Redis服务器是典型的事件驱动程序,而Redis将事件分为两大类:文件事件与时间事件。文件事件即socket的读写事件,时间事件用于处理一些需要周期性执行的定时任务,本章将对这两种事件作详细介绍。
9.1 基本知识
比如客户端信息的存储,Redis对外支持的命令集合,客户端与服务器socket读写事件的处理,Redis内部定时任务的执行等,本节将对这些知识进行简要介绍。
9.1.1 对象结构体robj
key只能是字符串,value可以是字符串、列表、集合、有序集合和散列表,这5种数据类型用结构体robj表示,我们称之为Redis对象。结构体robj的type字段表示对象类型,5种对象类型在server.h文件中定义:
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
结构体robj的encoding字段表示当前对象底层存储采用的数据结构,即对象的编码,总共定义了11种encoding常量,见表9-1:
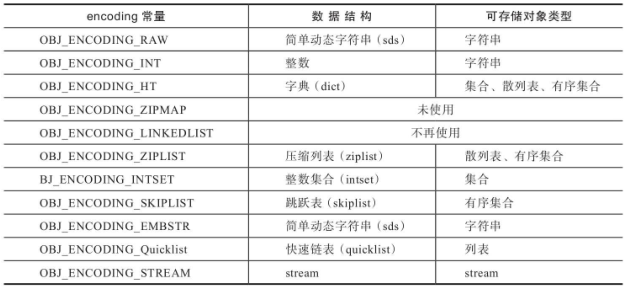
表9-1 对象编码类型表
对象的整个生命周期中,编码不是一成不变的,比如集合对象。当集合中所有元素都可以用整数表示时,底层数据结构采用整数集合;当执行sadd命令向集合中添加元素时,Redis总会校验待添加元素是否可以解析为整数,如果解析失败,则会将集合存储结构转换为字典。如下所示:
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
subject->ptr = intsetAdd(subject->ptr,llval,&success);
} else {
/* /编码转换 ,Failed to get integer from object, convert to regular set. */
setTypeConvert(subject,OBJ_ENCODING_HT);
}
字典与跳跃表各有优势,因此Redis会同时采用字典与跳跃表存储有序集合。
有序集合结构定义如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
结构体robj的定义:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* 24, 缓存淘汰使用 */
int refcount; // 引用计数
void *ptr;
} robj;
结构体各字段含义:
1)ptr 是void*类型的指针,指向实际存储的某一种数据结构,但是当robj存储的数据可以用long类型表示时,数据直接存储在ptr字段。可以看出,为了创建一个字符串对象,必须分配两次内存,robj与sds存储空间;两次内存分配效率低下,且数据分离存储降低了计算机高速缓存的效率。因此提出OBJ_ENCODING_EMBSTR编码的字符串,当字符串内容比较短时,只分配一次内存,robj与sds连续存储,以此提升内存分配效率与数据访问效率。
OBJ_ENCODING_EMBSTR编码的字符串内存结构如图9-1所示。
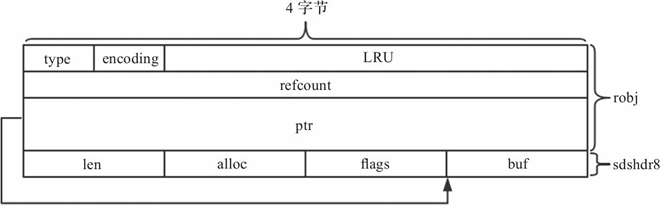
图9-1 EMBSTR编码字符串对象内存结构
2)refcount 存储当前对象的引用次数,用于实现对象的共享。共享对象时,refcount加1;删除对象时,refcount减1,当refcount值为0时释放对象空间。删除对象的代码如下:
void decrRefCount(robj *o) {
if (o->refcount == 1) {
switch(o->type) { // 根据对象类型,释放其指向数据结构空间
case OBJ_STRING: freeStringObject(o); break;
case OBJ_LIST: freeListObject(o); break;
case OBJ_SET: freeSetObject(o); break;
case OBJ_ZSET: freeZsetObject(o); break;
case OBJ_HASH: freeHashObject(o); break;
case OBJ_MODULE: freeModuleObject(o); break;
case OBJ_STREAM: freeStreamObject(o); break;
default: serverPanic("Unknown object type"); break;
}
zfree(o); //释放对象空间
} else {
if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount--; //引用计数减1
}
}
3)lru字段 占24比特,用于实现缓存淘汰策略,可以在配置文件中使用maxmemory-policy配置已用内存达到最大内存限制时的缓存淘汰策略。lru根据用户配置的缓存淘汰策略存储不同数据,常用的策略就是LRU与LFU。
LRU的核心思想是,如果数据最近被访问过,那么将来被访问的几率也更高,此时lru字段存储的是对象访问时间;
LFU的核心思想是,如果数据过去被访问多次,那么将来被访问的频率也更高,此时lru字段存储的是上次访问时间与访问次数。例如使用GET命令访问数据时,会执行下面代码更新对象的lru字段:
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
LRU_CLOCK函数用于获取当前时间,注意此时间不是实时获取的,Redis以1秒为周期执行系统调用获取精确时间,缓存在全局变量server.lruclock,LRU_CLOCK函数获取的只是该缓存时间。
updateLFU函数用于更新对象的上次访问时间与访问次数,函数实现如下:
void updateLFU(robj *val) {
unsigned long counter = LFUDecrAndReturn(val);
counter = LFULogIncr(counter);
val->lru = (LFUGetTimeInMinutes()<<8) | counter;
}
可以发现lru的低8比特存储的是对象的访问次数,高16比特存储的是对象的上次访问时间,以分钟为单位;需要特别注意的是函数LFUDecrAndReturn,其返回计数值counter,对象的访问次数在此值上累加。为什么不直接累加呢?因为假设每次只是简单的对访问次数累加,那么越老的数据一般情况下访问次数越大,即使该对象可能很长时间已经没有访问,相反新对象的访问次数通常会比较小,显然这是不公平的。因此访问次数应该有一个随时间衰减的过程,函数
LFUDecrAndReturn实现了此衰减功能。
9.1.2 客户端结构体client
Redis是典型的客户端服务器结构,客户端通过socket与服务端建立网络连接并发送命令请求,服务端处理命令请求并回复。Redis使用结构体client存储客户端连接的所有信息,包括但不限于客户端的名称、客户端连接的套接字描述符、客户端当前选择的数据库ID、客户端的输入缓冲区与输出缓冲区等。结构体client字段较多,此处只介绍命令处理主流程所需的关键字段。
typedef struct client {
uint64_t id; //客户端唯一ID,通过全局变量server.next_client_id实现
int fd; //客户端socket的文件描述符
redisDb *db; //客户端使用select命令选择的数据库对象
robj *name; //客户端名称,可以使用命令CLIENT SETNAME设置
time_t lastinteraction //客户端上次与服务器交互的时间,以此实现客户端的超时处理
sds querybuf; //输入缓冲区,recv函数接收的客户端命令请求会暂时缓存在此缓冲区
int argc; //输入缓冲区的命令请求是按照Redis协议格式编码字符串,需要解析出命令请求的所有参数,参数个数存储在argc字段,参数内容被解析为robj对象,存储在argv数组
robj **argv;
struct redisCommand *cmd; //待执行的客户端命令;解析命令请求后,会根据命令名
称查找该命令对应的命令对象,存储在客户端cmd字段,可以看到其类型为struct redisCommand
list *reply; //输出链表,存储待返回给客户端的命令回复数据。
unsigned long long reply_bytes; //表示输出链表中所有节点的存储空间总和
size_t sentlen; //表示已返回给客户端的字节数;
char buf[PROTO_REPLY_CHUNK_BYTES]; //输出缓冲区,存储待返回给客户端的命令回复数据,bufpos表示输出缓冲区中数据的最大字节位置,显然sentlen~bufpos区间的数据都是需要返回给客户端的。可以看到reply和buf都用于缓存待返回给客户端的命令回复数据,为什么同时需要reply和buf的存在呢?其实二者只是用于返回不同的数据类型而已。
int bufpos;
} client;
redisDb
redisDb结构体定义如下:
typedef struct redisDb {
dict *dict; /* 存储数据库所有键值对*/
dict *expires; /*存储键的过期时间 */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* 数据库序号,默认情况下Redis有16个数据库,id序号为0~15 */
long long avg_ttl; /* 存储数据库对象的平均TTL,用于统计*/
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
