7.1 认识事务
7.1.1 概述
事务会把数据库从一种一致状态转换为另一种一致状态,在数据库提交工作时,可以确保其要么所有修改都已经保存了,要么所有修改都不保存。
ACID:原子性,一致性,隔离性,持久性
原子性:原子性是指整个数据库事务是不可分割的工作单位。只有使事务中所有的数据库操作执行都成功,才算整个事务成功。如果事务中任何一个sql语句执行失败,那么已经执行成功的sql语句也必须撤销,数据库状态应该退回到执行事务前的状态。
一致性:一致性指事务将数据库从一种状态转变为下一种一致的状态。在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
隔离性:一个事务的影响在该事务提交前对其他事务都不可见----这通过锁来实现
持久性:事务一旦提交,其结果就是永久性的。即使发生宕机等故障,数据库也能将数据恢复。
7.1.2 分类
1) 扁平事务
实际生产环境中最频繁的一种事务,所有操作都处于同一层次,要么都执行,要么都回滚;
- 优点:使用简单,广泛使用。
- 缺点:不能提交事务的一部分,或分步骤提交。
2) 带有保存点的扁平事务
除了支持扁平事务外,允许在事务执行的过程中回滚到同一事务中的较早一个状态(保存点savepoint);
当系统发生崩溃时,所有的保存点都将消失,因为其保存点是易失的,而非持久的。
3) 链事务
提交一个事务时,释放不需要的数据对象,将必要的处理上下文隐式的传给下一个要开始的事务。
链式事务只能回滚仅限于当前事务,即只能恢复到最近一个保存点;

4) 嵌套事务
嵌套事务时一个层次结构框架,有一个顶层事务控制着各个层次的事务(子事务);
mysql不是原生的;
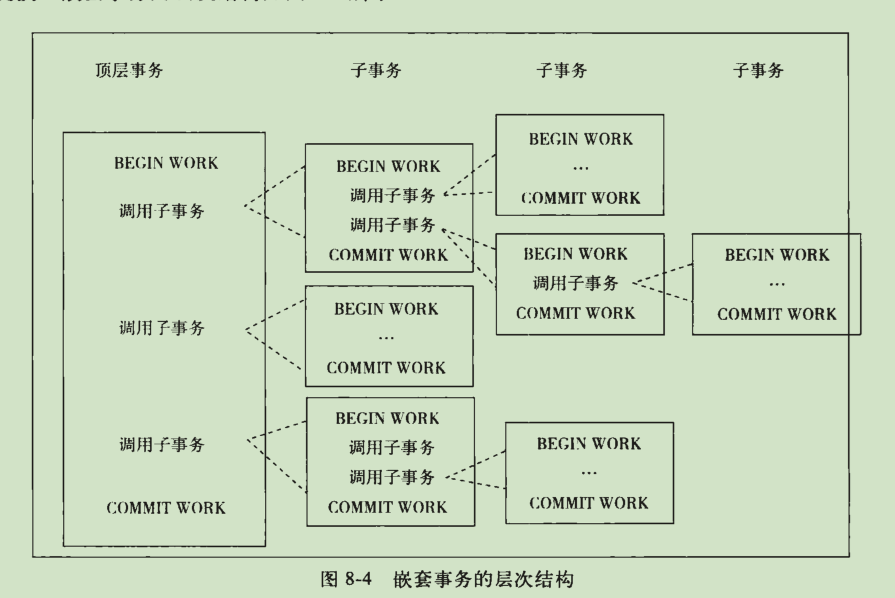

保存技术比嵌套查询更灵活;
当使用保存技术,无论持有多少个保存点,所有被锁住的对象都可以被得到和访问;
而嵌套查询中,不同的子事务在数据库对象上持有锁不同;
5) 分布式事务
通常是一个在分布式环境下运行的扁平事务;
7.2 事务的实现 (重点)
隔离性由锁来实现;原子性、一致性和持久性通过数据库的redo和undo来完成。
redo log 称为重做日志,用来保证事务的原子性和持久性。undo log 用来保证事务的一致性。锁保证事务的隔离性。
redo 和 undo 的作用都可以视为一种恢复操作,redo 恢复提交事务修改的页操作,undo 回滚行记录到某个特定版本。
redo 通常是物理日志,记录的是页的物理修改操作;undo 是逻辑日志,根据每行记录进行记录。
7.2.1 redo
InnoDB中,事务日志通过重做(redo)日志文件和InnoDB存储引擎的日志缓冲来实现。
当开始一个事务时,会记录该事务的一个LSN(日志序列号),当事务执行时,会往InnoDB的日志缓冲里插入事务日志,当事务提交时,必须将innoDB存储引擎的日志缓冲写入磁盘。也就是在写数据前,需要先写日志。这种方式称为预写日志方式。
InnoDB通过预写日志的方式来保证事务的完整性。这意味着磁盘上存储的数据页和内存缓冲池中的数据页是不同步的,对于内存缓冲池中页的修改,先是写入重做日志文件,然后再写入磁盘,因此是一种异步的方式。
innodb_flush_log_at_trx_commit :
控制redo日志刷新到磁盘的策略,默认是1,表示事务提交必须调用一次fsync操作 ;
