运行环境:linux cuda cudnn
代码: 执行卷积操作 代码参考:https://gist.github.com/odashi/1c20ba90388cf02330e1b95963d78039
#include <iomanip>
#include <iostream>
#include <cstdlib>
#include <vector>
#include <stdio.h>
#include <cuda.h>
#include <cudnn_v7.h>
#define CUDA_CALL(f) {
cudaError_t err = (f);
if (err != cudaSuccess) {
std::cout
<< " Error occurred: " << err << std::endl;
std::exit(1);
}
}
#define CUDNN_CALL(f) {
cudnnStatus_t err = (f);
if (err != CUDNN_STATUS_SUCCESS) {
std::cout
<< " Error occurred: " << err << std::endl;
std::exit(1);
}
}
__global__ void dev_const(float *px, float k) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
px[tid] = k;
}
__global__ void dev_iota(float *px) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
px[tid] = tid;
}
void print(const float *data, int n, int c, int h, int w) {
std::vector<float> buffer(1 << 20);
CUDA_CALL(cudaMemcpy(
buffer.data(), data,
n * c * h * w * sizeof(float),
cudaMemcpyDeviceToHost));
int a = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < c; ++j) {
std::cout << "n=" << i << ", c=" << j << ":" << std::endl;
for (int k = 0; k < h; ++k) {
for (int l = 0; l < w; ++l) {
std::cout << std::setw(4) << std::right << buffer[a];
++a;
}
std::cout << std::endl;
}
}
}
std::cout << std::endl;
}
int main() {
cudnnHandle_t cudnn;
CUDNN_CALL(cudnnCreate(&cudnn));
// input
const int in_n = 1;
const int in_c = 1;
const int in_h = 5;
const int in_w = 5;
std::cout << "in_n: " << in_n << std::endl;
std::cout << "in_c: " << in_c << std::endl;
std::cout << "in_h: " << in_h << std::endl;
std::cout << "in_w: " << in_w << std::endl;
std::cout << std::endl;
cudnnTensorDescriptor_t in_desc;
CUDNN_CALL(cudnnCreateTensorDescriptor(&in_desc));
CUDNN_CALL(cudnnSetTensor4dDescriptor(
in_desc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT,
in_n, in_c, in_h, in_w));
float *in_data;
CUDA_CALL(cudaMalloc(
&in_data, in_n * in_c * in_h * in_w * sizeof(float)));
// filter
const int filt_k = 1;
const int filt_c = 1;
const int filt_h = 2;
const int filt_w = 2;
std::cout << "filt_k: " << filt_k << std::endl;
std::cout << "filt_c: " << filt_c << std::endl;
std::cout << "filt_h: " << filt_h << std::endl;
std::cout << "filt_w: " << filt_w << std::endl;
std::cout << std::endl;
cudnnFilterDescriptor_t filt_desc;
CUDNN_CALL(cudnnCreateFilterDescriptor(&filt_desc));
CUDNN_CALL(cudnnSetFilter4dDescriptor(
filt_desc, CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW,
filt_k, filt_c, filt_h, filt_w));
float *filt_data;
CUDA_CALL(cudaMalloc(
&filt_data, filt_k * filt_c * filt_h * filt_w * sizeof(float)));
// convolution
const int pad_h = 1;
const int pad_w = 1;
const int str_h = 1;
const int str_w = 1;
const int dil_h = 1;
const int dil_w = 1;
std::cout << "pad_h: " << pad_h << std::endl;
std::cout << "pad_w: " << pad_w << std::endl;