使用命令BLPOP阻塞获取列表元素时,如果链表为空,会阻塞客户端,同时将此列表键记录在blocking_keys;当使用命令PUSH向列表添加元素时,会从字典blocking_keys中查找该列表键,如果找到说明有客户端正阻塞等待获取此列表键,于是将此列表键记录到字典ready_keys,以便后续响应正在阻塞的客户端。
Redis事务
Redis支持事务,命令multi用于开启事务,命令exec用于执行事务;但是开启事务到执行事务期间,如何保证关心的数据不会被修改呢?Redis采用乐观锁实现。开启事务的同时可以使用watch key命令监控关心的数据键,而watched_keys字典存储的就是被watch命令监控的所有数据键,其中key-value分别为数据键与客户端对象。当Redis服务器接收到写命令时,会从字典watched_keys中查找该数据键,如果找到说明有客户端正在监控此数据键,于是标记客户端对象为dirty;待Redis服务器收到客户端exec命令时,如果客户端带有dirty标记,则会拒绝执行事务。
reply.链表
链表节点存储的值类型为clientReplyBlock,定义如下:
可以看到链表节点本质上就是一个缓冲区(buffer);
typedef struct clientReplyBlock {
size_t size, used; //size表示缓冲区空间总大小,used表示缓冲区已使用空间大小
char buf[];
} clientReplyBlock;
9.1.3 服务端结构体redisServer
结构体redisServer存储Redis服务器的所有信息,包括但不限于数据库、配置参数、命令表、监听端口与地址、客户端列表、若干统计信息、RDB与AOF持久化相关信息、主从复制相关信息、集群相关信息等。结构体redisServer的字段非常多,这里只对部分字段做简要说明,以便读者对服务端有个粗略了解,至于其他字段在讲解各知识点时会进行说明。
结构体redisServer定义如下:
struct redisServer {
char *configfile; //配置文件绝对路径
int dbnum; //数据库的数目,可通过参数databases配置,默认16
redisDb *db; //数据库数组,数组的每个元素都是redisDb类型
dict *commands; //命令字典,Redis支持的所有命令都存储在这个字典中,key为命令名称,vaue为struct redisCommand对象。
aeEventLoop *el; //Redis是典型的事件驱动程序,el代表Redis的事件循环,类型为aeEventLoop
int port; //服务器监听端口号,可通过参数port配置,默认端口号6379。
char *bindaddr[CONFIG_BINDADDR_MAX]; //绑定的所有IP地址,可以通过参数bind配置多个,例如bind 192.168.1.10010.0.0.1,;CONFIG_BINDADDR_MAX常量为16,即最多绑定16个IP地址;Redis默认会绑定到当前机器所有可用的Ip地址;
int bindaddr_count; //bindaddr_count为用户配置的IP地址数目
int ipfd[CONFIG_BINDADDR_MAX]; //针对bindaddr字段的所有IP地址创建的socket文件描述符,
int ipfd_count; //ipfd_count为创建的socket文件描述符数目
list *clients; //当前连接到Redis服务器的所有客户端。
int maxidletime; //最大空闲时间,可通过参数timeout配置,结合client对象的lastinteraction字段,当客户端没有与服务器交互的时间超过maxidletime时,会认为客户端超时并释放该客户端连接;
}
9.1.4 命令结构体redisCommand
Redis支持的所有命令初始都存储在全局变量
redisCommandTable,类型为redisCommand,定义及初始化如下:
struct redisCommand redisCommandTable[] = {
{"module",moduleCommand,-2,
"admin no-script",
0,NULL,0,0,0,0,0,0},
{"get",getCommand,2,
"read-only fast @string",
0,NULL,1,1,1,0,0,0},
...
}
结构体redisCommand相对简单,主要定义了命令的名称、命令处理函数以及命令标志等:
struct redisCommand {
char *name; // 命令名称
redisCommandProc *proc; //命令处理函数
int arity; //命令参数数目,用于校验命令请求格式是否正确;当arity小于0时,表示命令参数数目大于等于arity;当arity大于0时,表示命令参数数目必须为arity;注意命令请求中,命令的名称本身也是一个参数,如get命令的参数数目为2,命令请求格式为get key。
char *sflags; /* 命令标志,例如标识命令时读命令还是写命令,详情参见表9-2;注意到sflags的类型为字符串,此处只是为了良好的可读性。 */
uint64_t flags; /* 命令的二进制标志,服务器启动时解析sflags字段生成*/
/* 使用函数确定命令行中的键自变量。 用于Redis群集重定向。*/
redisGetKeysProc *getkeys_proc;
/* 调用此命令时应在后台加载哪些键? */
int firstkey; /* The first argument that's a key (0 = no keys) */
int lastkey; /* The last argument that's a key */
int keystep; /* 第一个和最后一个键之间的步骤*/
long long microseconds, calls;
// calls :从服务器启动至今命令执行的次数,用于统计
// microseconds:从服务器启动至今命令总的执行时间,microseconds/calls即可计算出该 命令的平均处理时间,用于统计
int id; //命令id
};
表9-2 命令标志类型

当服务器接收到一条命令请求时,需要从命令表中查找命令,而redisCommandTable命令表是一个数组,意味着查询命令的时间复杂度为O(N),效率低下。
因此Redis在服务器初始化时,会将redisCommandTable转换为一个字典存储在redisServer对象的commands字段,key为命令名称,value为命令redisCommand对象。populateCommandTable函数实现了命令表从数组到字典的转化,同时解析sflags生成flags:
/* Populates the Redis Command Table starting from the hard coded list
* we have on top of redis.c file. */
void populateCommandTable(void) {
int j;
int numcommands = sizeof(redisCommandTable)/sizeof(struct redisCommand);
for (j = 0; j < numcommands; j++) {
struct redisCommand *c = redisCommandTable+j;
int retval1, retval2;
/* 将命令字符串标志描述转换为实际的标志集.
修改标志字符串描述'strflags'并将它们设置为命令'c'。
如果所有标志均有效,则返回C_OK,否则返回*C_ERR(但已在命令中设置了已识别的标志
*/
if (populateCommandTableParseFlags(c,c->sflags) == C_ERR)
serverPanic("Unsupported command flag");
c->id = ACLGetCommandID(c->name); /* Assign the ID used for ACL. */
retval1 = dictAdd(server.commands, sdsnew(c->name), c);
/* 使用redis.conf中的重命名命令语句填充一个不会受到影响的附加词典。 */
retval2 = dictAdd(server.orig_commands, sdsnew(c->name), c);
serverAssert(retval1 == DICT_OK && retval2 == DICT_OK);
}
}
对于经常使用的命令,Redis甚至会在服务器初始化的时候将命令缓存在redisServer对象,这样使用的时候就不需要每次都从commands字典中查找了:
struct redisServer {
/* Fast pointers to often looked up command */
struct redisCommand *delCommand, *multiCommand, *lpushCommand,
*lpopCommand, *rpopCommand, *zpopminCommand,
*zpopmaxCommand, *sremCommand, *execCommand,
*expireCommand, *pexpireCommand, *xclaimCommand,
*xgroupCommand, *rpoplpushCommand;...