0 代表当事务提交时,并不将事务的redo日志写入磁盘的日志文件,而是等待主线程每秒的刷新;
1和2不同在于: 1表示执行commit时将redo log buffer同步写到磁盘,即伴有fsync的调用 ,
2表示将redo日志异步写到磁盘,即写到文件系统的缓存中,因此不能完全保证在执行commit时会写入redo日志文件,只是有这个动作发生;
为了保证事务的ACID持久性,必须将其设置为1,也就是事务commit时,必须保证事务都已经写入redo log文件, 那么当数据库宕机时可以通过redo日志文件恢复,并保证恢复已经提交的事务;
1.redo log和binlog 区别
产生层面: redo log是innodb引擎层面完成的, binlog是mysql数据库的层产生的,任何存储引擎对于数据库的修改都会产生二进制日志 ;
格式: redo log是物理格式日志,记录的是每个页的修改; binlog 是逻辑日志,记录的是对应的SQL语句 ;
写入时间点: redo在事务进行中不断写入,日志并不是随事务提交的顺序进行写入的; binlog 只在事务提交完成后进行一次写入 ;
2.log block
InnoDB 中,重做日志都是以512字节进行存储的。故,重做日志缓冲,重做日志文件都是以块方式进行保存的,称之为重做日志块(redo log block)。
重做日志块跟磁盘扇区大小一样,因此重做日志写入可以保证原子性,不需要双写技术;
重做日志块组成: 日志块头 (12字节) + 日志 (492字节) + 日志块尾 (8字节)
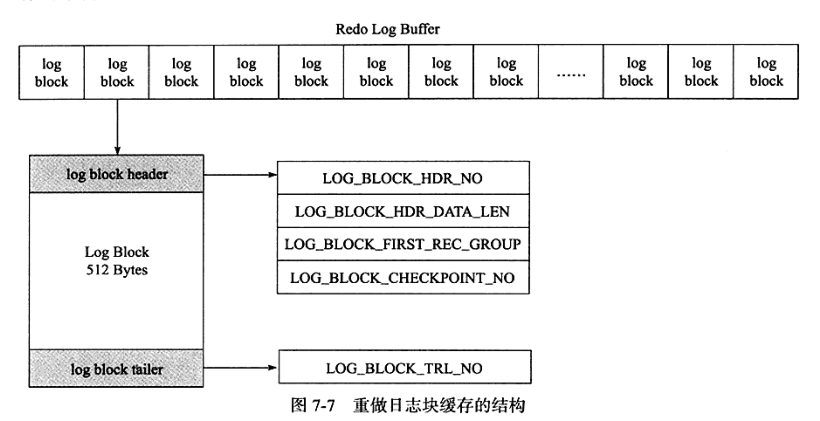

LOG_BLOCK_HDR_NO : 标记log buffer位置,递增并循环使用;
LOG_BLOCK_HDR_DATA_LEN : 占用2个字节,表示log block所占用的大小;
LOG_BLOCK_FIRST_REC_GROUP :表示log block中第一个日志所在的偏移量 ;
LOG_BLOCK_CHECKPOINT_NO : 表示log block最后被写入时的检查点第4字节的值;
LOG_BLOCK_TRL_NO : 与LOG_BLOCK_HDR_NO值相同,并在log_block_init中被初始化;
3.log group
逻辑上的概念,由多个redo日志文件组成,大小相同;
redo日志写入过程:
不是直接写,而是先写入一个redo log buffer(缓冲)中,然后按照一定的条件顺序地写入日志文件(日志组),
log buffer根据一定规则将内存中的log block刷新到磁盘,具体规则是:
- 当事务提交时
- 当log buffer有一般的内存空间已经被使用时
- log checkpoint时
log block的写入追加在redo log file的最后部分,一个写满会写入下一个file中. 使用的方式是round-robin (轮叫调度)

redo log file写入并不是完全顺序的,
4.重做日志写入格式

5.LSN
日志序列号,Innodb中,占8字节,单调递增;
LSN含义有:
- 重做日志写入的总量
- checkpoint的位置
- 页的版本
7.2.2 undo
- 基本概念
重做日志记录了事务的行为,可以很好地通过其进行"重做",但是事务有时还需要撤销,这就需要undo。
