模型的校准
·[530]|1000天行动计划
读书笔记/热点追踪/论文研读/教程手册
上节我们初步搭建好了模型的框架,即初步形成了一个水质模型,但是实际的过程中,可以说建模刚刚开始,前面几节的操作,实质上并没有什么难度,基本是谁都能做,但是调试就展示实力的时候了,整个建模花费的时间大概30%在处理分析数据上,40%在校准上,校准是建模过程中最有挑战性的环节,可以说是否真正的掌握某一个水质模型,就看校准的功力了。
校准是啥?
校准这词在生活中用的并不多,以前还好,在机械表的时代,可能过几周就需要重新调时拨动指针和电视上的时间匹配(彷佛暴露了年龄),校准时间,这个跟校准稍微沾点边了,当你发现你的表老不准的时候,可能需要拿去修表店去调试了,修表师傅会拿出各种工具来进行调试,这个调试的过程就跟模型的校准极其相似了。
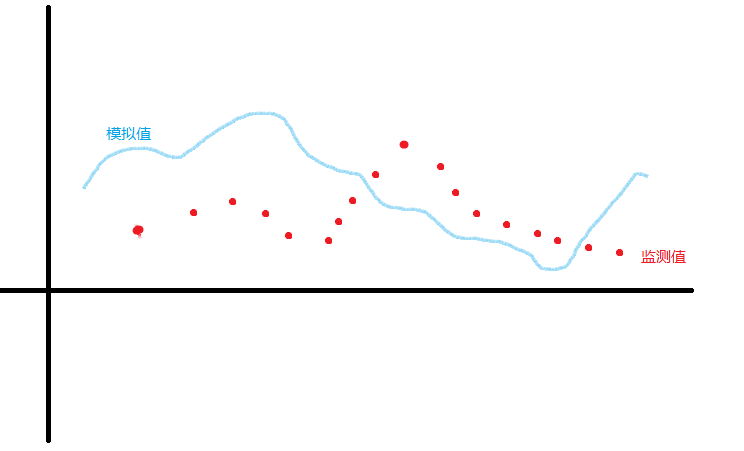
所谓的校准,就是通过各种方法来使得模型的模拟值匹配真实值(监测值),对照上面的机械表的例子很容易理解。
那么,我们的目的极为明确清晰,但是实现其却并不容易。之所以非常的困难原因有多方面,比如这个世界本身就是不确定的,你妄想通过数字世界来镜像现实,是不可能的。开个玩笑,不过确实是这样的,因为我们是想模拟这个水体,但是仅仅凭有限的几个离散数据,是不可能还原现实的,同时,这个世界也没法测量,你监测的手段是否准确反映真实都是个问题,所以我们只能说尽可能去模拟、匹配,而不能完全的吻合。
听了好像非常的打击人,不过我们放低要求,我们要求能把握个七七八八还是有的说的。具体说来,我们重新确认下我们的目标,就是使得模型的模拟值和监测值尽可能匹配起来。那么我们第一步要问个为什么?就是两者的差距是怎么引起的,或者说为什么两者会不一样。
会不会是要匹配的监测的数据有问题,其明明就应该是吻合模拟值的,一定是监测的错了,模拟的是对的。找打啊,虽然这种情况是有可能的,但是这个想法只有在校准后期才会去分析(校准过程中确实要怀疑一切,因为我真的有遇到过监测数据是错的情况,但是只是少数情况,我们只能先假设监测数据是没有问题的,这个我后面再说。)
两者不同的原因主要是因为参数的原因,换句话说是没有进行模型的参数本地化。之前的文章中有提到过,我们建模一般采用的是应用成熟的模型,这些模型都是在某些局部的湖体成功应用后抽象出来的通用模型,那么其中非常多的参数值都是对于那个湖体是适用的。现在,你拿过来用于新的水体,你给定了本地的气象条件、边界条件,当然参数也需要去适应本地的。模型校准可以说是最关键的过程环节,简单说就是使得模型能够真正的表达实际的水体,之前我们一直说模型是实际水体的抽象,准确的说只有校准的模型才能说是反映了所模拟的水体。
最近国内新建高铁,在期待开通的时候都听过所谓的列车调试,有异曲同工之处,我们新建的列车的是工厂环境下的,那么要上路的时候,就需要让其状态与本地环境贴合。
火车在行驶的过程中,正常速度与加速度之间的误差也是需要去考虑的,因为不同的地域性环境与火车的实际行驶也有着很大的关系,而针对于不同的地理环境,也需要对其进行针对性的测试性调速,这一点也是非常重要的。在调速的过程中,将每一个可能出现的情况都记录到案,那么在日后修正的过程中进行不断地改善,那么通过这样的方法的话,对于日后规避性一定的风险具有非常重要的意义。
新出厂的列车需要适应当地的环境,通过试运行,观察列车的状况,调整列车的运行参数,运行速度、刹车状况,轨道等才能更加稳定的运行。模型也类似的,也需要适配当地的实际情况,这里需要调整模型的参数了。
参数是啥?