}
9.1.5 事件处理
Redis服务器是典型的事件驱动程序,而事件又分为文件事件(socket的可读可写事件)与时间事件(定时任务)两大类。无论是文件事件还是时间事件都封装在结构体aeEventLoop中:
/* State of an event based program */
typedef struct aeEventLoop {
int maxfd; /* 当前注册的最高文件描述符 */
int setsize; /* 跟踪的文件描述符的最大数量 */
long long timeEventNextId;
time_t lastTime; /* Used to detect system clock skew */
aeFileEvent *events; /* 注册的文件事件数组 */
aeFiredEvent *fired; /* 存储被触发的文件事件 */
aeTimeEvent *timeEventHead; // 时间事件链表头节点
int stop; // 标识事件循环是否结束
void *apidata; /*Redis底层可以使用4种I/O多路复用模型(kqueue、epoll等),apidata是对这4种模型的进一步封装。 */
aeBeforeSleepProc *beforesleep; // Redis服务器需要阻塞等待文件事件的发生,进程阻塞之前会调用beforesleep函数
aeBeforeSleepProc *aftersleep; // 进程因为某种原因被唤醒之后会调用aftersleep函数
int flags;
} aeEventLoop;
事件驱动程序通常存在while/for循环,循环等待事件发生并处理,Redis也不例外,其事件循环如下:
while (!eventLoop->stop) {
// 事件处理主函数 ,第2个参数是一个标志位
aeProcessEvents(eventLoop, AE_ALL_EVENTS| // 函数需要处理文件事件与时间事件
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP); //阻塞等待文件事件之后需要执行aftersleep函数
}
1.文件事件
Redis客户端通过TCP socket与服务端交互,文件事件指的就是socket的可读可写事件。socket读写操作有阻塞与非阻塞之分。采用阻塞模式时,一个进程只能处理一条网络连接的读写事件,为了同时处理多条网络连接,通常会采用多线程或者多进程,效率低下;非阻塞模式下,可以使用目前比较成熟的I/O多路复用模型,如select/epoll/kqueue等,视不同操作系统而定。
epoll简要介绍。
epoll是Linux内核为处理大量并发网络连接而提出的解决方案,能显著提升系统CPU利用率。epoll使用非常简单,
总共只有3个API:
epoll_create 函数创建一个epoll专用的文件描述符,用于后续epoll相关API调用;
epoll_ctl 函数向epoll注册、修改或删除需要监控的事件;
epoll_wait 函数会阻塞进程,直到监控的若干网络连接有事件发生。
① int epoll_create(int size)
输入参数 size 通知内核程序期望注册的网络连接数目,内核以此判断初始分配空间大小;注意在Linux 2.6.8版本以后,内核动态分配空间,此参数会被忽略。返回参数为epoll专用的文件描述符,不再使用时应该及时关闭此文件描述符。
② int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
函数执行成功时返回0,否则返回-1,错误码设置在变量errno,输入参数含义如下。
·epfd:函数epoll_create返回的epoll文件描述符。
·op:需要进行的操作,EPOLL_CTL_ADD表示注册事件,EPOLL_CTL_MOD表示修改网络 连接事件,EPOLL_CTL_DEL表示删除事件。
·fd:网络连接的socket文件描述符。
·event:需要监控的事件,结构体epoll_event定义如下:
struct epoll_event {
__uint32_t events; //需要监控的事件类型,比较常用的是EPOLLIN文件描述符可读事件,EPOLLOUT文件描述符可写事件;
epoll_data_t data; //保存与文件描述符关联的数据。
};
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
③ int epoll_wait(int epfd,struct epoll_event * events,int maxevents,int timeout)
函数执行成功时返回0,否则返回-1,错误码设置在变量errno;输入参数含义如下:
·epfd:函数epoll_create返回的epoll文件描述符;
·epoll_event:作为输出参数使用,用于回传已触发的事件数组;
·maxevents:每次能处理的最大事件数目;
·timeout:epoll_wait 函数阻塞超时时间,如果超过时间还没有事件发生,函数不再阻塞直接返回;当timeout等于0时函数立即返回,timeout等于-1时函数会一直阻塞直到有事件发生。
Redis/O多路复用
Redis并没有直接使用epoll提供的API,而是同时支持4种I/O多路复用模型,并将这些模型的API进一步统一封装,由文件ae_evport.c、ae_epoll.c、ae_kqueue.c和ae_select.c实现。Redis在编译阶段,会检查操作系统支持的I/O多路复用模型,并按照一定规则决定使用哪种模型。
以epoll为例,
aeApiCreate函数是对epoll_create的封装;
aeApiAddEvent函数用于添加事件,是对epoll_ctl的封装;
aeApiDelEvent函数用于删除事件,是对epoll_ctl的封装;
aeApiPoll是对epoll_wait的封装。
static int aeApiCreate(aeEventLoop *eventLoop) ;
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)
static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int delmask)
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
4个函数的输入参数含义如下。
·eventLoop:事件循环,与文件事件相关的最主要字段有3个,apidata指向I/O多路复用模型对象,注意4种I/O多路复用模型对象的类型不同,因此此字段是void*类型;events存储需要监控的事件数组,以socket文件描述符作为数组索引存取元素;fired存储已触发的事件数组。
以epoll模型为例,apidata字段指向的I/O多路复用模型对象定义如下:
typedef struct aeApiState {
int epfd; // 函数epoll_create返回的epoll文件描述符
struct epoll_event *events; //存储epoll_wait函数返回时已触发的事件数组
} aeApiState;
·fd:操作的socket文件描述符;
·mask 或delmask :添加或者删除的事件类型,AE_NONE表示没有任何事件;AE_READABLE表示可读事件;AE_WRITABLE表示可写事件;
·tvp:阻塞等待文件事件的超时时间。
这里只对等待事件函数aeApiPoll实现作简要介绍:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
// 阻塞等待事件的发生
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
if (retval > 0) {
int j;
numevents = retval;
//Redis再次遍历所有已触发事件
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
// 转换事件类型为Redis定义的
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE|AE_READABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE|AE_READABLE;
//记录已发生事件到fired数组
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
return numevents;
}
说明:
函数首先需要通过eventLoop->apidata字段获取epoll模型对应的aeApiState结构体对象,才能调用epoll_wait函数等待事件的发生;epoll_wait函数将已触发的事件存储到aeApiState对象的events字段,Redis再次遍历所有已触发事件,将其封装在eventLoop->fired数组,数组元素类型为结构体aeFiredEvent,只有两个字段,fd表示发生事件的socket文件描述符,mask表示发生的事件类型,如AE_READABLE可读事件和AE_WRITABLE可写事件。
文件事件
结构体aeEventLoop有一个关键字段events,类型为aeFileEvent数组,存储所有需要监控的文件事件。文件事件结构体定义如下:
typedef struct aeFileEvent {
int mask; // 存储监控的文件事件类型,如AE_READABLE可读事件和AE_WRITABLE可写事件
aeFileProc *rfileProc; // 为函数指针,指向读事件处理函数
aeFileProc *wfileProc; // 同样为函数指针,指向写事件处理函数
void *clientData; // 指向对应的客户端对象
} aeFileEvent;
调用aeApiAddEvent函数添加事件之前,首先需要调用aeCreateFileEvent函数创建对应的文件事件,并存储在aeEventLoop结构体的events字段,aeCreateFileEvent函数简单实现如下:
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
aeFileEvent *fe = &eventLoop->events[fd];
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
fe->clientData = clientData;
if (fd > eventLoop->maxfd)
eventLoop->maxfd = fd;
return AE_OK;
}
Redis服务器启动时需要创建socket并监听,等待客户端连接;客户端与服务器建立socket连接之后,服务器会等待客户端的命令请求;服务器处理完客户端的命令请求之后,命令回复会暂时缓存在client结构体的buf缓冲区,待客户端文件描述符的可写事件发生时,才会真正往客户端发送命令回复。
这些都需要创建对应的文件事件:
aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL);
aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c);
aeCreateFileEvent(server.el, c->fd, ae_flags,
sendReplyToClient, c);
接收客户端连接的处理函数为acceptTcpHandler,此时还没有创建对应的客户端对象,因此函数aeCreateFileEvent第4个参数为NULL;
接收客户端命令请求的处理函数为readQueryFromClient;
向客户端发送命令回复的处理函数为sendReplyToClient。
最后思考一个问题,aeApiPoll函数的第2个参数是时间结构体timeval,存储调用epoll_wait时传入的超时时间,那么这个时间是怎么计算出来的呢?我们之前提过,Redis除了要处理各种文件事件外,还需要处理很多定时任务(时间事件),那么当Redis由于执行epoll_wait而阻塞时,恰巧定时任务到期而需要处理怎么办?要回答这个问题需要分析Redis事件循环的执行函数aeProcessEvents,函数在调用aeApiPoll之前会遍历Redis的时间事件链表,查找最早会发生的时间事件,以此作为aeApiPoll需要传入的超时时间。如下所示:
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
shortest = aeSearchNearestTimer(eventLoop);
long long ms =
(shortest->when_sec - now_sec)*1000 +
shortest->when_ms - now_ms;
…………
/* 阻塞等待文件事件发生. */
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
//处理文件事件,即根据类型执行rfileProc或wfileProc
/* 处理时间事件*/
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
}
该方法注释 : 处理每个待处理的时间事件,然后处理每个待处理的文件事件(可以由刚刚处理的时间事件回调注册)。 如果没有特殊标志,该功能将一直休眠,直到引发某些文件事件或下次发生事件(如果有)时为止。
2.时间事件
前面介绍了Redis文件事件,已经知道事件循环执行函数aeProcessEvents的主要逻辑:
①查找最早会发生的时间事件,计算超时时间;
②阻塞等待文件事件的产生;
③处理文件事件;
④处理时间事件。时间事件的执行函数为processTimeEvents。
Redis服务器内部有很多定时任务需要执行,比如定时清除超时客户端连接,定时删除过期键等,定时任务被封装为时间事件aeTimeEvent对象,多个时间事件形成链表,存储在aeEventLoop结构
体的timeEventHead字段,它指向链表首节点。时间事件aeTimeEvent定义如下:
/* Time event structure */
typedef struct aeTimeEvent {
long long id; /* 时间事件唯一ID,通过字段eventLoop->timeEventNextId实现; */
long when_sec; /* 时间事件触发的秒数 */
long when_ms; /* 时间事件触发的毫秒数 */
aeTimeProc *timeProc; // 函数指针,指向时间事件处理函数
aeEventFinalizerProc *finalizerProc; // 函数指针,删除时间事件节点之前会调用此函数;
void *clientData; // 指向对应的客户端对象
struct aeTimeEvent *prev;
struct aeTimeEvent *next; // 指向下一个时间事件节点
int refcount; /* refcount以防止在递归时间事件调用中释放计时器事件 */
} aeTimeEvent;
时间事件执行函数processTimeEvents
处理逻辑比较简单,只是遍历时间事件链表,判断当前时间事件是否已经到期,如果到期则执
行时间事件处理函数timeProc:
static int processTimeEvents(aeEventLoop *eventLoop) {
while(te) {
aeGetTime(&now_sec, &now_ms);
if (now_sec > te->when_sec ||
(now_sec == te->when_sec && now_ms >= te->when_ms))
{
// 处理时间事件
retval = te->timeProc(eventLoop, id, te->clientData);
//重新设置时间事件到期时间
if (retval != AE_NOMORE) {
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms);
}
}
te = te->next;
}
return processed;
}
注意时间事件处理函数timeProc返回值retval,其表示此时间事件下次应该被触发的时间,单位为毫秒,且是一个相对时间,即从当前时间算起,retval毫秒后此时间事件会被触发。其实Redis只有一个时间事件,看到这里读者可能会有疑惑,服务器内部不是有很多定时任务吗, 为什么只有一个时间事件呢?回答此问题之前我们需要先分析这个唯一的时间事件。
Redis创建时间事件节点的函数为aeCreateTimeEvent,内部实现非常简单,只是创建时间事件并添加到时间事件链表。aeCreateTimeEvent函数定义如下:
long long aeCreateTimeEvent(aeEventLoop *eventLoop, long long milliseconds,
aeTimeProc *proc, void *clientData,
aeEventFinalizerProc *finalizerProc);
·eventLoop:输入参数指向事件循环结构体;
·milliseconds:表示此时间事件触发时间,单位毫秒,注意这是一个相对时间,即从当前时间算起,milliseconds毫秒后此时间事件会被触发;
·proc:指向时间事件的处理函数;
·clientData:指向对应的结构体对象;
·finalizerProc:同样是函数指针,删除时间事件节点之前会调用此函数。
读者可以在代码目录全局搜索aeCreateTimeEvent,会发现确实只创建了一个时间事件:
aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL);
该时间事件在1毫秒后会被触发,处理函数为serverCron,参数clientData与finalizerProc都为NULL。而函数serverCron实现了Redis服务器所有定时任务的周期执行。
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
....
run_with_period(100) {
... //100毫秒周期执行
}
run_with_period(5000) {
... //5000毫秒周期执行
}
/*清除超时客户端连接 . */
clientsCron();
/* 处理数据库 */
databasesCron();
...
server.cronloops++; //变量server.cronloops用于记录serverCron函数的执行次数
return 1000/server.hz; //变量server.hz表示serverCron函数的执行频率,用户可配置,最小为1最大为500,默认为10
}
run_with_period宏定义实现了定时任务按照指定时间周期(_ms_)执行,此时会被替换为一个if条件判断,条件为真才会执行定时任务,定义如下
#define run_with_period(_ms_) if ((_ms_ <= 1000/server.hz) || !(server.cronloops%((_ms_)/(1000/server.hz))))
serverCron函数会无条件执行某些定时任务,比如清除超时客户端连接,以及处理数据库(清除数据库过期键等)。需要特别注意一点,serverCron函数的执行时间不能过长,否则会导致服务器不能及时响应客户端的命令请求。
下面以过期键删除为例,分析Redis是如何保serverCron函数的执行时间。过期键删除由函数activeExpireCycle实现,由函数databasesCron调用,其函数是实现如下:
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25
void activeExpireCycle(int type) {
timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
timelimit_exit = 0;
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
do {
/* 查找过期键并删除. */
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
} while (sampled == 0 ||
(expired*100/sampled) > config_cycle_acceptable_stale);
}
}
最多遍历"dbs_per_call"个数据库,并记录每个数据库删除的过期键数目;当删除过期键数目大于门限时,认为此数据库过期键较多,需要再次处理。考虑到极端情况,当数据库键数目非常多且基本都过期时,do-while循环会一直执行下去。因此我们添加timelimit时间限制,每执行16次do-while循环,检测函数activeExpireCycle执行时间是否超过timelimit,如果超过则强制结束循环。
初看timelimit的计算方式可能会比较疑惑,其计算结果使得函数activeExpireCycle的总执行时间占CPU时间的25%,即每秒函数activeExpireCycle的总执行时间为1000000×25/100单位微秒。仍然假设server.hz取默认值10,即每秒函数activeExpireCycle执行10次,那么每次函数activeExpireCycle的执行时间为1000000×25/100/10,单位微秒。
9.2 server启动过程
学习Redis服务器的启动过程,主要分为server初始化,监听端口以及等待命令3节。
9.2.1 server初始化
服务器初始化主流程(见图9-2)可以简要分为7个步骤:

①初始化配置,包括用户可配置的参数,以及命令表的初始化;
由函数initServerConfig实现,具体操作就是给配置参数赋初始值:
void initServerConfig(void) {
.......
// serverCron函数执行频率,默认10
server.hz = CONFIG_DEFAULT_HZ;
//监听端口,默认6379
server.port = CONFIG_DEFAULT_SERVER_PORT;
//最大客户端数目,默认10 000
server.maxclients = CONFIG_DEFAULT_MAX_CLIENTS;
//客户端超时时间,默认0,即永不超时
server.maxidletime = CONFIG_DEFAULT_CLIENT_TIMEOUT;
//数据库数目,默认16
server.dbnum = CONFIG_DEFAULT_DBNUM;
//初始化命令表
populateCommandTable();
.....
}
②加载并解析配置文件;
入口函数为loadServerConfig,
void loadServerConfig(char *filename, char *options) ;
filename表示配置文件全路径名称,options表示命令行输入的配置参数,
例如我们通常以如下命令启动Redis服务器:
/home/user/redis/redis-server /home/user/redis/redis.conf -p 4000
加载完成后会调用loadServerConfigFromString函数解析配置,输入参数config即配置字符串,实现如下:
void loadServerConfigFromString(char *config) {
// 分割配置字符串多行,totlines记录行数 , 因为 配置时一行一行的
lines = sdssplitlen(config,strlen(config)," ",1,&totlines);
for (i = 0; i < totlines; i++) {
/* 跳过注释和空行*/
if (lines[i][0] == '#' || lines[i][0] == '�') continue;
/* 解析配置参数 */
argv = sdssplitargs(lines[i],&argc);
/* 赋值 */
if (!strcasecmp(argv[0],"bind") && argc >= 2) {
server.bindaddr[j] = zstrdup(argv[j+1]);
server.bindaddr_count = addresses;
} else if (!strcasecmp(argv[0],"unixsocketperm") && argc == 2) {
server.unixsocketperm = (mode_t)strtol(argv[1], NULL, 8);
}else if {
// 其他配置
}
}
③初始化服务端内部变量,其中就包括数据库;
客户端链表、数据库、全局变量和共享对象等;入口函数为initServer,函数逻辑相对简单;
void initServer(void) {
server.clients = listCreate(); //初始化客户端链表
//创建数据库字典
server.db = zmalloc(sizeof(redisDb)*server.dbnum);
/* Create the Redis databases, and initialize other internal state. */
for (j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType,NULL);
server.db[j].expires = dictCreate(&keyptrDictType,NULL);
server.db[j].expires_cursor = 0;
server.db[j].blocking_keys = dictCreate(&keylistDictType,NULL);
server.db[j].ready_keys = dictCreate(&objectKeyPointerValueDictType,NULL);
server.db[j].watched_keys = dictCreate(&keylistDictType,NULL);
server.db[j].id = j;
server.db[j].avg_ttl = 0;
server.db[j].defrag_later = listCreate();
listSetFreeMethod(server.db[j].defrag_later,(void (*)(void*))sdsfree);
}
....
}
数据库字典的dictType指向的是结构体dbDictType,其中定义了数据库字典键的散列函数、键比较函数,以及键与值的析构函数,定义如下:
/* Db->dict,数据库的键都是SDS类型, 数据库的值是robj对象. */
dictType dbDictType = {
dictSdsHash, /*键散列函数*/
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCompare, /* 比较函数*/
dictSdsDestructor, /*键析构函数 */
dictObjectDestructor /* 值析构函数为 */
};
对象robj的refcount字段存储当前对象的引用次数,意味着对象是可以共享的。要注意的是,只有当对象robj存储的是0~10000的整数时,对象robj才会被共享,且这些共享整数对象的引用计数初始化为INT_MAX,保证不会被释放。执行命令时Redis会返回一些字符串回复,这些字符串对象同样在服务器初始化时创建,且永远不会尝试释放这类对象。所有共享对象都存储在全局结构体变量shared。
void createSharedObjects(void) {
//创建命令回复字符串对象
shared.ok = createObject(OBJ_STRING,sdsnew("+OK "));
shared.err = createObject(OBJ_STRING,sdsnew("-ERR "));
// 创建0~10000整数对象
for (j = 0; j < OBJ_SHARED_INTEGERS; j++) {
shared.integers[j] =
makeObjectShared(createObject(OBJ_STRING,(void*)(long)j));
shared.integers[j]->encoding = OBJ_ENCODING_INT;
}
}
④创建事件循环eventLoop;
分配结构体所需内存,并初始化结构体各字段;epoll就是在此时创建的;
aeEventLoop *aeCreateEventLoop(int setsize) {
aeEventLoop *eventLoop;
int i;
if ((eventLoop = zmalloc(sizeof(*eventLoop))) == NULL) goto err;
eventLoop->events = zmalloc(sizeof(aeFileEvent)*setsize);
eventLoop->fired = zmalloc(sizeof(aeFiredEvent)*setsize);
....
if (aeApiCreate(eventLoop) == -1) goto err;
}
输入参数setsize理论上等于用户配置的最大客户端数目即可,但是为了确保安全,这里设置setsize等于最大客户端数目加128。函数aeApiCreate内部调用epoll_create创建epoll,并初始化结构体aeventLoop的字段apidata;
9.2.2 启动监听
⑤创建socket并启动监听;
指令port配置socket绑定端口号,指令bind配置socket绑定IP地址;注意指令bind可配置多个IP地址,中间用空格隔开;创建socket时只需要循环所有IP地址即可。
int listenToPort(int port, int *fds, int *count) {
for (j = 0; j < server.bindaddr_count || j == 0; j++) {
//创建socket并启动监听,文件描述符存储在fds数组作为返回参数
fds[*count] = anetTcp6Server(server.neterr,port,NULL,
server.tcp_backlog);
//设置socket非阻塞
anetNonBlock(NULL,fds[*count]);
(*count)++;
}
return C_OK;
}
输入参数port表示用户配置的端口号,server结构体的bindaddr_count字段存储用户配置的IP地址数目,bindaddr字段存储用户配置的所有IP地址。函数anetTcpServer实现了socket的创建、绑定,以及监听流程,这里不过多详述。参数fds与count可用作输出参数,fds数组存储创建的所有socket文件描述符,count存储socket数目。
注意:所有创建的socket都会设置为非阻塞模式,原因在于Redis使用了IO多路复用模式,其要求socket读写必须是非阻塞的,函数anetNonBlock通过系统调用fcntl设置socket非阻塞模式。
⑥创建文件事件与时间事件
socket的读写事件被抽象为文件事件,因为对于监听的socket还需要创建对应的文件事件。
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{ }
}
ipfd_count字段存储创建的监听socket数目,
ipfd数组存储创建的所有监听socket文件描述符,需要遍历所有的监听socket,为其创建对应的文件事件。
acceptTcpHandler 监听事件的处理函数,实现了socket连接请求的accept,以及客户端对象的创建。
定时任务被抽象为时间事件,且Redis只创建了一个时间事件,在服务端初始化时创建。此时间事件的处理函数为serverCron,初次创建时1毫秒后就会被触发。
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
exit(1);
}
⑦开启事件循环。
服务端的初始化工作,并在指定IP地址、端口监听客户端连接请求,同时创建了文件事件与时间事件;此时只需要开启事件循环等待事件发生即可。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
//开始事件循环
while (!eventLoop->stop) {
//事件处理主函数
aeProcessEvents(eventLoop, AE_ALL_EVENTS|
AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
这里需要重点关注函数beforesleep,它在每次事件循环开始,即Redis阻塞等待文件事件之前执行。函数beforesleep会执行一些不是很费时的操作,如:集群相关操作、过期键删除操作(这里可称为快速过期键删除)、向客户端返回命令回复等。这里简要介绍一下快速过期键删除操作。
void beforeSleep(struct aeEventLoop *eventLoop) {
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
}
Redis过期键删除有两种策略:
①访问数据库键时,校验该键是否过期,如果过期则删除;
②周期性删除过期键,beforeSleep函数与serverCron函数都会执行。
server结构体的active_expire_enabled字段表示是否开启周期性删除过期键策略,用户可通过set-active-expire指令配置;masterhost字段存储当前Redis服务器的master服务器的域名,如果为NULL说明当前服务器不是某个Redis服务器的slaver。注意到这里依然是调用函数activeExpireCycle执行过期键删除,只是参数传递的是ACTIVE_EXPIRE_CYCLE_FAST,表示快速过期键删除。
函数activeExpireCycle的实现,函数计算出timelimit,即函数最大执行时间,循环删除过期键时会校验函数执行时间是否超过此限制,超过则结束循环。显然快速过期键删除时只需要缩短timelimit即可,计算策略如下:
void activeExpireCycle(int type) {
static int timelimit_exit = 0; /* Time limit hit in previous call? */
static long long last_fast_cycle = 0; /* When last fast cycle ran. */
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
/* 上次activeExpireCycle函数是否已经执行完毕 */
if (!timelimit_exit &&
server.stat_expired_stale_perc < config_cycle_acceptable_stale)
return;
//当前时间距离上次执行快速过期键删除是否已经超过2000微秒
if (start < last_fast_cycle + (long long)config_cycle_fast_duration*2)
return;
last_fast_cycle = start;
// 快速过期键删除时,函数执行时间不超过1000微秒
....
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = config_cycle_fast_duration; /* in microseconds. */
}
执行快速过期键删除有很多限制,
当函数activeExpireCycle正在执行时直接返回;
当上次执行快速过期键删除的时间距离当前时间小于2000微秒时直接返回。
为什么可以通过变量timelimit_exit判断函数activeExpireCycle是否正在执行呢?
注意到变量timelimit_exit声明为static,即函数执行完毕不会释放变量空间。那么可以在函数activeExpireCycle入口赋值timelimit_exit为0,返回之前赋值timelimit_exit为1,由此便可通过变量timelimit_exit判断函数activeExpireCycle是否正在执行。变量last_fast_cycle声明为static也是同样的用意。同时可以看到当执行快速过期键删除时,设置函数activeExpireCycle的最大执行时间为1000微秒。
函数aeProcessEvents为事件处理主函数
它首先查找最近发生的时间事件,调用epoll_wait阻塞等待文件事件的发生并设置超时事件;
待epoll_wait返回时,处理触发的文件事件;
最后处理时间事件。
步骤6中已经创建了文件事件,为监听socket的读事件,事件处理函数为acceptTcpHandler,即当客户端发起socket连接请求时,服务端会执行函数acceptTcpHandler处理。
acceptTcpHandler函数主要做了3件事:
①接受(accept)客户端的连接请求;
②创建客户端对象,并初始化对象各字段;
③创建文件事件。步骤②与步骤③由函数createClient实现,输入参数fd为接受客户端连接请求后生成的socket文件描述符。
client *createClient(int fd) {
client *c = zmalloc(sizeof(client));
//设置socket为非阻塞模式
anetNonBlock(NULL,fd);
//设置TCP_NODELAY
anetEnableTcpNoDelay(NULL,fd);
//如果服务端配置了tcpkeepalive,则设置SO_KEEPALIVE ,长连接
if (server.tcpkeepalive)
anetKeepAlive(NULL,fd,server.tcpkeepalive);
if (aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c) == AE_ERR){
}
//初始化client结构体各字段
}
TCP长连接
为了使用I/O多路复用模式,此处同样需要设置socket为非阻塞模式。
TCP是基于字节流的可靠传输层协议,为了提升网络利用率,一般默认都会开启Nagle。当应用层调用write函数发送数据时,TCP并不一定会立刻将数据发送出去,根据Nagle算法,还必须满足一定条件才行。
Nagle是这样规定的:如果数据包长度大于一定门限时,则立即发送;如果数据包中含有FIN(表示断开TCP链接)字段,则立即发送;如果当前设置了TCP_NODELAY选项,则立即发送;如果以上所有条件都不满足,则默认需要等待200毫秒超时后才会发送。
Redis服务器向客户端返回命令回复时,希望TCP能立即将该回复发送给客户端,因此需要设TCP_NODELAY。思考下如果不设置会怎么样呢?从客户端分析,命令请求的响应时间会大大加长。TCP是可靠的传输层协议,但每次都需要经历"三次握手"与"四次挥手",为了提升效率,可以设置SO_KEEPALIVE,即TCP长连接,这样TCP传输层会定时发送心跳包确认该连接的可靠性。应用层也不再需要频繁地创建与释放TCP连接了。server结构体的tcpkeepalive字段表示是否启用TCP长连接,用户可通过参数tcp-keepalive配置。
接收到客户端连接请求之后,服务器需要创建文件事件等待客户端的命令请求,可以看到文件事件的处理函数为readQueryFromClient,当服务器接收到客户端的命令请求时,会执行此函数。
9.3 命令处理过程
过程分为3个阶段:解析命令请求、调用命令和返回结果给客户端。
9.3.1 命令解析
TCP是一种基于字节流的传输层通信协议,因此接收到的TCP数据不一定是一个完整的数据包,其有可能是多个数据包的组合,也有可能是某一个数据包的部分,这种现象被称为半包与粘包,如图9-3所示。
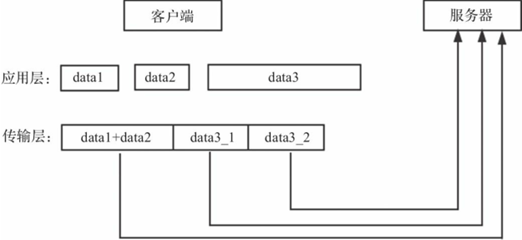
图9-3 TCP半包与粘包
客户端应用层分别发送3个数据包,data3、data2和data1,但是TCP传输层在真正发送数据时,将data3数据包分割为data3_1与data3_2,并且将data1与data2数据合并,此时服务器接收到的数据包就不是一个完整的数据包。
为了区分一个完整的数据包,通常有如下3种方法:
①数据包长度固定;
②通过特定的分隔符区分,比如HTTP协议就是通过换行符区分的;
③通过在数据包头部设置长度字段区分数据包长度,比如FastCGI协议。
Redis采用自定义协议格式实现不同命令请求的区分,例如当用户在redis-cli客户端键入下面的命令:SET redis-key value1
客户端会将该命令请求转换为以下协议格式,然后发送给服务器:
*3 $3 SET $9 redis-key $6 value1
其中,换行符 用于区分命令请求的若干参数,"*3"表示该命令请求有3个参 数,"$3""$9"和"$6"等表示该参数字符串长度。
需要注意的是,Redis还支持在telnet会话输入命令的方式,只是此时没有了请求协议中的"*"来声明参数的数量,因此必须使用空格来分隔各个参数,服务器在接收到数据之后,会将空格作为参数分隔符解析命令请求。这种方式的命令请求称为内联命令。
解析流程
Redis服务器接收到的命令请求首先存储在客户端对象的querybuf输入缓冲区,然后解析命令请求各个参数,并存储在客户端对象的argv(参数对象数组)和argc(参数数目)字段。参考9.2.2节可以知道解析客户端命令请求的入口函数为readQueryFromClient,会读取socket数据存储到客户端对象的输入缓冲区,并调用函数processInputBuffer解析命令请求。processInputBuffer函数主要逻辑如图9-4所示。
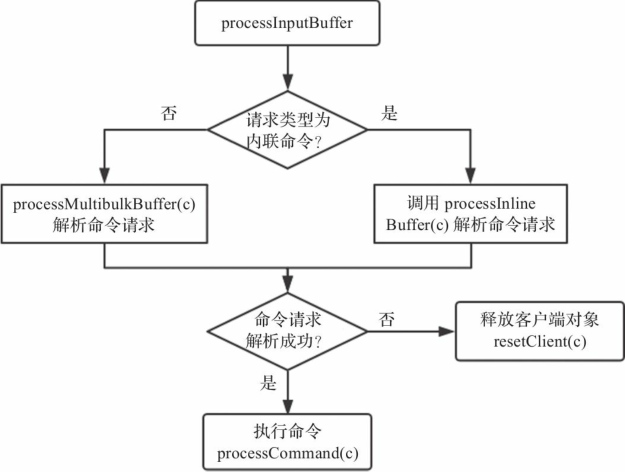
图9-4 命令解析流程图
假设客户端命令请求为"SET redis-key value1",
(gdb) p c->querybuf
$3 = (sds) 0x7ffff1b45505
"*3 $3 SET $9 redis-key $6 value1 "
解析该命令请求可以分为2个步骤:
①解析命令请求参数数目;
querybuf指向命令请求首地址,命令请求参数数目的协议格式为"*3 ",即首字符必须是"*",并且可以使用字符" "定位到行尾位置。解析后的参数数目暂存在客户端对象的multibulklen字段,表示等待解析的参数数目,变量pos记录已解析命令请求的长度。
// 定位到行尾
newline = strchr(c->querybuf+c->qb_pos,' ');
//解析命令请求参数数目,并存储在客户端对象的multibulklen字段
serverAssertWithInfo(c,NULL,c->querybuf[c->qb_pos] == '*');
ok = string2ll(c->querybuf+1+c->qb_pos,newline-(c->querybuf+1+c->qb_pos),&ll);
c->multibulklen = ll;
//记录已解析位置偏移量
c->qb_pos = (newline-c->querybuf)+2;
// 分配请求参数存储空间
c->argv = zmalloc(sizeof(robj*)*c->multibulklen);
②循环解析每个请求参数。
命令请求各参数的协议格式为"$3 SET ",即首字符必须是"$"。
解析当前参数之前需要解析出参数的字符串长度,可以使用字符" "定位到行尾位置;
注意,解析参数长度时,字符串开始位置为querybuf+pos+1;
字符串参数长度暂存在客户端对象的bulklen字段,同时更新已解析字符串长度pos。
// 定位到行尾
newline = strchr(c->querybuf+c->qb_pos,' ');
// 解析当前参数字符串长度,字符串首字符偏移量为pos
if (c->querybuf[c->qb_pos] != '$') {
return C_ERR;
}
ok = string2ll(c->querybuf+c->qb_pos+1,newline-(c->querybuf+c->qb_pos+1),&ll);
c->qb_pos = newline-c->querybuf+2;
c->bulklen = ll;
解析出参数字符串长度之后,可直接读取该长度的参数内容,并创建字符串对象;
同时需要更新待解析参数multibulklen。
// 解析参数
c->argv[c->argc++] =
createStringObject(c->querybuf+c->qb_pos,c->bulklen);
c->qb_pos += c->bulklen+2;
//待解析参数数目减1
c->multibulklen--;
当multibulklen值更新为0时,说明参数解析完成,结束循环。
读者可以思考一下,待解析参数数目、当前参数长度为什么都需要暂存在客户端结构体?使用函数局部变量行不行?答案是肯定不行,原因就在于上面提到的TCP半包与粘包现象,服务器可能只接收到部分命令请求,例如"*3 $3 SET $9 redis"。当函数processMultibulkBuffer执行完毕时,同样只会解析部分命令请求"*3 $3 SET $9 ",此时就需要记录该命令请求待解析的参数数目,以及待解析参数的长度;而剩余待解析的参数"redis"会继续缓存在客户端的输入缓冲区。
9.3.2 命令调用
解析完命令请求之后,会调用函数processCommand处理该命令请求,而处理命令请求之前还有很多校验逻辑,比如客户端是否已经完成认证,命令请求参数是否合法等。
若干校验规则。
校验①:如果是quit命令直接返回并关闭客户端。
if (!strcasecmp(c->argv[0]->ptr,"quit")) {
addReply(c,shared.ok);
c->flags |= CLIENT_CLOSE_AFTER_REPLY;
return C_ERR;
}
校验②:执行函数lookupCommand查找命令后,如果命令不存在返回错误。
// 命令从字典中查找
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
if (!c->cmd) {
sds args = sdsempty();
int i;
for (i=1; i < c->argc && sdslen(args) < 128; i++)
args = sdscatprintf(args, "`%.*s`, ", 128-(int)sdslen(args), (char*)c->argv[i]->ptr);
rejectCommandFormat(c,"unknown command `%s`, with args beginning with: %s",
(char*)c->argv[0]->ptr, args);
sdsfree(args);
return C_OK;
}
校验③:如果命令参数数目不合法,返回错误。
if ((c->cmd->arity > 0 && c->cmd->arity != c->argc) ||
(c->argc < -c->cmd->arity)) {
rejectCommandFormat(c,"wrong number of arguments for '%s' command",
c->cmd->name);
return C_OK;
}
命令结构体(redisCommand)的arity用于校验参数数目是否合法,当arity小于0时,表示命令参数数目大于等于arity的绝对值;当arity大于0时,表示命令参数数目必须为arity。注意命令请求中命令的名称本身也是一个参数。
校验④:如果配置文件中使用指令"requirepass password"设置了密码,且客户端没未认证通过,只能执行auth命令,auth命令格式为"AUTH password"。
//redis 6
if (auth_required) {
if (!(c->cmd->flags & CMD_NO_AUTH)) {
rejectCommand(c,shared.noautherr);
return C_OK;
}
}
校验⑤:如果配置文件中使用指令"maxmemory<bytes>"设置了最大内存限制,且当前内存使用量超过了该配置门限,服务器会拒绝执行带有"m"(CMD_DENYOOM)标识的命令,如SET命令、APPEND命令和LPUSH命令等。命令标识参见9.1.4节。
if (server.maxmemory && !server.lua_timedout) {
int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
if (server.current_client == NULL) return C_ERR;
int reject_cmd_on_oom = is_denyoom_command;
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand &&
c->cmd->proc != discardCommand) {
reject_cmd_on_oom = 1;
}
if (out_of_memory && reject_cmd_on_oom) {
rejectCommand(c, shared.oomerr);
return C_OK;
}
}
校验⑥:除了上面的5种校验,还有很多校验规则,比如集群相关校验、持久化相关校验、主从复制相关校验、发布订阅相关校验及事务操作等。这些校验规则会在相关章节会作详细介绍。
当所有校验规则都通过后,才会调用命令处理函数执行命令,代码如下:
call(c,CMD_CALL_FULL);
long long dirty;
ustime_t start, duration;
int client_old_flags = c->flags;
struct redisCommand *real_cmd = c->cmd;
/* Call the command. */
dirty = server.dirty;
updateCachedTime(0);
start = server.ustime;
c->cmd->proc(c);
duration = ustime()-start;
dirty = server.dirty-dirty;
//更新统计信息:当前命令执行时间与调用次数
real_cmd->microseconds += duration;
real_cmd->calls++;
//记录慢查询日志
if (flags & CMD_CALL_SLOWLOG && !(c->cmd->flags & CMD_SKIP_SLOWLOG)) {
slowlogPushEntryIfNeeded(c,c->argv,c->argc,duration);
}
执行命令完成后,如果有必要,还需要更新统计信息,记录慢查询日志,AOF持久化该命令请求,传播命令请求给所有的从服务器等。持久化与主从复制会在相关章节会作详细介绍,这里主要介绍慢查询日志的实现方式。代码如下:
/* Push a new entry into the slow log.
* This function will make sure to trim the slow log accordingly to the
* configured max length. */
void slowlogPushEntryIfNeeded(client *c, robj **argv, int argc, long long duration) {
if (server.slowlog_log_slower_than < 0) return; /* Slowlog disabled */
// 执行时间超过门限,记录该命令
if (duration >= server.slowlog_log_slower_than)
listAddNodeHead(server.slowlog,
slowlogCreateEntry(c,argv,argc,duration));
/* 慢查询日志最多记录条数为slowlog_max_len,超过需删除 */
while (listLength(server.slowlog) > server.slowlog_max_len)
listDelNode(server.slowlog,listLast(server.slowlog));
}
可以在配置文件中使用指令"slowlog-log-slower-than 10000"配置"执行时间超过多少毫秒"才会记录慢查询日志,指令"slowlog-max-len 128"配置慢查询日志最大数目,超过会删除最早的日志记录。可以看到慢查询日志记录在服务端结构体的slowlog字段(slowlog是list),即使存取速度非常快,也不会影响命令执行效率。用户可通过"SLOWLOG subcommand[argument]"命令查看服务器记录的慢查询日志。
9.3.3 返回结果
Redis服务器返回结果类型不同,协议格式不同,而客户端可以根据返回结果的第一个字符判断返回类型。Redis的返回结果可以分为5类。
- 状态回复,第一个字符是"+";
例如,SET命令执行完毕会向客户端返回"+OK "。
addReply(c, ok_reply ? ok_reply : shared.ok);
变量ok_reply通常为NULL,则返回的是共享变量shared.ok,在服务器启动时就完成了共享变量的初始化:
shared.ok = createObject(OBJ_STRING,sdsnew("+OK "));
2)错误回复,第一个字符是"-"。
例如,当客户端请求命令不存在时,会向客户端返回"-ERR unknown command'testcmd'"。
addReplyErrorFormat(c,"unknown command '%s'",(char*)c->argv[0]->ptr);
而函数addReplyErrorFormat内部实现会拼装错误回复字符串:
addReplyString(c,"-ERR ",5);
addReplyString(c,s,len);
addReplyString(c," ",2);
3)整数回复,第一个字符是":"。
例如,INCR命令执行完毕向客户端返回":100 "。
addReply(c,shared.colon);
addReply(c,new);
addReply(c,shared.crlf);
其中共享变量shared.colon与shared.crlf同样都是在服务器启动时就完成了初始化:
shared.colon = createObject(OBJ_STRING,sdsnew(":"));
shared.crlf = createObject(OBJ_STRING,sdsnew(" "));
4)批量回复,第一个字符是"$"。
例如,GET命令查找键向客户端返回结果"$5 hello ",其中$5表示返回字符串长度。
//计算返回对象obj长度,并拼接为字符串"$5 "
addReplyBulkLen(c,obj);
addReply(c,obj);
addReply(c,shared.crlf);
5)多条批量回复,第一个字符是"*"。
例如,LRANGE命令可能会返回多个值,格式为"*3 $6 value1 $6 value2 $6 value3 ",与命令请求协议格式相同,"*3"表示返回值数目,"$6"表示当前返回值字符串长度:
//拼接返回
addReplyArrayLen(c,rangelen);
while(rangelen--) {
//循环输出所有返回值
addReplyBulkCBuffer(c,qe->value,qe->sz);
}
/* Add a C buffer as bulk reply */
void addReplyBulkCBuffer(client *c, const void *p, size_t len) {
addReplyLongLongWithPrefix(c,len,'$');
addReplyProto(c,p,len);
addReply(c,shared.crlf);
}
5种类型的返回结果都是调用类似于addReply函数返回的,那么是这些方法将返回结果发送给客户端的吗?其实不是。回顾9.1.2节讲述的客户端结构体client,其中有两个关键字段reply和buf,分别表示输出链表与输出缓冲区,而函数addReply会直接或者间接地调用以下函数将返回结果暂时缓存在reply或者buf字段:
//添加字符串到输出缓冲区
int _addReplyToBuffer(client *c, const char *s, size_t len) {
//添加对象到输出链表
void addReplySds(client *c, sds s) {
那么思考一下,reply和buf字段都用于暂时缓存待发送给客户端的数据,数据优先缓存在哪个字段呢?两个字段能同时缓存数据吗?从_addReplyToBuffer函数可以得到答案:
int _addReplyToBuffer(client *c, const char *s, size_t len) {
/* If there already are entries in the reply list, we cannot
* add anything more to the static buffer. */
if (listLength(c->reply) > 0) return C_ERR;
}
调用函数_addReplyToBuffer缓存数据到输出缓冲区时,如果检测到reply字段有待返回给客户端的数据,则函数返回错误。而通常缓存数据时都会先尝试缓存到buf输出缓冲区,如果失败会再次尝试缓存到reply输出链表:
void addReply(client *c, robj *obj) {
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK)
_addReplyProtoToList(c,obj->ptr,sdslen(obj->ptr));
}
函数addReply在将待返回给客户端的数据暂时缓存在输出缓冲区或者输出链表的同时,会将当前客户端添加到服务端结构体的clients_pending_write链表,以便后续能快速查找出哪些客户端有数据需要发送。
listAddNodeHead(server.clients_pending_read,c);
发送给客户端
函数addReply只是将待返回给客户端的数据暂时缓存在输出缓冲区或者输出链表,那么什么时候将这些数据发送给客户端呢?读者是否还记得在介绍9.2.2节"步骤⑦开启事件循环"时,提到函数beforesleep在每次事件循环阻塞等待文件事件之前执行,主要执行一些不是很费时的操作,比如过期键删除操作,向客户端返回命令回复等。
函数beforesleep会遍历clients_pending_write链表中每一个客户端节点,并发送输出缓冲区或者输出链表中的数据。
//遍历clients_pending_write链表
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
listDelNode(server.clients_pending_write,ln);
/* 向客户端发送数据 ,Try to write buffers to the client socket. */
if (writeToClient(c,0) == C_ERR) continue;
}
看到这里我想大部分读者可能都会认为返回结果已经发送给客户端,命令请求也已经处理完成了。其实不然,读者可以思考这么一个问题,当返回结果数据量非常大时,是无法一次性将所有数据都发送给客户端的,即函数writeToClient执行之后,客户端输出缓冲区或者输出链表中可能还有部分数据未发送给客户端。这时候怎么办呢?很简单,只需要添加文件事件,监听当前客户端socket文件描述符的可写事件即可。
if (aeCreateFileEvent(server.el, c->fd, AE_WRITABLE,
sendReplyToClient, c) == AE_ERR){
}
可以看到该文件事件的事件处理函数为sendReplyToClient,即当客户端可写时,函数sendReplyToClient会发送剩余部分的数据给客户端。
至此,命令请求才算是真正处理完成了。
9.4 本章小结
基础结构体,如对象结构体robj、客户端结构体client、服务端结构体redisServer以及命令结构体redisCommand。
Redis服务器是典型的事件驱动程序,它将事件处理分为两大类:文件事件与时间事件。文件事件即socket的可读可写事件,时间事件即需要周期性执行的一些定时任务。Redis采用比较成熟的I/O多路复用模型(select/epoll等)处理文件事件,并对这些I/O多路复用模型进行简单封装。Redis服务器只维护了一个时间事件,该时间事件处理函数为serverCron,执行了所有需要周期性执行的一些定时任务。事件是理解Redis的基石,希望读者能认真学习。
最后本章介绍了服务器处理客户端命令请求的整个流程,包括服务器启动监听、接收命令请求并解析、执行命令请求和返回命令回复等,为读者学习后续章节打下基础。