undo与redo正好相反,对数据库进行修改时,数据库不但会产生redo,而且会产生一定量的undo,即使你执行的事务或语句由于某种原因失败了,或者如果你用一条rollback语句请求回滚,就可以利用这些undo信息将数据回滚到修改之前的样子。
与redo不同的是,redo存放在重做日志文件中,undo存放在数据库内部的一个特殊段(segment)中,称为undo段,undo段位于共享表空间内。
我们通常对undo有这样的误解:undo用于将数据库物理地恢复到执行语句或事务之前的样子——但事实并非如此。数据库只是逻辑地恢复到原来的样子,所有修改都被逻辑地取消,但是数据结构本身在回滚之后可能大不相同,因为在多用户并发系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要任务就是协调对于数据记录的并发访问。如一个事务在修改当前页中某几条记录,但同时还有别的事务在对同一页中另几条记录进行修改。因此,不能将一个页回滚到事务开始的样子,因为这样会影响其他事务正在进行的工作。
例如:我们的事务执行了一个INSERT 10万条记录的SQL语句,这条语句可能会导致分配一个新的段,即表空间会增大。如果我们执行ROLLBACK时,会将插入的事务进行回滚,但是表空间的大小并不会因此而收缩。因此,当InnoDB存储引擎回滚时,它实际上做的是与先前相反的工作。对于每个INSERT,InnoDB存储引擎会完成一个DELETE;对于每个DELETE,InnoDB存储引擎会执行一个INSERT;对于每个UNDATE,InnoDB存储引擎会执行一个相反的UPDATE,将修改前的行放回去。
undo的另一个作用是MVCC,即在innodb中的MVCC实现是通过undo来完成, 当用户读取一行记录时,若该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读取 ;
持久化: undo log也会产生redo log ,因为undo log也需要持久性的保护 ;
- undo存储管理
采用段的方式;
rollback segment 参数设置
- innodb_undo_directory : 设置回滚段文件所在的路径,可以放在共享表空间意外的位置, 默认值为 . ,表示当前innodb存储引擎的目录 ;
- innodb_undo_logs : 用来设置回滚段的个数,默认值是128 , 后来被innodb_rollback_segments参数替代 ;
- innodb_undo_tablespaces :设置构成回滚段文件的数量, 这样回滚段可以较为平均地分布在多个文件中
show engine innodb status ;
---> History list length 3 ; 代表undo log的数据. ;
purge操作会减少 该值 ,(清洗线程) ,
- undo log格式
innodb中分为 : inset undo log和update undo log ;
inset undo log
是指在insert操作中产生的undo log, 因为insert 操作的记录只对事务本身可见,对其他事务不可见, 所以该undo log可以在事务提交后直接删除,不需要进行purge操作;

insert undo log中: (带*的是对存储字段进行压缩)
开始的前两个字节next : 记录的是下一个undo log的位置, 可以知道一个undo log所占的空间字节数;
尾部的两个字节start : 记录的undo log 开始的位置
type_cmpl: 占用一个字节,记录的是undo的类型,对于insert undo log总是11,
undo_no: 记录的是事务的ID,
table_id: undo log对应的表对象
update undo log
记录的delete和update操作产生的undo log;
不能在事务提交时就进行删除 , 提交时放入undo log链表,等待purge线程进行最后的删除,
有一部分跟insert undo log相同,
type_cmpl: 可能的值有
❑12 TRX_UNDO_UPD_EXIST_REC更新non-delete-mark的记录
❑13 TRX_UNDO_UPD_DEL_REC将delete的记录标记为not delete
❑14 TRX_UNDO_DEL_MARK_REC将记录标记为delete
update_vector 表示update操作导致发生改变的列。每个修改的列信息都要记录的undo log中。对于不同的undo log类型,可能还需要记录对索引列所做的修改。
- 查看undo信息
delete操作并不直接删除记录,而只是将记录标记为已删除,也就是将记录的delete flag设置为1。而记录最终的删除是在purge操作中完成的。
update主键的操作其实分两步完成。
首先将原主键记录标记为已删除,因此需要产生一个类型为TRX_UNDO_DEL_MARK_REC的undo log,
之后插入一条新的记录,因此需要产生一个类型为TRX_UNDO_INSERT_REC的undo log。undo_rec_no显示了产生日志的步骤。
7.2.3 purge
purge用于最终完成delete和update操作。
这样设计是因为InnoDB存储引擎支持MVCC,所以记录不能在事务提交时立即进行处理。这时其他事物可能正在引用这行,故InnoDB存储引擎需要保存记录之前的版本。
而是否可以删除该条记录通过purge来进行判断。若该行记录已不被任何其他事务引用,那么就可以进行真正的delete操作。
为了节省存储空间,InnoDB存储引擎的undo log设计是这样的:一个页上允许多个事务的undo log存在。虽然这不代表事务在全局过程中提交的顺序,但是后面的事务产生的undo log总在最后。此外,InnoDB存储引擎还有一个history列表,它根据事务提交的顺序,将undo log进行链接。
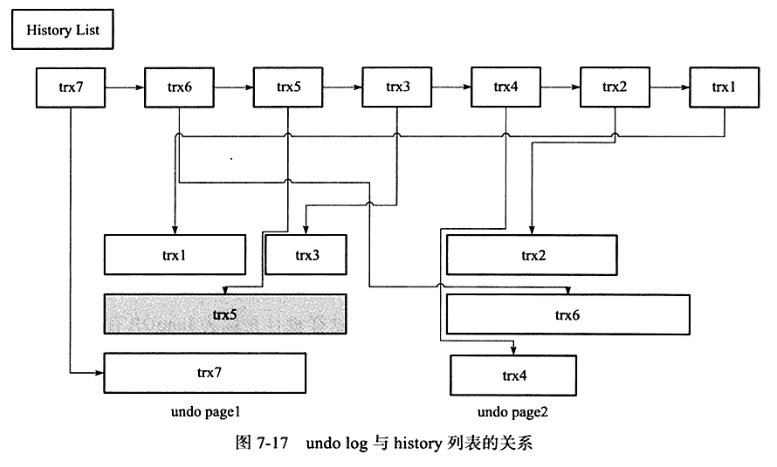
InnoDB存储引擎这种先从history list中找undo log,然后再从undo page中找undo log的设计模式是为了避免大量的随机读取操作,从而提高purge的效率。
innodb_purge_batch_size : 全局动态参数,用来设置每次purge操作需要清理的undo page数量。
innodb_max_purge_lag: 全局动态参数 , 用来控制history list的长度,若长度大于该参数时,其会"延缓"DML的操作。该参数默认值为0,表示不对history list做任何限制。当大于0时,就会延缓DML的操作,其延缓的算法为:
delay=((length(history_list)-innodb_max_purge_lag)*10)-5
delay的单位是毫秒。
delay的对象是行,而不是一个DML操作。例如当一个update操作需要更新5行数据时,每行数据的操作都会被delay,故总的延时时间为5*delay。而delay的统计会在每一次purge操作完成后,重新进行计算。
innodb_max_purge_lag_delay: InnoDB1.2版本引入了新的全局动态参数,其用来控制delay的最大毫秒数。也就是当上述计算得到的delay值大于该参数时,将delay设置为innodb_max_purge_lag_delay,避免由于purge操作缓慢导致其他SQL线程出现无限制的等待。
7.2.4 group commit
若事务为非只读事务,则每次事务提交时需要进行一次fsync操作,以此保证重做日志都已经写入磁盘。当数据库发生宕机时,可以通过重做日志进行恢复。
为了提高磁盘fsync的效率,当前数据库都提供了group commit的功能,即一次fsync可以刷新确保多个事务日志被写入文件。
步骤
对于InnoDB存储引擎来说,事务提交时会进行两个阶段的操作:
1)修改内存中事务对应的信息,并且将日志写入重做日志缓冲。
2)调用fsync将确保日志都从重做日志缓冲写入磁盘。
步骤2)相对步骤1)是一个较慢的过程,这是因为存储引擎需要与磁盘打交道。但当有事务进行这个过程时,其他事务可以进行步骤1)的操作,正在提交的事物完成提交操作后,再次进行步骤2)时,可以将多个事务的重做日志通过一次fsync刷新到磁盘,这样就大大地减少了磁盘的压力,从而提高了数据库的整体性能。对于写入或更新较为频繁的操作,group commit的效果尤为明显。
问题
然而在InnoDB1.2版本之前,在开启二进制日志后,InnoDB存储引擎的group commit功能会失效,从而导致性能的下降。并且在线环境多使用replication环境,因此二进制日志的选项基本都为开启状态,因此这个问题尤为显著。
导致这个问题的原因是在开启二进制日志后,为了保证存储引擎层中的事务和二进制日志的一致性,二者之间使用了两阶段事务,其步骤如下:
1)当事务提交时InnoDB存储引擎进行prepare操作。
2)MySQL数据库上层写入二进制日志。
3)InnoDB存储引擎层将日志写入重做日志文件。
a)修改内存中事务对应的信息,并且将日志写入重做日志缓冲。
b)调用fsync将确保日志都从重做日志缓冲写入磁盘。
一旦步骤2)中的操作完成,就确保了事务的提交,即使在执行步骤3)时数据库发生了宕机。此外需要注意的是,每个步骤都需要进行一次fsync操作才能保证上下两层数据的一致性。步骤2)的fsync由参数sync_binlog控制,步骤3)的fsync由参数innodb_flush_log_at_trx_commit控制。因此上述整个过程如图7-18所示。
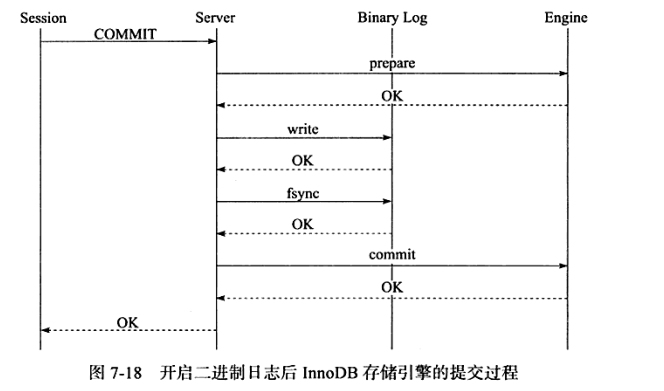
为了保证MySQL数据库上层二进制日志的写入顺序和InnoDB层的事务提交顺序一致,MySQL数据库内部使用了prepare_commit_mutex这个锁。但是在启用这个锁之后,步骤3)中的步骤a)步不可以在其他事务执行步骤b)时进行,从而导致了group commit失效。
然而,为什么需要保证MySQL数据库上层二进制日志的写入顺序和InnoDB层的事务提交顺序一致呢?
这时因为备份及恢复的需要,例如通过工具xtrabackup或者ibbackup进行备份,并用来建立replication,如图7-19所示。
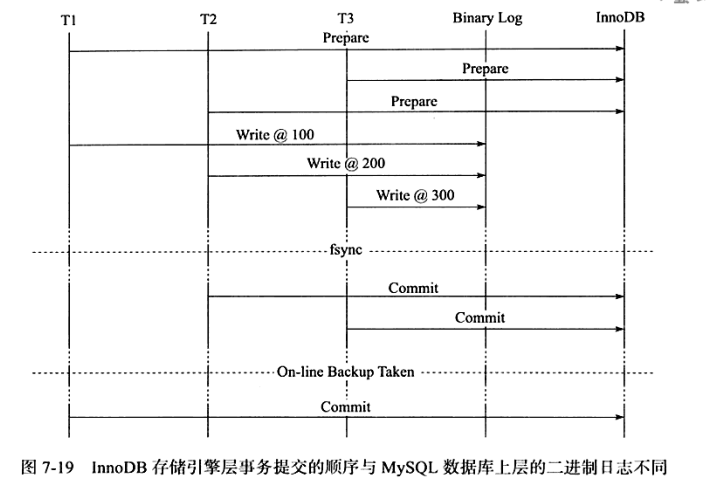
可以看到若通过在线备份进行数据库恢复来重新建立replication,事务T1的数据会产生丢失。因为在InnoDB存储引擎层会检测事务T3在上下两层都完成了提交,不需要再进行恢复。因此通过锁prepare_commit_mutex以串行的方式来保证顺序性,然而这会使group commit无法生效,如图7-20所示。

BLGC
不但MySQL数据库上层的二进制日志写入是group commit的,InnoDB存储引擎层也是group commit的。
此外还移除了原先的锁prepare_commit_mutex,从而大大提高了数据库的整体性。MySQL 5.6采用了类似的实现方式,并将其称为Binary Log Group Commit(BLGC)。
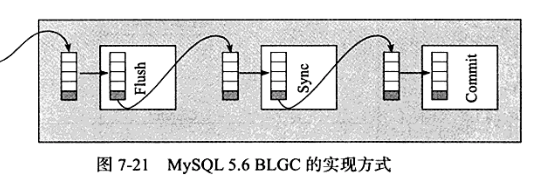
在MySQL数据库上层进行提交时首先按顺序将其放入一个队列中,队列中的第一个事务称为leader,其他事务称为follower,leader控制着follower的行为。
BLGC的步骤分为以下三个阶段:
❑ Flush阶段,将每个事务的二进制日志写入内存中。
❑ Sync阶段,将内存中的二进制日志刷新到磁盘,若队列中有多个事务,那么仅一次fsync操作就完成了二进制日志的写入,这就是BLGC。
❑ Commit阶段,leader根据顺序调用存储引擎层事务的提交,InnoDB存储引擎本就支持group commit,因此修复了原先由于锁prepare_commit_mutex导致group commit失效的问题。
当有一组事务在进行Commit阶段时,其他新事物可以进行Flush阶段,从而使group commit不断生效。 当然group commit的效果由队列中事务的数量决定,若每次队列中仅有一个事务,那么可能效果和之前差不多,甚至会更差。但当提交的事务越多时,group commit的效果越明显,数据库性能的提升也就越大。
参数binlog_max_flush_queue_time用来控制Flush阶段中等待的时间,即使之前的一组事务完成提交,当前一组的事务也不马上进入Sync阶段,而是至少需要等待一段时间。这样做的好处是group commit的事务数量更多,然而这也可能会导致事务的响应时间变慢。该参数的默认值为0,且推荐设置依然为0。除非用户的MySQL数据库系统中有着大量的连接(如100个连接),并且不断地在进行事务的写入或更新操作。
7.3 事务控制语句
略..
7.4 隐式提交的SQL语句
略..
7.5 对于事务操作的统计
由于InnoDB存储引擎是支持事务的,因此InnoDB存储引擎的应用需要在考虑每秒请求数(Question Per Second,QPS)的同时,应该关注每秒事务处理的能力(Transaction Per Second,TPS)。
计算TPS的方法是(com_commit+com_rollback)/time。但是利用这种方法进行计算的前提是:所有的事务必须都是显式提交的,如果存在隐式地提交和回滚(默认autocommit=1),不会计算到com_commit和com_rollback变量中。如:
SHOW GLOBAL STATUS LIKE'com_commit'
->结果: 6
MySQL数据库中另外还有两个参数handler_commit和handler_rollback用于事务的统计操作。但是我注意到这两个参数在MySQL 5.1中可以很好地用来统计InnoDB存储引擎显式和隐式的事务提交操作,但是在InnoDB Plugin中这两个参数的表现有些"怪异",并不能很好地统计事务的次数。
所以,如果用户的程序都是显式控制事务的提交和回滚,那么可以通过com_commit和com_rollback进行统计。如果不是,那么情况就显得有些复杂。
7.6 事务的隔离级别
四个隔离级别:
- read uncommitted
- read commited
- repeatable read
- serializable
InnoDB的默认隔离级别是repeatable read,但是与标准sql不同的是,innodb在repeatable read级别下,使用next-key lock锁的算法,因此避免幻读的产生。所以,innodb在repeatable read的事务隔离级别下已经能完全保证事务的隔离性要求,即达到sql标准的serializable隔离级别。
隔离级别越低,事务请求的锁越少,或者保持锁的时间就越短。这也是为什么大多数数据库系统默认的事务隔离级别是read committed。
在serializable的事务隔离级别,InnoDB存储引擎会对每个select语句后自动加上lock in share mode,即给每个读取操作加一个共享锁。因此这个事务隔离级别下,读占用锁了,一致性的非锁定读不再予以支持。因为InnoDB存储引擎在repeatable read隔离级别下就可以达到3°的隔离,所以一般不在本地事务中使用serialiable的隔离级别,serialiable的隔离级别主要用于InnoDB存储引擎的分布式事务。
7.7 分布式事务
Innodb支持XA事务,通过XA事务可以来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源参与一个全局的事务中。事务资源通常是关系型数据库系统,但也可以使其他类型的资源。全局事务要求在其中所有参与的事务要么都提交,要么都回滚,这对于事务原有的ACID要求又有了提高,另外,在使用分布式事务时,innoDB的事务隔离级别必须设置为serializable。
分布式事务由一个或者多个资源管理器、一个事务管理器以及一个应用程序组成。
- 资源管理器:提供访问事务资源的方法.通常一个数据库就是一个资源管理器。
- 事务管理器:协调参与全局事务中的各个事务.需要和参与全局事务中的所有资源管理器进行通信。
- 应用程序:定义事务的边界,指定全局事务中的操作。
7.7.1 MySQL数据库分布式事务
InnoDB存储引擎提供了对XA事务的支持,并通过XA事务来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的ACID要求又有了提高。另外,在使用分布式事务时,InnoDB存储引擎的事务隔离级别必须设置为SERIALIZABLE。
分布式事务使用两段式提交(two-phase commit)的方式。在第一阶段,所有参与全局事务的节点都开始准备(PREPARE),告诉事务管理器它们准备好提交了。在第二阶段,事务管理器告诉资源管理器执行ROLLBACK还是COMMIT。如果任何一个节点显示不能提交,则所有的节点都被告知需要回滚。可见与本地事务不同的是,分布式事务需要多一次的PREPARE操作,待收到所有节点的同意信息后,再进行COMMIT或是ROLLBACK操作。
7.7.2 内部XA事务
之前讨论的分布式事务是外部事务,即资源管理器是MySQL数据库本身。在MySQL数据库中还存在另外一种分布式事务,其在存储引擎与插件之间,又或者在存储引擎与存储引擎之间,称之为内部XA事务。
在事务提交时,先写二进制日志,再写InnoDB存储引擎的重做日志。对上述两个操作的要求也是原子的,即二进制日志和重做日志必须同时写入。若二进制日志先写了,而在写入InnoDB存储引擎时发生了宕机,那么slave可能会接收到master传过去的二进制日志并执行,最终导致了主从不一致的情况。如图7-23所示。
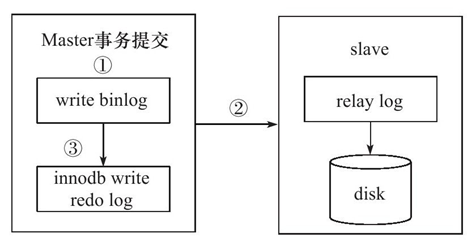
在图7-23中,如果执行完①、②后在步骤③之前MySQL数据库发生了宕机,则会发生主从不一致的情况。
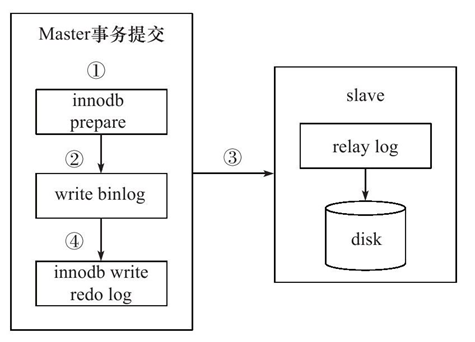
为了解决这个问题,MySQL数据库在binlog与InnoDB存储引擎之间采用XA事务。当事务提交时,InnoDB存储引擎会先做一个PREPARE操作,将事务的xid写入,接着进行二进制日志的写入,如图7-24所示。如果在InnoDB存储引擎提交前,MySQL数据库宕机了,那么MySQL数据库在重启后会先检查准备的UXID事务是否已经提交,若没有,则在存储引擎层再进行一次提交操作。
7.8 不好的事务习惯
7.8.1 在循环中提交
每一次提交都要写一次重做日志,
7.8.2 使用自动提交
程序端进行事务的开始和结束。
7.8.3 使用自动回滚
InnoDB存储引擎支持通过定义一个HANDLER来进行自动事务的回滚操作,如在一个存储过程中发生了错误会自动对其进行回滚操作。
7.9 长事务
长事务(Long-Lived Transactions),顾名思义,就是执行时间较长的事务。
比如,对于银行系统的数据库,每过一个阶段可能需要更新对应账户的利息。如果对应账号的数量非常大,例如对有1亿用户的表account,需要执行下列语句:
UPDATE account
SET account_total=account_total+(1+interest_rate)
这时这个事务可能需要非常长的时间来完成。
解决方案
因此,对于长事务的问题,有时可以通过转化为小批量(mini batch)的事务来进行处理。当事务发生错误时,只需要回滚一部分数据,然后接着上次已完成的事务继续进行。
7.10 小结
在这一章中我们了解了InnoDB存储引擎管理事务的许多方面。了解了事务如何工作以及如何使用事务,这在任何数据库中对于正确实现应用都是必要的。此外,事务是数据库区别于文件系统的一个关键特性。
事务必须遵循ACID特性,即Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)和Durability(持久性)。隔离性通过第6章介绍过的锁来完成;原子性、一致性、隔离性通过redo和undo来完成。通过对redo和undo的了解,可以进一步明白事务的工作原理以及如何更好地使用事务。接着我们讲到了InnoDB存储引擎支持的四个事务隔离级别,知道了InnoDB存储引擎的默认事务隔离级别是REPEATABLE READ的,不同于SQL标准对于事务隔离级别的要求,InnoDB存储引擎在REPEATABLE READ隔离级别下就可以达到3°的隔离要求。
本章最后讲解了操作事务的SQL语句以及怎样在应用程序中正确使用事务。在默认配置下,MySQL数据库总是自动提交的——如果不知道这点,可能会带来非常不好的结果。此外,在应用程序中,最好的做法是把事务的START TRANSACTION、COMMIT、ROLLBACK操作交给程序端来完成,而不是在存储过程内完成。在完整了解了InnoDB存储引擎事务机制后,相信你可以开发出一个很好的企业级MySQL InnoDB数据库应用了。