std::cout << "str_h: " << str_h << std::endl;
std::cout << "str_w: " << str_w << std::endl;
std::cout << "dil_h: " << dil_h << std::endl;
std::cout << "dil_w: " << dil_w << std::endl;
std::cout << std::endl;
cudnnConvolutionDescriptor_t conv_desc;
CUDNN_CALL(cudnnCreateConvolutionDescriptor(&conv_desc));
CUDNN_CALL(cudnnSetConvolution2dDescriptor(
conv_desc,
pad_h, pad_w, str_h, str_w, dil_h, dil_w,
CUDNN_CONVOLUTION, CUDNN_DATA_FLOAT));
// output
int out_n;
int out_c;
int out_h;
int out_w;
CUDNN_CALL(cudnnGetConvolution2dForwardOutputDim(
conv_desc, in_desc, filt_desc,
&out_n, &out_c, &out_h, &out_w));
std::cout << "out_n: " << out_n << std::endl;
std::cout << "out_c: " << out_c << std::endl;
std::cout << "out_h: " << out_h << std::endl;
std::cout << "out_w: " << out_w << std::endl;
std::cout << std::endl;
cudnnTensorDescriptor_t out_desc;
CUDNN_CALL(cudnnCreateTensorDescriptor(&out_desc));
CUDNN_CALL(cudnnSetTensor4dDescriptor(
out_desc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT,
out_n, out_c, out_h, out_w));
float *out_data;
CUDA_CALL(cudaMalloc(
&out_data, out_n * out_c * out_h * out_w * sizeof(float)));
// algorithm
cudnnConvolutionFwdAlgo_t algo;
CUDNN_CALL(cudnnGetConvolutionForwardAlgorithm(
cudnn,
in_desc, filt_desc, conv_desc, out_desc,
CUDNN_CONVOLUTION_FWD_PREFER_FASTEST, 0, &algo));
std::cout << "Convolution algorithm: " << algo << std::endl;
std::cout << std::endl;
// workspace
size_t ws_size;
CUDNN_CALL(cudnnGetConvolutionForwardWorkspaceSize(
cudnn, in_desc, filt_desc, conv_desc, out_desc, algo, &ws_size));
float *ws_data;
CUDA_CALL(cudaMalloc(&ws_data, ws_size));
std::cout << "Workspace size: " << ws_size << std::endl;
std::cout << std::endl;
// perform
float alpha = 1.f;
float beta = 0.f;
dev_iota<<<in_w * in_h, in_n * in_c>>>(in_data);
dev_const<<<filt_w * filt_h, filt_k * filt_c>>>(filt_data, 1.f);
CUDNN_CALL(cudnnConvolutionForward(
cudnn,
&alpha, in_desc, in_data, filt_desc, filt_data,
conv_desc, algo, ws_data, ws_size,
&beta, out_desc, out_data));
// results
std::cout << "in_data:" << std::endl;
print(in_data, in_n, in_c, in_h, in_w);
std::cout << "filt_data:" << std::endl;
print(filt_data, filt_k, filt_c, filt_h, filt_w);
std::cout << "out_data:" << std::endl;
print(out_data, out_n, out_c, out_h, out_w);
// finalizing
CUDA_CALL(cudaFree(ws_data));
CUDA_CALL(cudaFree(out_data));
CUDNN_CALL(cudnnDestroyTensorDescriptor(out_desc));
CUDNN_CALL(cudnnDestroyConvolutionDescriptor(conv_desc));
CUDA_CALL(cudaFree(filt_data));
CUDNN_CALL(cudnnDestroyFilterDescriptor(filt_desc));
CUDA_CALL(cudaFree(in_data));
CUDNN_CALL(cudnnDestroyTensorDescriptor(in_desc));
CUDNN_CALL(cudnnDestroy(cudnn));
return 0;
}
运行:
nvcc conv_cudnn.cu -lcudnn ./a.out
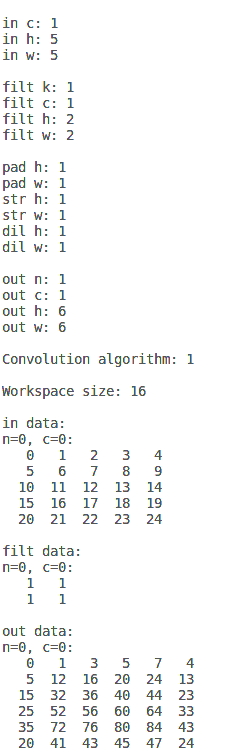
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">