这是一个简单的基于问词匹配的自动问答,获取与用户问句Q1最匹配的知识库中的问句Q2,Q2的答案就是Q1的答案。
首先需要准备一个知识库,在这个例子中,知识库以一个txt的形式存在,且主题是减肥

1. 读取知识库
共18个与减肥相关的话题

2. 读取词向量(但是词向量在此处感觉没什么用的样子)
3. 用户输入问句 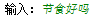
4. 对用户输入的问句断句,并对所断到的词判断词性

5. 遍历知识库中的每一个问句,得到其与用户问句的相关性,挑选相关性最大的
6. 相关性的计算方法:参数:用户问句a的断句后的list(见4中的图),用户问句b及其分词,词性的权重

得到a、b的交集的词,求和这些词对应的词性权重,得到sim_weight
求和a中的词的词性权重,得到total_weight
return sim_weight / total_weight if total_weight > 0 else 0
7. 挑选6中值最大的b的答案返回,6中的值<0.1,则返回
'抱歉,我没有理解您的意思。请您询问有关减肥的话题。'