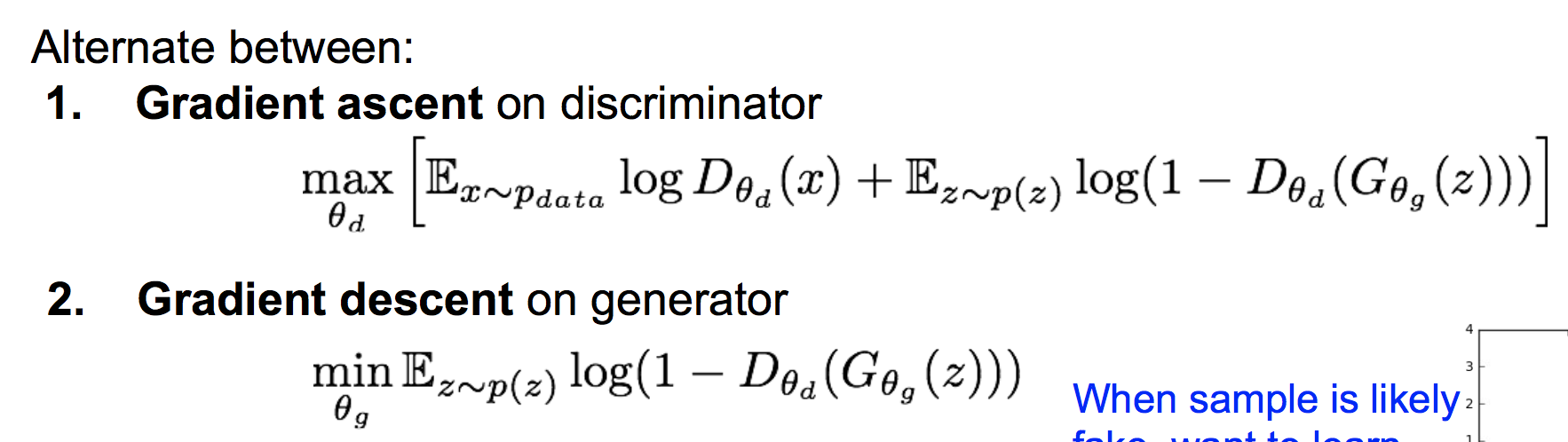
这里有个trick:我们观察生成器的损失函数形状如下:
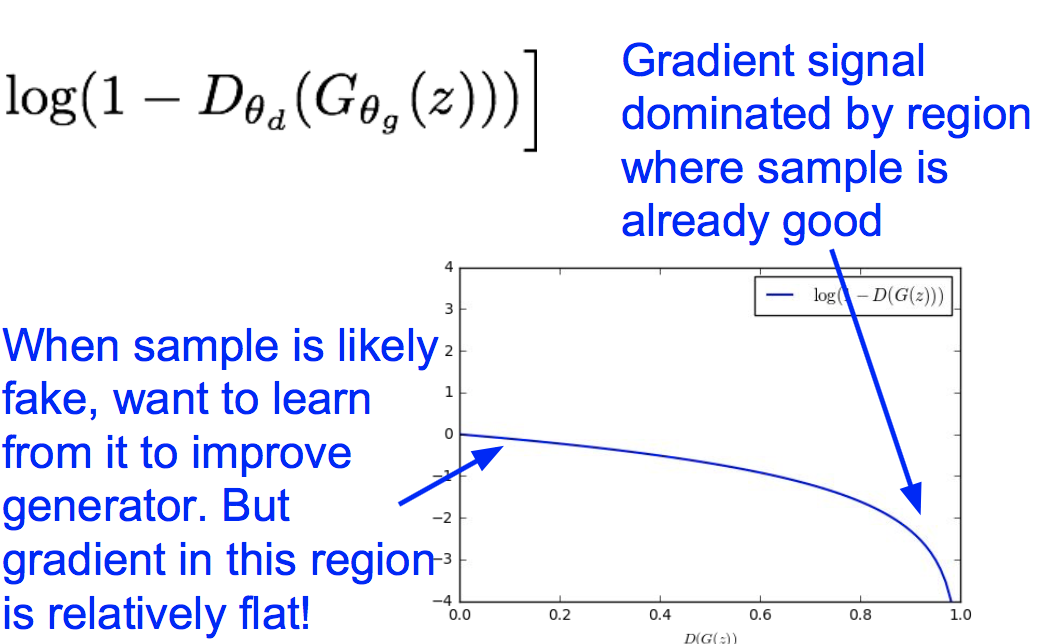
发现当生成器效果不好(D(G(z)接近0)时,梯度非常平缓;当生成器效果好(D(G(z)接近1)时,梯度很陡峭。这就与我们期望的相反了,我们希望在生成器效果不好的时候梯度更陡峭,这样能学到更多。因此我们使用下面的目标函数来替代原来的生成器损失:
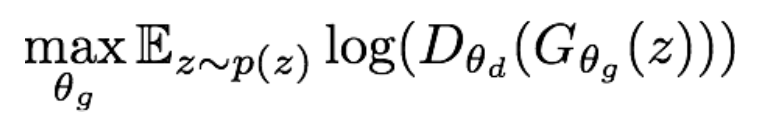
这样就使得在生成器效果不好时具有较大的梯度。
因此,GAN的训练过程如下:

训练完毕后,就可以用生成器来生成比较逼真的样本了。
(2)GAN的探索
a 传统的GAN生成的样本还不是很好,这篇论文在GAN中使用了CNN架构,取得了惊艳的生成效果:
Radford et al, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”, ICLR 2016
b Wasserstein GAN 一定程度解决了GAN训练中两个网络如何平衡的问题。
c 用GAN来做text->image
等等

(3)GAN的优缺点以及热门研究方向

5 总结
各个生成模型的优缺点:
