Redis在最新的5.0.0版本中也加入了消息队列的功能,这就是Stream。
8.1 Stream简介

图8-1 Redis Stream结构图
命令: xadd mystream1 * name hb age 20
mystream1为Stream的名称;
*代表由Redis自行生成消息ID;
name、age为该消息的field;
hb、20则为对应的field的值。
每个消息都由以下两部分组成。
·每个消息有唯一的消息ID,消息ID严格递增。
·消息内容由多个field-value对组成。
当消费者不归属于任何消费组时,该消费者可以消费消息队列中的任何消息。
消费组特点。
·每个消费组通过组名称唯一标识,每个消费组都可以消费该消息队列的全部消息,多个消费组之间相互独立。
·每个消费组可以有多个消费者,消费者通过名称唯一标识,消费者之间的关系是竞争关系,也就是说一个消息只能由该组的一个成员消费。
·组内成员消费消息后需要确认,每个消息组都有一个待确认消息队列(pending entry list,pel),用以维护该消费组已经消费但没有确认的消息。
·消费组中的每个成员也有一个待确认消息队列,维护着该消费者已经消费尚未确认的消息。
RedisStream的底层实现主要使用了listpack以及Rax树。
8.1.1 Stream底层结构listpack
Redis listpack可用于存储字符串或者整型。图8-2为listpack的整体结构图。
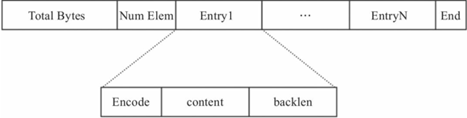
图8-2 listpack结构图
listpack由4部分组成:Total Bytes、Num Elem、Entry以及End,
下面介绍各部分的具体含义。
1)Total Bytes为整个listpack的空间大小,占用4个字节,每个listpack最多占用4294967295Bytes。
2)Num Elem为listpack中的元素个数,即Entry的个数,占用2个字节,值得注意的是,这并不意味着listpack最多只能存放65535个Entry,当Entry个数大于等于65535时,Num Elem被设置为65535,此时如果需要获取元素个数,需要遍历整个listpack。
3)End为listpack结束标志,占用1个字节,内容为0xFF。
4)Entry为每个具体的元素。其内容可以为字符串或者整型,每个Entry由3部分组成,每部分的具体含义如下。Encode为该元素的编码方式,占用1个字节,之后是内容字段content,二者紧密相连。表8-1详细介绍了Encode字段。
表8-1 listpack Encode

backlen记录了这个Entry的长度(Encode+content),注意并不包括backlen自身的长度,占用的字节数小于等于5。backlen所占用的每个字节的第一个bit用于标识;0代表结束,1代表尚未结束,每个字节只有7 bit有效。值得一提的是,backlen主要用于从后向前遍历,当我们需要找到当前元素的上一个元素时,我们可以从后向前依次查找每个字节,找到上一个Entry的backlen字段的结束标识,进而可以计算出上一个元素的长度。例如backlen为0000000110001000,代表该元素的长度为00000010001000,即136字节。通过计算即可算出上一个元素的首地址(entry的首地址)。值得注意的是,在整型存储中,并不实际存储负数,而是将负数转换为正数进行存储。例如,在13位整型存储中,存储范围为[0,8191],其中[0,4095]对应非负的[0,4095](当然,[0,127]将会采用7位无符号整型存储),而[4096,8191]则对应[-4096,-1]。
8.1.2 Stream底层结构Rax简介
1.概要
前缀树是字符串查找时,经常使用的一种数据结构,能够在一个字符串集合中快速查找到某个字符串,下面给出一个简单示例,如图8-3所示。

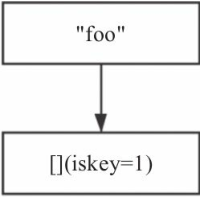
图8-3 前缀树示例 图8-4 只有一个压缩节点的Rax
Rax树通过节点压缩节省空间,只有一个key(foo)的Rax树如图8-4所示,其中中括号代表非压缩节点,双引号代表压缩节点(压缩节点,非压缩节点下文将详细介绍),(iskey=1)代表该节点存储了一个key,
在上述节点的基础上插入key(foobar)后,Rax树结构如图8-5所示。
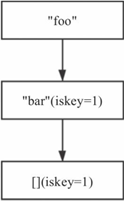
图8-5 包含两个压缩节点的Rax
含有两个key(foobar,footer)的Rax树结构图如图8-6所示。
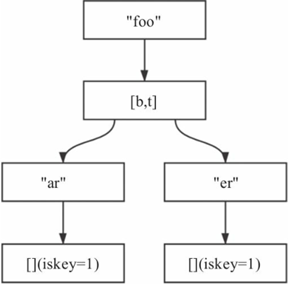
图8-6 含有foobar、footer两个key的Rax
对于非压缩节点,其内部字符是按照字典序排序的,例如上述第二个节点,含有2个字符b、t,二者是按照字典序排列的。
2.关键结构体介绍
1)rax结构代表一个Rax树,它包含3个字段,指向头节点的指针,元素个数(即key的个数)以及节点个数。
typedef struct rax {
raxNode *head;
uint64_t numele;
uint64_t numnodes;
} rax;
2)raxNode代表Rax树中的一个节点,它的定义如下:
typedef struct raxNode {
uint32_t iskey:1; /*当前节点是否包含一个key,占用1bit*/
uint32_t isnull:1; /* 当前key对应的value是否为空,占用1bit */
uint32_t iscompr:1; /* 当前节点是否为压缩节点,占用1bit*/
uint32_t size:29; /* 为压缩节点压缩的字符串长度或者非压缩节点的子节点个
数,占用29bit; */
unsigned char data[]; // 中包含填充字段,同时存储了当前节点包含的字符串以及子
节点的指针、key对应的value指针。
} raxNode;
raxNode分为2类,压缩节点和非压缩节点,下面分别进行介绍。
1)压缩节点 。我们假设该节点存储的内容为字符串ABC,其结构图如图8-7所示。

图8-7 压缩节点示例图
·iskey为1且isnull为0时,value-ptr存在,否则value-ptr不存在;
·iscompr为1代表当前节点是压缩节点,size为3代表存储了3个字符;
·紧随size的是该节点存储的字符串,根据字符串的长度确定是否需要填充字段(填充必要的字节,使得后面的指针地址放到合适的位置上);
·由于是压缩字段,故而只有最后一个字符有子节点。(c-ptr)
2)非压缩节点 。我们假设其内容为XY,结构图如图8-8所示。

图8-8 非压缩节点示例图
与压缩节点的不同点在于,每个字符都有一个子节点,值得一提的是,字符个数小于2时,都是非压缩节点。为了实现Rax树的遍历,Redis提供了raxStack及raxIterator两种结构,下面逐一介绍。
①raxStack结构用于存储从根节点到当前节点的路径,具体定义如下:
#define RAX_STACK_STATIC_ITEMS 32
typedef struct raxStack {
void **stack; /*用于记录路径,该指针可能指向static_items(路径较短时)或者堆空间内存; */
size_t items, maxitems; /* 代表stack指向的空间的已用空间以及最大空间 */
void *static_items[RAX_STACK_STATIC_ITEMS];
int oom; /* 代表当前栈是否出现过内存溢出. */
} raxStack;
②raxIterator用于遍历Rax树中所有的key,该结构的定义如下:
typedef struct raxIterator {
int flags; //当前迭代器标志位,目前有3种,
RAX_ITER_JUST_SEEKED代表当前迭代器指向的元素是刚刚搜索过的,当需要从迭代器中获取元素时,直接返回当前元素并清空该标志位即可;
RAX_ITER_EOF代表当前迭代器已经遍历到rax树的最后一个节点;
RAX_ITER_SAFE代表当前迭代器为安全迭代器,可以进行写操作。
rax *rt; /* 当前迭代器对应的rax */
unsigned char *key; /*存储了当前迭代器遍历到的key,该指针指向
key_static_string或者从堆中申请的内存。*/
void *data; /* 当前key关联的value值 */
size_t key_len; /* key指向的空间的已用空间 */
size_t key_max; /*key 最大空间 */
unsigned char key_static_string[RAX_ITER_STATIC_LEN]; //默认存储空间,当key比较大时,会使用堆空间内存。
raxNode *node; /* 当前key所在的raxNode */
raxStack stack; /* 记录了从根节点到当前节点的路径,用于raxNode的向上遍历。*/
raxNodeCallback node_cb; /* 为节点的回调函数,通常为空*/
} raxIterator;
8.1.3 Stream结构
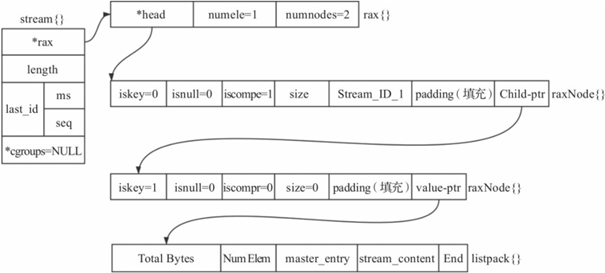
图8-9 Stream结构示例
每个消息流都包含一个Rax结构。以消息ID为key、listpack结构为value存储在Rax结构中。每个消息的具体信息存储在这个listpack中。以下亮点是值得注意的。
1)每个listpack都有一个master entry,该结构中存储了创建这个listpack时待插入消息的所有field,这主要是考虑同一个消息流,消息内容通常具有相似性,如果后续消息的field与master entry内容相同,则不需要再存储其field。
2)每个listpack中可能存储多条消息。
消息存储
(1)消息ID
streamID定义如下,以每个消息创建时的时间(1970年1月1号至今的毫秒数)以及序号组成,共128位。
typedef struct streamID {
uint64_t ms; /* Unix time in milliseconds. */
uint64_t seq; /* Sequence number. */
} streamID;
(2)消息存储的格式
Stream的消息内容存储在listpack中, listpack用于存储字符串或者整型数据,listpack中的单个元素称为entry,下文介绍的消息存储格式的每个字段都是一个entry,并不是将整个消息作为字符串储存的。值得注意的是,每个listpack会存储多个消息,具体存储的消息个数是由stream-node-max-bytes(listpack节点最大占用的内存数,默认4096)和stream-node-max-entries(每个listpack最大存储的元素个数,默认100)决定的。
·每个消息会占用多个listpack entry。
·每个listpack会存储多个消息。
每个listpack在创建时,会构造该节点的master entry(根据第一个插入的消息构建),其结构如图8-10所示。

图8-10 listpack master entry结构
·count 为当前listpack中的所有未删除的消息个数。
·deleted 为当前listpack中所有已经删除的消息个数。
·num-fields 为下面的field的个数。
·field-1,…,filed-N 为当前listpack中第一个插入的消息的所有field
域。
·0 为标识位,在从后向前遍历该listpack的所有消息时使用。
处省略了listpack每个元素存储时的encoding以及backlen字段;
消息的field域与master entry的域完全相同
存储一个消息时,如果该消息的field域与master entry的域完全相同,则不需要再次存储field域,此时其消息存储如图8-11所示。

图8-11 消息存储
·flags字段为消息标志位,STREAM_ITEM_FLAG_NONE代表无特殊标识, STREAM_ITEM_FLAG_DELETED代表该消息已经被删除, STREAM_ITEM_FLAG_SAMEFIELDS代表该消息的field域与master entry完全相同。
·streamID.ms以及streamID.seq为该消息ID减去master entry id之后的值。
·value域存储了该消息的每个field域对应的内容。
·lp-count为该消息占用listpack的元素个数,也就是3+N。
消息的field域与master entry不完全相同
如果该消息的field域与master entry不完全相同,此时消息的存储如图8-12所示。
·flags为消息标志位,与上面一致;
·streamID.ms,streamID.seq为该消息ID减去master entry id之后的值;
·num-fields为该消息field域的个数;
·field-value存储了消息的域值对,也就是消息的具体内容;
·lp-count为该消息占用的listpack的元素个数,也就是4+2N。

图8-12 消息存储
2.关键结构体介绍
- stream。
typedef struct stream {
rax *rax; /* 存储生产者生产的具体消息,以消息ID为键,消息内容为值存储在rax中,值得注意的是,rax中的一个节点可能存储多个消息*/
uint64_t length; /*当前stream中的消息个数(不包括已经删除的消息)。*/
streamID last_id; /* 当前stream中最后插入的消息的ID,stream空时,设置为0。. */
rax *cgroups; /* 存储了当前stream相关的消费组,rax中: name -> streamCG */
} stream;
- 消费组。
每个Stream会有多个消费组,每个消费组通过组名称进行唯一标识,同时关联一个streamCG结构,该结构定义如下:
typedef struct streamCG {
streamID last_id; // 该消费组已经确认的最后一个消息的ID
rax *pel; // 该消费组尚未确认的消息,消息ID为键,streamNACK(一个尚未确认的消息)为值;
rax *consumers; // 该消费组中所有的消费者,消费者的名称为键,streamConsumer(代表一个消费者)为值。
} streamCG;
- 消费者。
每个消费者通过streamConsumer唯一标识,该结构如下:
typedef struct streamConsumer {
mstime_t seen_time; /* 该消费者最后一次活跃的时间; */
sds name; /* C消费者的名称*/
rax *pel; /* 消费者尚未确认的消息,以消息ID为键,streamNACK为值。 */
} streamConsumer;
- 未确认消息。
未确认消息(streamNACK)维护了消费组或者消费者尚未确认的消息,值得注意的是,消费组中的pel的元素与每个消费者的pel中的元素是共享的,即该消费组消费了某个消息,这个消息会同时放到消费组以及该消费者的pel队列中,并且二者是同一个streamNACK结构。
/* Pending (yet not acknowledged) message in a consumer group. */
typedef struct streamNACK {
mstime_t delivery_time; /* 该消息最后发送给消费方的时间 */
uint64_t delivery_count; /*为该消息已经发送的次数(组内的成员可以通过xclaim命令获取某个消息的处理权,该消息已经分给组内另一个消费者但其并没有确认该消息)。*/
streamConsumer *consumer; /* 该消息当前归属的消费者 */
} streamNACK;
5)迭代器。为了遍历stream中的消息:
typedef struct streamIterator {
stream *stream; /*当前迭代器正在遍历的消息流 */
streamID master_id; /* 消息内容实际存储在listpack中,每个listpack都有一个masterentry(也就是第一个插入的消息),master_id为该消息id */
uint64_t master_fields_count; /* master entry中field域的个数. */
unsigned char *master_fields_start; /*master entry field域存储的首地址*/
unsigned char *master_fields_ptr; /*当listpack中消息的field域与master entry的field域完全相同时,该消息会复用master entry的field域,在我们遍历该消息时,需要记录
当前所在的field域的具体位置,master_fields_ptr就是实现这个功能的。 */
int entry_flags; /* 当前遍历的消息的标志位 */
int rev; /*当前迭代器的方向 */
uint64_t start_key[2]; /* 该迭代器处理的消息ID的范围 */
uint64_t end_key[2]; /* End key as 128 bit big endian. */
raxIterator ri; /*rax迭代器,用于遍历rax中所有的key. */
unsigned char *lp; /* 当前listpack指针*/
unsigned char *lp_ele; /* 当前正在遍历的listpack中的元素, cursor. */
unsigned char *lp_flags; /* Current entry flags pointer.指向当前消息的flag域 */
//用于从listpack读取数据时的缓存
unsigned char field_buf[LP_INTBUF_SIZE];
unsigned char value_buf[LP_INTBUF_SIZE];
} streamIterator;
8.2 Stream底层结构listpack的实现
结构查询效率低,并且只适合于末尾增删。考虑到消息流中,通常只需要向其末尾增加消息,故而可以采用该结构;
8.2.1 初始化

图8-13 listpack初始化
/* Create a new, empty listpack.
* On success the new listpack is returned, otherwise an error is returned. */
unsigned char *lpNew(void) {
// LP_HDR_SIZE = 6,为listpack的头部
unsigned char *lp = lp_malloc(LP_HDR_SIZE+1); // 申请空间
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF; // LP_EOF = 0xFF
return lp;
}
8.2.2 增删改操作
listpack提供了2种添加元素的方式:
一种是在任意位置插入元素,一种是在末尾插入元素。在末尾插入元素的底层实现通过调用任意位置插入元素进行,具体实现为lpInsert函数。
listpack的删除操作被转换为用空元素替换的操作。
listpack的替换操作(即改操作)的底层实现也是通过lpInsrt函数实现的。
lpInsert 函数定义:
unsigned char *lpInsert(unsigned char *lp, unsigned char *ele, uint32_t size, unsigned char *p, int where, unsigned char **newp);
·lp 为当前待操作的listpack;
·ele 为待插入的新元素或者待替换的新元素,ele为空时,也就是删除操作;
·size 为ele的长度;
·p 为待插入的位置或者带替换的元素位置;
·where 有LP_BEFORE(前插)、LP_AFTER(后插)、LP_REPLACE(替换);
·*newp 用于返回插入的元素、替换的元素、删除元素的下一个元素。
该函数返回null或者插入的元素,替换的元素,删除元素的下一个元素。
删除或者替换的主要过程如下:
1)计算需要插入的新元素或者替换旧元素的新元素需要的空间;
2)计算进行插入或者替换后整个listpack所需的空间,通过realloc申请空间;
3)调整新的listpack中的老的元素的位置,为待操作元素预留空间;
4)释放旧的listpack;
5)在新的listpack中进行插入或替换的操作;
6)更新新的listpack结构头部的统计信息。
8.2.3 遍历操作
核心思想是利用每个entry的encode或者backlen字段获取当前entry的长度;
unsigned char *lpFirst(unsigned char *lp); //获取第一个元素位置
unsigned char *lpLast(unsigned char *lp); //获取最后一个元素位置
unsigned char *lpNext(unsigned char *lp, unsigned char *p); //下一个元素位置
unsigned char *lpPrev(unsigned char *lp, unsigned char *p); //上一个元素位置
例如:
unsigned char *lpFirst(unsigned char *lp) {
lp += LP_HDR_SIZE; /* Skip the header. */ LP=+6
if (lp[0] == LP_EOF) return NULL; //0xFF
return lp;
}
此处获取的仅仅是某个entry首地址的指针,如果要读取当前元素则需要使用下 lpGet接口;
8.2.4 读取元素
lpGet用于获取p指向的Listpack中真正存储的元素:
①当元素采用字符串编码时,返回字符串的第一个元素位置,count为元素个数;
②当采用整型编码时,若intbuf不为空,则将整型数据转换为字符串存储在intbuf中,count为元素个数,并返回intbuf。若intbuf为空,直接将数据存储在count中,返回null。
unsigned char *lpGet(unsigned char *p, int64_t *count, unsigned char *intbuf)
lpGet的实现较为简单,主要是利用了每个entry的encode字段(p[0];
8.3 Stream底层结构Rax的实现
Stream的消息内容存储在listpack中,但是如果将所有消息都存储在一个listpack中,则会存在效率问题。例如,查询某个消息时,需要遍历整个listpack;插入消息时,需要重新申请一块很大的空间。为了解决这些问题,Redis Stream通过Rax组织这些listpack ;
8.3.1 初始化
/* 分配一个新的rax并返回其指针。在内存不足时,函数*返回NULL. */
rax *raxNew(void) {
rax *rax = rax_malloc(sizeof(*rax)); //申请空间
if (rax == NULL) return NULL;
rax->numele = 0; //当前元素个数为0
rax->numnodes = 1; //当前节点个数为1
rax->head = raxNewNode(0,0); //构造头节点
if (rax->head == NULL) {
rax_free(rax);
return NULL;
} else {
return rax;
}
}
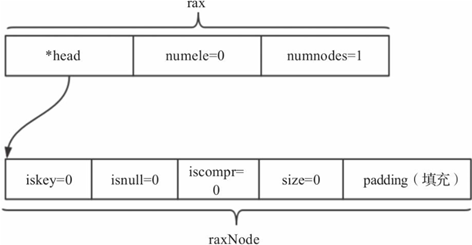
图8-14 Rax初始化
8.3.2 查找元素
/* 获取key对应的value值, */
//在rax中查找长度为len的字符串s(s为rax中的一个key), 找到返回该key对应的value
void *raxFind(rax *rax, unsigned char *s, size_t len) {
raxNode *h;
int splitpos = 0;
size_t i = raxLowWalk(rax,s,len,&h,NULL,&splitpos,NULL);
if (i != len || (h->iscompr && splitpos != 0) || !h->iskey)
return raxNotFound; //没有找到这个key
return raxGetData(h); //查到key, 将key对应的value返回
}
raxLowWalk为查找key的核心函数 ;
static inline size_t raxLowWalk(rax *rax, unsigned char *s, size_t len, raxNode **stopnode, raxNode ***plink, int *splitpos, raxStack *ts) ;
·rax 为待查找的Rax;
·s 为待查找的key;
·len 为s的长度;
·*stopnode 为 找过程中的终止节点,也就意味着,当rax查找到该节点时,待查找的key已经匹配完成,或者当前节点无法与带查找的key匹配;
·*plink 用于记录父节点中指向*stopnode的指针的位置,当*stopnode变化时,也需要修改父节点指向该节点的指针;
·*splitpos 用于记录压缩节点的匹配位置;
·当ts 不为空时,会将查找该key的路径写入该变量。
该函数返回s的匹配长度,当s!=len时,表示未查找到该key;当s==len时,需要检验*stopnode是否为key,并且当*stopnode为压缩节点时,还需要检查splitpos是否为0(可能匹配到某个压缩节点中间的某个元素)。
raxLowWalk函数的执行过程可以分为如下几步。
1)初始化变量。
2)从rax根节点开始查找,知道当前待查找节点无子节点或者s查找完毕。对于每个节点来说,如果为压缩节点,则需要与s中的字符完全匹配。如果为非压缩节点,则查找与当前待匹配字符相同的字符。
3)如果当前待匹配节点能够与s匹配,则移动位置到其子节点,继续匹配。
raxNode *h = rax->head; // 从根节点开始匹配
raxNode **parentlink = &rax->head;
size_t i = 0; /*当前待匹配字符位置. */
size_t j = 0; /* 当前匹配的节点的位置*/
while(h->size && i < len) { // 当前节点有子节点且尚未走到s字符串的末尾
unsigned char *v = h->data;
if (h->iscompr) { // 压缩节点是否能够完全匹配s字符串
for (j = 0; j < h->size && i < len; j++, i++) {
if (v[j] != s[i]) break;
}
if (j != h->size) break; // 当前压缩节点不能完全匹配或者s已经到达末尾
} else {
/* 非压缩节点遍历节点元素, 查找与当前字符匹配的位置*/
for (j = 0; j < h->size; j++) {
if (v[j] == s[i]) break;
}
if (j == h->size) break; // 未在非压缩节点找到匹配的字符
i++; // 非压缩节点可以匹配, 移动到s的下一个字符
}
// 当前节点能够匹配s
if (ts) raxStackPush(ts,h); /* Save stack of parent nodes. */
raxNode **children = raxNodeFirstChildPtr(h);
if (h->iscompr) j = 0; /* Compressed node only child is at index 0. */
memcpy(&h,children+j,sizeof(h)); // 将当前节点移动到其第 j个子节点
parentlink = children+j;
j = 0;
}
if (stopnode) *stopnode = h;
if (plink) *plink = parentlink;
if (splitpos && h->iscompr) *splitpos = j;
return i;
8.3.3 添加元素
对于已存在的key,rax提供了2种方案,覆盖或者不覆盖原有的value,对应的接口分别为raxInsert、raxTryInsert,两个接口的定义如下:
/* 覆盖插入*/
int raxInsert(rax *rax, unsigned char *s, size_t len, void *data, void **old) {
return raxGenericInsert(rax,s,len,data,old,1);
}
/*非覆盖插入函数:如果存在具有相同键的元素,则不更新值,并且返回0。 */
int raxTryInsert(rax *rax, unsigned char *s, size_t len, void *data, void **old) {
return raxGenericInsert(rax,s,len,data,old,0);
}
raxGenericInsert 函数
函数参数与raxInsert基本一致,只是增加overwrite用于标识key存在时是否覆盖;
1.查找key是否存在
size_t i;
int j = 0; /* 分割位置。如果raxLowWalk()在压缩节点中停止,则索引" j"表示我们在压缩节点中停止的字符,即拆分该节点以进行插入的位置 */
raxNode *h, **parentlink;
i = raxLowWalk(rax,s,len,&h,&parentlink,&j,NULL);
2.找到key
根据raxLowWalk的返回值,如果当前key已经存在,则直接对该节点进行操作 ;
if (i == len && (!h->iscompr || j == 0 /* not in the middle if j is 0 */)) {
/*查看之前是否存储value,没有则申请空间 . */
if (!h->iskey || (h->isnull && overwrite)) {
h = raxReallocForData(h,data);
if (h) memcpy(parentlink,&h,sizeof(h));
}
if (h == NULL) {
errno = ENOMEM;
return 0;
}
/* 更新存在的key. */
if (h->iskey) {
if (old) *old = raxGetData(h);
if (overwrite) raxSetData(h,data);
errno = 0;
return 0; /* Element already exists. */
}
/*否则,将节点设置为键 set h->iskey. */
raxSetData(h,data);
rax->numele++;
return 1; /* Element inserted. */
}
3.key不存在
1)在查找key的过程中,如果最后停留在某个压缩节点上,此时需要对该压缩节点进行拆分,具体拆分情况分为以下几种,以图8-15为例。
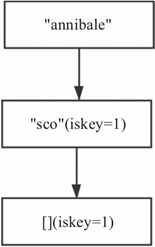
图8-15 Rax节点拆分
·插入key"ciao",需要将"annibale"节点拆分为2部分:非压缩节点,压缩节点。
·插入key"ago",需要将"annibale"节点拆分为3部分:非压缩节点,非压缩节点,压缩节点。
·插入key"annienter",需要将"annibale"节点拆分3部分:压缩节点,非压缩节点,压缩节点。
·插入key"annibaie",需要将"annibale"拆成3部分:压缩节点,非压缩节点,非压缩节点。
·插入key"annibali",需要将"annibale"拆成2部分:压缩节点,非压缩节点。
·插入key"a",将"annibale"拆分成2部分:非压缩节点,压缩节点。
·插入key"anni",将"annibale"拆分成2个压缩节点。
总体而言分为2类:
新插入的key是当前节点的一部分: 将压缩节点进行拆分后直接设置新的key-value即可
新插入的key和压缩节点的某个位置不匹配: 对 需要在拆分后的相应位置的非压缩节点中插入新key的相应不匹配字符,之后将新key的剩余部分插入到这个非压缩节点的子节点中。
2)如果查找key完成后,不匹配节点为某个非压缩节点,或者某个压缩节点的某个字符不匹配,进行节点拆分后导致的不匹配位置为拆分后创建的非压缩节点,此时仅仅需要将当前待匹配字符插入到这个非压缩节点上(注意字符按照字典序排列),并为其创建子节点。之后,将剩余字符放入新建的子节点中即可(如果字符长度过长,需要进行分割)。
8.3.4 删除元素
Rax的删除操作主要有3个接口,可以删除rax中的某个key,或者释放整个rax,在释放rax时,还可以设置释放回调函数,在释放rax的每个key时,都会调用这个回调函数;
// 在rax中删除长度为len的s(s代表待删除的key), *old用于返回该key对应的value
int raxRemove(rax *rax, unsigned char *s, size_t len, void **old);
// 释放rax
void raxFree(rax *rax);
// 释放rax,释放每个key时,都会调用free_callback函数
void raxFreeWithCallback(rax *rax, void (*free_callback)(void*));
rax的释放操作,采用的是深度优先算法;
raxRemove函数
当删除rax中的某个key-value对时,首先查找key是否存在,不存在则直接返回,存在则需要进行删除操作。
raxNode *h;
raxStack ts;
raxStackInit(&ts);
int splitpos = 0;
size_t i = raxLowWalk(rax,s,len,&h,NULL,&splitpos,&ts);
if (i != len || (h->iscompr && splitpos != 0) || !h->iskey) {
raxStackFree(&ts); // 没有找到需要删除的key
return 0;
}
如果key存在,则需要进行删除操作,删除操作完成后,Rax树可能需要进行压缩。具体可以分为下面2种情况,此处所说的压缩是指将某个节点与其子节点压缩成一个节点,叶子节点没有子节点,不能进行压缩。
1)某个节点只有一个子节点,该子节点之前是key,经删除操作后不再是key,此时可以将该节点与其子节点压缩,如图8-16所示,删除foo后,可以将Rax进行压缩,压缩后为"foobar"->[](iskey=1)。
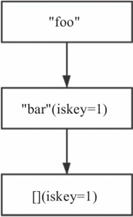
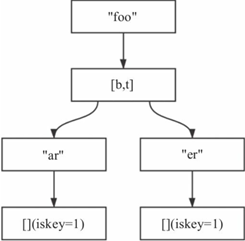
图8-16 Rax节点压缩 图8-17 Rax节点压缩
2)某个节点有两个子节点,经过删除操作后,只剩下一个子节点,如果这个子节点不是key,则可以将该节点与这个子节点压缩。如图8-17所示,删除foobar后,可以将Rax树进行压缩,压缩成"footer"->[](iskey=1)。
删除操作具体可以分为2个阶段,删除阶段以及压缩阶段。例如,图8-17删除"foobar"时,需要从下向上,删除可以删除的节点。图8-16在删除"foo"时,则不需要删除节点。这部分的实现逻辑主要是利用查找key时记录的匹配路径,依次向上直到无法删除为止。
if (h->size == 0) {
raxNode *child = NULL;
while(h != rax->head) {
child = h;
rax_free(child);
rax->numnodes--;
h = raxStackPop(&ts);
/* 如果节点为key或者子节点个数不为1,则无法继续删除 */
if (h->iskey || (!h->iscompr && h->size != 1)) break;
}
if (child) {
raxNode *new = raxRemoveChild(h,child);
if (new != h) {
raxNode *parent = raxStackPeek(&ts);
raxNode **parentlink;
if (parent == NULL) {
parentlink = &rax->head;
} else {
parentlink = raxFindParentLink(parent,h);
}
memcpy(parentlink,&new,sizeof(new));
}
/* 删除后查看是否可以尝试压缩 node has just a single child and is not a key, */
if (new->size == 1 && new->iskey == 0) {
trycompress = 1;
h = new;
}
}
} else if (h->size == 1) {
/* 可以尝试进行压缩. */
trycompress = 1;
}
压缩过程可以细化为2步。
①找到可以进行压缩的第一个元素,之后将所有可进行压缩的节点进行压缩。由于raxRowWalk函数已经记录了查找key的过程,压缩时只需从记录栈中不断弹出元素,即可找到可进行压缩的第一个元素,过程如下:
raxNode *parent;
while(1) {
parent = raxStackPop(&ts);
if (!parent || parent->iskey ||
(!parent->iscompr && parent->size != 1)) break;
h = parent; //可以进行压缩
}
raxNode *start = h; /* 可以进行压缩的第一个节点. */
②找到第一个可压缩节点后,进行数据压缩。由于可压缩的节点都只有一个子节点,压缩过程只需要读取每个节点的内容,创建新的节点,并填充新节点的内容即可,此处省略。
8.3.5 遍历元素
Redis中实现的迭代器为双向迭代器,可以向前,也可以向后,顺序是按照key的字典序排列的。通过rax的结构图可以看出,如果某个节点为key,则其子节点的key按照字典序比该节点的key大。另外,如果当前节点为非压缩节点,则其最左侧节点的key是其所有子节点的key中最小的。迭代器的主要接口有:
void raxStart(raxIterator *it, rax *rt);
int raxSeek(raxIterator *it, const char *op, unsigned char *ele, size_t len);
int raxNext(raxIterator *it);
int raxPrev(raxIterator *it);
void raxStop(raxIterator *it);
int raxEOF(raxIterator *it);
1.raxStart
raxStart用于初始化raxIterator结构;
void raxStart(raxIterator *it, rax *rt) {
it->flags = RAX_ITER_EOF; /*默认值为迭代结束. */
it->rt = rt;
it->key_len = 0;
it->key = it->key_static_string;
it->key_max = RAX_ITER_STATIC_LEN;
it->data = NULL;
it->node_cb = NULL;
raxStackInit(&it->stack);
}
2.raxSeek
raxStart初始化迭代器后,必须调用raxSeek函数初始化迭代器的位置。
int raxSeek(raxIterator *it, const char *op, unsigned char *ele, size_t len);
·it为raxStart初始化的迭代器。
·op为查找操作符,可以为大于(>)、小于(<)、大于等于(>=)、小于等于(<=)、等于(=)、首个元素(^)、末尾元素($)。
·ele为待查找的key。
·len为ele的长度
查找末尾元素可以直接在Rax中找到最右侧的叶子节点,
查找首个元素被转换为查找大于等于空的操作。 return raxSeek(it,">=",NULL,0);
处理大于、小于、等于等操作主要分为以下几步。
- 在rax中查找key:
size_t i = raxLowWalk(it->rt,ele,len,&it->node,NULL,&splitpos,&it->stack);
- 如果key找到,并且op中设置了等于,则操作完成:
if (eq && i == len && (!it->node->iscompr || splitpos == 0) &&
it->node->iskey)
{
/* 找到该key并且op中设置了=. */
if (!raxIteratorAddChars(it,ele,len)) return 0; /* OOM. */
it->data = raxGetData(it->node);
}
3)如果仅仅设置等于,并没有找到key,则将迭代器的标志位设置为末尾。
4)如果设置了等于但没有找到key,或者设置了大于或者小于符号,则需要继续查找,这一步又分为2步。
①首先将查找key的路径中所有匹配的字符,放入迭代器存储key的数组中:
//将查找过程的最后一个节点放入路径栈
if (!raxStackPush(&it->stack,it->node)) return 0;
for (size_t j = 1; j < it->stack.items; j++) {
raxNode *parent = it->stack.stack[j-1];
raxNode *child = it->stack.stack[j];
if (parent->iscompr) {
if (!raxIteratorAddChars(it,parent->data,parent->size))
return 0;
} else {
raxNode **cp = raxNodeFirstChildPtr(parent);
unsigned char *p = parent->data;
while(1) {
raxNode *aux;
memcpy(&aux,cp,sizeof(aux));
if (aux == child) break;
cp++;
p++;
}
if (!raxIteratorAddChars(it,p,1)) return 0;
}
}
raxStackPop(&it->stack); //将最后一个节点从路径栈中弹出
②根据key的匹配情况以及op的参数,在rax中继续查找下一个或者上一个key,此时主要利用的是raxIteratorNextStep、raxIteratorPrevStep两个接口,这两个接口也是raxNext以及raxPrev的核心处理函数,
3.raxNext&raxPrev
raxNext与raxPrev为逆操作,高度的相似,此处以raxNext为例;
int raxNext(raxIterator *it) {
if (!raxIteratorNextStep(it,0)) {
errno = ENOMEM;
return 0;
}
if (it->flags & RAX_ITER_EOF) {
errno = 0;
return 0;
}
return 1;
}
raxIteratorNextStep函数
int raxIteratorNextStep(raxIterator *it, int noup)
·it 为待移动的迭代器。
·noup 为标志位,可以取0或者1。在raxSeek中,我们有时需要查找比某个key大的下一个key,并且这个待查找的key可能并不存在,此时可能需要将noup设置为1。
raxNext处理过程的重点有3点:
①如果迭代器当前的节点有子节点,则沿着其最左侧的节点一直向下,直到找到下一个key;
②如果当前节点没有子节点,则利用迭代器中的路径栈,依次弹出其父节点,查找父节点是否有其他比当前key大的子节点(迭代器中已经记录了当前的key,通过该值可以进行查找);
③注意noup为1时,我们已经假设迭代器当前节点为上一个key的父节点,故而在路径栈弹出时,第一次需要忽略。
while(1) {
int children = it->node->iscompr ? 1 : it->node->size;
if (!noup && children) {
//当前的节点有子节点
if (!raxStackPush(&it->stack,it->node)) return 0;
raxNode **cp = raxNodeFirstChildPtr(it->node);
if (!raxIteratorAddChars(it,it->node->data,
it->node->iscompr ? it->node->size : 1)) return 0;
memcpy(&it->node,cp,sizeof(it->node));
/* 当前节点为key节点, 直接返回. */
.......
} else {
/*当前节点没有子节点,找父节点. */
while(1) {
int old_noup = noup;
/* 已经迭代到rax头部节点,结束 */
......
/* 如果当前节点上没有子节点,请尝试父节点的下个子节点。 */
unsigned char prevchild = it->key[it->key_len-1];
if (!noup) { it->node = raxStackPop(&it->stack); }
else { noup = 0; //第一次弹出父节点的操作被跳过 }
int todel = it->node->iscompr ? it->node->size : 1;
raxIteratorDelChars(it,todel);
/* 如果至少有一个*额外的孩子,请尝试下一个孩子 */
if (!it->node->iscompr && it->node->size > (old_noup ? 0 : 1)) {
raxNode **cp = raxNodeFirstChildPtr(it->node);
int i = 0;
while (i < it->node->size) {
// 遍历节点所有子节点,找到下一个比当前key大的子节点
if (it->node->data[i] > prevchild) break;
i++; cp++;
}
if (i != it->node->size) {
// 找到了一个子节点比当前key大
raxIteratorAddChars(it,it->node->data+i,1);
if (!raxStackPush(&it->stack,it->node)) return 0;
memcpy(&it->node,cp,sizeof(it->node));
/* 当前节点为key,获取值后返回,不是key则跳出内部while循环 */
......
}
}
}
}
}
4.raxStop&raxEOF
raxEOF用于标识迭代器迭代结束,raxStop用于结束迭代并释放相关资源 ;
int raxEOF(raxIterator *it) {
return it->flags & RAX_ITER_EOF;
}
/* Free the iterator. */
void raxStop(raxIterator *it) {
if (it->key != it->key_static_string) rax_free(it->key);
raxStackFree(&it->stack);
}
8.4 Stream结构的实现
Stream可以看作是一个消息链表。对一个消息而言,只能新增或者删除,不能更改消息内容,故而本节主要介绍Stream相关结构的初始化以及增删查操作。首先介绍消息流的初始化,之后讲解消息的增删查、消费组的增删查以及消费组中消费者的增删查,最后,介绍如何遍历消息流中的所有消息。
8.4.1 初始化
/* Create a new stream data structure. */
stream *streamNew(void) {
stream *s = zmalloc(sizeof(*s));
s->rax = raxNew();
s->length = 0;
s->last_id.ms = 0;
s->last_id.seq = 0;
s->cgroups = NULL; /* 按需创建以在不使用时节省内存 */
return s;
}
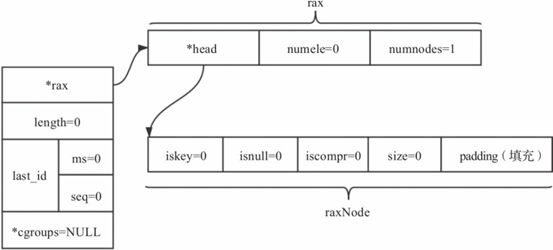
图8-18 Stream结构初始化
8.4.2 添加元素
任何用户都可以向某个消息流添加消息,或者消费某个消息流中的消息;
1.添加消息
Redis提供了streamAppendItem函数,用于向stream中添加一个新的消息:
int streamAppendItem(stream *s, robj **argv, int64_t numfields, streamID *added_id, streamID *use_id)
s 为待插入的数据流:
·argv 为待插入的消息内容,argv[0]为field_1,argv[1]为value_1,依此类推;
·numfields 为待插入的消息的field的总数;
·added_id 不为空,并且插入成功时,将新插入的消息id写入added_id以供调用方使用;
·use_id 为调用方为该消息定义的消息id,该消息id应该大于s中任意一个消息的id。
增加消息的流程如下。
①获取rax的最后一个key所在的节点,由于Rax树是按照消息id的顺序存储的,所以最后一个key节点存储了上一次插入的消息。
②查看该节点是否可以插入这条新的消息。
③如果该节点已经不能再插入新的消息(listpack为空或者已经达到设定的存储最大值),在rax中插入新的节点(以消息id为key,新建listpack为value),并初始化新建的listpack;
如果仍然可以插入消息,则对比插入的消息与listpack中的master消息对应的fields是否完全一致,完全一致则表明该消息可以复用master的field。
④将待插入的消息内容插入到新建的listpack中或者原来的rax的最后一个key节点对应的listpack中,这一步主要取决于前2步的结果。
该函数主要是利用了listpack以及rax的相关接口。
2.新增消费组
通过streamCreateCG为消息流新增一个消费组,以消费组的名称为key,该消费组的streamCG结构为value,放入rax中;
streamCG *streamCreateCG(stream *s, char *name, size_t namelen, streamID *id) {
// 如果当前消息流尚未有消费组,则新建消费组
if (s->cgroups == NULL) s->cgroups = raxNew();
// 查看是否已经有该消费组,有则新建失败
if (raxFind(s->cgroups,(unsigned char*)name,namelen) != raxNotFound)
return NULL;
// 新建消费组,并初始化相关变量
streamCG *cg = zmalloc(sizeof(*cg));
cg->pel = raxNew();
cg->consumers = raxNew();
cg->last_id = *id;
// 将该消费组插入到消息流的消费组树中, 以消费组的名称为key, 对应的streamCG为value
raxInsert(s->cgroups,(unsigned char*)name,namelen,cg,NULL);
return cg;
}
3.新增消费者
Stream允许为某个消费组增加消费者,但没有直接提供在某个消费组中创建消费者的接口,而是在查询某个消费组的消费者时,发现该消费组没有该消费者时选择插入该消费者,该接口在8.4.4节进行介绍。
8.4.3 删除元素
如何从消息流中删除消息以及限制消息流的大小。如何释放消费组中的消费者以及如何释放整个消费组。
1.删除消息
streamIteratorRemoveEntry函数用于移除某个消息,值得注意的是,该函数通常只是设置待移除消息的标志位为已删除,并不会将该消息从所在的listpack中删除。当消息所在的整个listpack的所有消息都已删除时,则会从rax中释放该节点。
void streamIteratorRemoveEntry(streamIterator *si, streamID *current) {
unsigned char *lp = si->lp;
int64_t aux;
int flags = lpGetInteger(si->lp_flags);
flags |= STREAM_ITEM_FLAG_DELETED;
lp = lpReplaceInteger(lp,&si->lp_flags,flags); // 设置消息的标志位
/* Change the valid/deleted entries count in the master entry. */
unsigned char *p = lpFirst(lp);
aux = lpGetInteger(p);
if (aux == 1) {
/* 当前Listpack只有待删除消息,可以直接删除节点. */
lpFree(lp);
raxRemove(si->stream->rax,si->ri.key,si->ri.key_len,NULL);
} else {
/* 修改listpack master enty中的统计信息 */
lp = lpReplaceInteger(lp,&p,aux-1);
p = lpNext(lp,p); /* Seek deleted field. */
aux = lpGetInteger(p);
lp = lpReplaceInteger(lp,&p,aux+1);
/* 查看listpack是否有变化(listpack中元素变化导致的扩容缩容) . */
if (si->lp != lp)
raxInsert(si->stream->rax,si->ri.key,si->ri.key_len,lp,NULL);
}
.....
}
2.裁剪消息流
就是将消息流的大小(未删除的消息个数,不包含已经删除的消息)裁剪到给定大小,删除消息时,按照消息id,从小到大删除。该接口为streamTrimByLength:
// stream为待裁剪的消息流; maxlen为消息流中最大的消息个数; approx为是否可以存在偏差
int64_t streamTrimByLength(stream *s, size_t maxlen, int approx) ;
对于消息流的裁剪,主要有以下几点。
1)消息删除是按照消息id的顺序进行删除的,先删除最先插入(即消息id最小的)消息。
2)从效率的角度上说,函数调用时最好加上approx标志位。
具体实现过程
1)获取stream的Rax树的第一个key所在的节点:
if (s->length <= maxlen) return 0; // stream中的消息个数小于maxlen,不需要删除
raxIterator ri; // 初始化rax迭代器
raxStart(&ri,s->rax);
raxSeek(&ri,"^",NULL,0);
int64_t deleted = 0; // 统计已经删除的消息个数
2)遍历rax树的节点,不断删除消息,直到剩余消息个数满足要求:
while(s->length > maxlen && raxNext(&ri)) {
// 遍历Rax树删除消息直到满足要求
}
3)具体删除消息的部分可以分为如下几步。
·查看是否需要删除当前节点,如果删除该节点存储的全部消息后仍然未达到要求,则删除该节点。
·不需要删除该节点存储的全部消息,如果函数参数中设置了"approx",则不再进行处理,可以直接返回。 // if (approx) break;
·不需要删除该节点的全部消息,则遍历该节点存储的消息,将部分消息的标志位设置为已经删除。
删除当前节点代码
if (s->length - entries >= maxlen) { // 需要删除该节点的全部消息
lpFree(lp);
raxRemove(s->rax,ri.key,ri.key_len,NULL); // 调用Rax的接口删除key
raxSeek(&ri,">=",ri.key,ri.key_len);
s->length -= entries;
deleted += entries;
continue;
}
遍历当前节点的消息,将其部分消息设置为已删除 代码
while(p) { // 遍历该节点存储的全部消息,依次删除,直到消息个数满足要求
int flags = lpGetInteger(p);
int to_skip;
/* Mark the entry as deleted. */
if (!(flags & STREAM_ITEM_FLAG_DELETED)) {
flags |= STREAM_ITEM_FLAG_DELETED;
lp = lpReplaceInteger(lp,&p,flags);
deleted++;
s->length--;
if (s->length <= maxlen) break; /* Enough entries deleted. */
}
// 移动到下一个消息 ....
}
3.释放消费组
接口为streamFreeCG,该接口主要完成2部分内容,首先释放该消费组的pel链表,之后释放消费组中的每个消费者。
/* Free a consumer group and all its associated data. */
void streamFreeCG(streamCG *cg) {
// 删除该消费组的pel链表,释放时设置回调函数用于释放每个消息对应的streamNACK结构
raxFreeWithCallback(cg->pel,(void(*)(void*))streamFreeNACK);
// 释放每个消费者时,需要释放该消费者对应的streamConsumer结构
raxFreeWithCallback(cg->consumers,(void(*)(void*))streamFreeConsumer);
zfree(cg);
}
/* Free a NACK entry(未确认). */
void streamFreeNACK(streamNACK *na) {
zfree(na);
}
4.释放消费者
需要注意的是,不需要释放该消费者的pel,因为该消费者的未确认消息结构streamNACK是与消费组的pel共享的,直接释放相关内存即可。
void streamFreeConsumer(streamConsumer *sc) {
raxFree(sc->pel); /*此处仅仅是将存储streamNACK的Rax树释放 /
sdsfree(sc->name);
zfree(sc);
}
8.4.4 查找元素
查找消息、查找消费组、查找消费组中的消费者 ;
(1)查找消息
Stream查找消息是通过迭代器实现的,这部分内容我们将在8.4.5节进行介绍。
(2)查找消费组
Redis提供了streamLookupCG接口用于查找Stream的消费组,该接口较为简单,主要是利用Rax的查询接口:
streamCG *streamLookupCG(stream *s, sds groupname) {
if (s->cgroups == NULL) return NULL;
streamCG *cg = raxFind(s->cgroups,(unsigned char*)groupname,
sdslen(groupname));
return (cg == raxNotFound) ? NULL : cg;
}
(3)查找消息组中的消费者
streamLookupConsumer接口用于查询某个消费组中的消费者。消费者不存在时,可以选择是否将该消费者添加进消费组。
/*在消费组cg中查找消费者name; 如果没有查到并且create为1时,将该消费者加入消费组 */
streamConsumer *streamLookupConsumer(streamCG *cg, sds name, int flags) {
int create = !(flags & SLC_NOCREAT);
int refresh = !(flags & SLC_NOREFRESH);
streamConsumer *consumer = raxFind(cg->consumers,(unsigned char*)name,
sdslen(name));
if (consumer == raxNotFound) {
if (!create) return NULL; // 不需要插入
consumer = zmalloc(sizeof(*consumer));
consumer->name = sdsdup(name);
consumer->pel = raxNew();
raxInsert(cg->consumers,(unsigned char*)name,sdslen(name),
consumer,NULL);
}
if (refresh) consumer->seen_time = mstime(); //已经查询到该消费者,更新时间戳
return consumer;
}
8.4.5 遍历
Stream的迭代器streamIterator,用于遍历Stream中的消息,相关的接口主要有以下4个:
// 用于初始化迭代器,值得注意的是,需要指定迭代器的方向。
void streamIteratorStart(streamIterator *si, stream *s, streamID *start, streamID *end, int rev);
//streamIteratorGetID与streamIteratorGetField配合使用,用于遍历所有消息的所有field-value
int streamIteratorGetID(streamIterator *si, streamID *id, int64_t *numfields);
void streamIteratorGetField(streamIterator *si, unsigned char **fieldptr, unsigned char **valueptr, int64_t *fieldlen, int64_t *valuelen);
// 释放迭代器的相关资源。
void streamIteratorStop(streamIterator *si);
1)streamIteratorStart接口
接口负责初始化streamIterator。它的具体实现主要是利用Rax提供的迭代器:
void streamIteratorStart(streamIterator *si, stream *s, streamID *start, streamID *end, int rev) {
.....
/* 在基数树中寻找正确的节点. */
raxStart(&si->ri,s->rax);
if (!rev) { // 正向迭代器
if (start && (start->ms || start->seq)) { // 设置了开始的消息id
raxSeek(&si->ri,"<=",(unsigned char*)si->start_key,
sizeof(si->start_key));
if (raxEOF(&si->ri)) raxSeek(&si->ri,"^",NULL,0);
} else {
raxSeek(&si->ri,"^",NULL,0); // 默认情况为指向Rax树中第一个key所在的节点
}
} else { // 逆向迭代器
if (end && (end->ms || end->seq)) {
raxSeek(&si->ri,"<=",(unsigned char*)si->end_key,
sizeof(si->end_key));
if (raxEOF(&si->ri)) raxSeek(&si->ri,"$",NULL,0);
} else {
raxSeek(&si->ri,"$",NULL,0);
}
}
si->stream = s;
si->lp = NULL; /* There is no current listpack right now. */
si->lp_ele = NULL; /* Current listpack cursor. */
si->rev = rev; /* Direction, if non-zero reversed, from end to start. */
}
2)streamIteratorGetID接口
该接口负责获取迭代器当前的消息id,可以分为以下2步。
①查看当前所在的Rax树的节点是否仍然有其他消息,没有则根据迭代器方向调用Rax迭代器接口向前或者向后移动。
②在rax key对应的listpack中,查找尚未删除的消息,此处需要注意streamIterator的指针移动。
streamIteratorGetField接口
直接使用该迭代器内部的指针,获取当前消息的field-value对:
void streamIteratorGetField(streamIterator *si, unsigned char **fieldptr, unsigned char **valueptr, int64_t *fieldlen, int64_t *valuelen) {
if (si->entry_flags & STREAM_ITEM_FLAG_SAMEFIELDS) {
// 当前消息的field内容与master_fields一致,读取master_field域内容
*fieldptr = lpGet(si->master_fields_ptr,fieldlen,si->field_buf);
si->master_fields_ptr = lpNext(si->lp,si->master_fields_ptr);
} else { // 直接获取当前的field, 移动lp_ele指针
*fieldptr = lpGet(si->lp_ele,fieldlen,si->field_buf);
si->lp_ele = lpNext(si->lp,si->lp_ele);
}
// 获取field对应的value,并将迭代器lp_ele指针向后移动
*valueptr = lpGet(si->lp_ele,valuelen,si->value_buf);
si->lp_ele = lpNext(si->lp,si->lp_ele);
}
streamIteratorStop接口
主要利用raxIterator接口释放相关资源:
void streamIteratorStop(streamIterator *si) {
raxStop(&si->ri);
}
8.5 本章小结
本章主要介绍了Stream的底层实现。首先讲解了Stream结构需要依赖的两种数据结构Listpack以及Rax,并详细介绍了这两种结构的基本操作。之后,进一步说明了Stream是如何利用这两种结构的。