前面的文章中我们有简单介绍过水质模型,实际就是描述了各种物理、化学规律的各种数学方程。而这些方程中除了自变量之外和监测变量之外的,都是参数。比如,污染物的降解速率,温度影响因子等等。我们以一阶降解为例:
$$ y = ae^{-bx} $$
y代表污染物浓度,x代表时间,也就是能够表达物质随时间的变化情况。我们知道这里的a实际上应该是初始条件(x=0时,y=a),而b是降解系数,这个b就是一个参数。
在a=3时,b=0.1其的图像如下图所示:
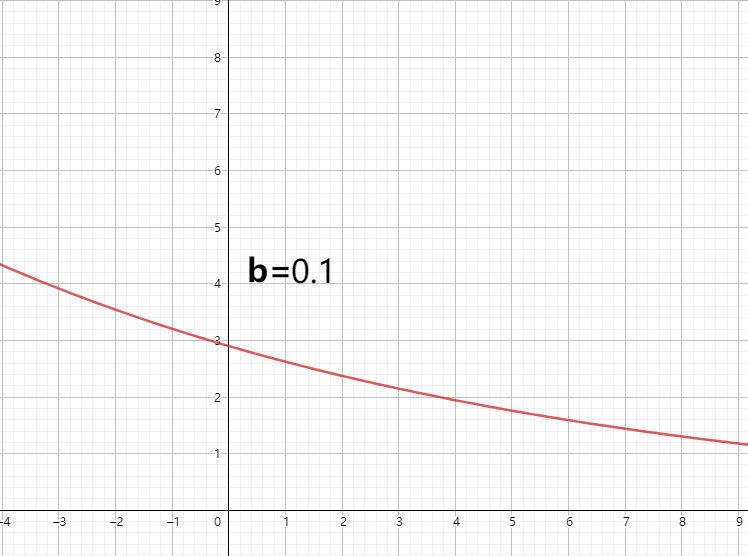
上述就是一个简单的物质随时间降解过程图,给定初始条件和降解系数,其浓度随时间就会这样的变化。
如何调参?
那么,我们明白参数之后,就回到我们的目标,调整参数使得模拟值和监测值吻合。同样以上述降解方程为例,对于简单的公式方程,我们先获取到参数响应特征。
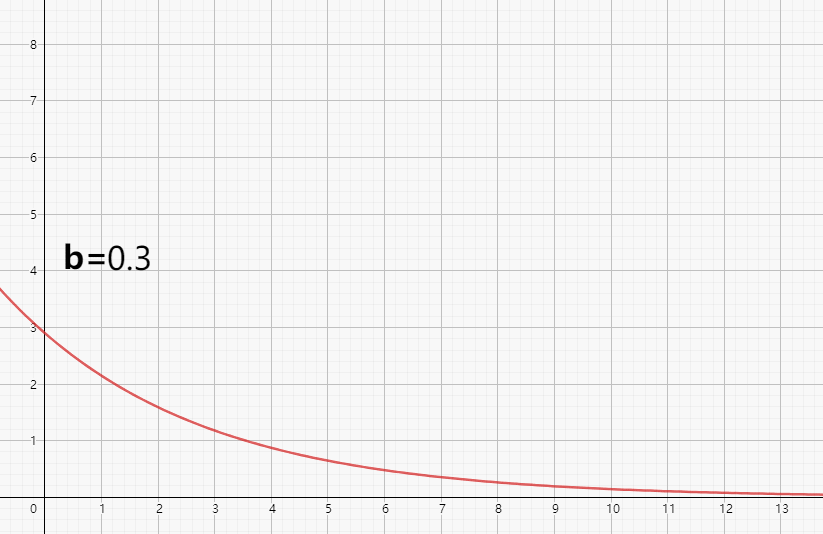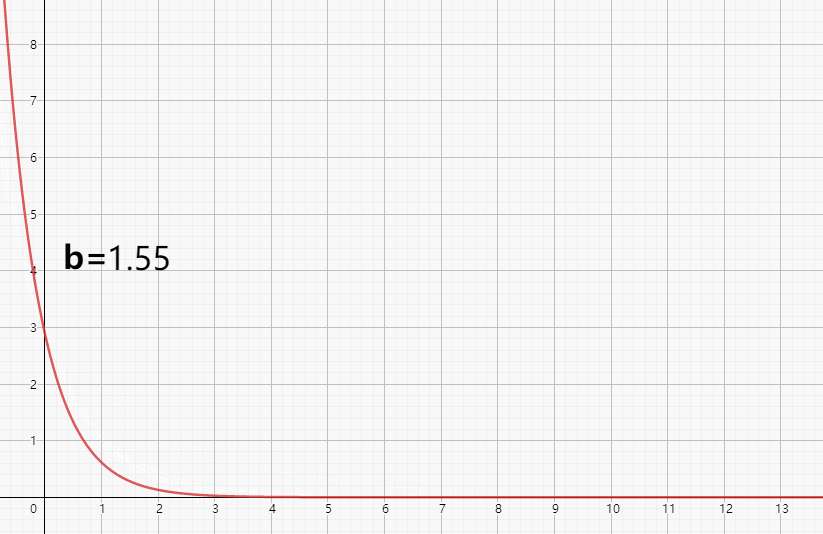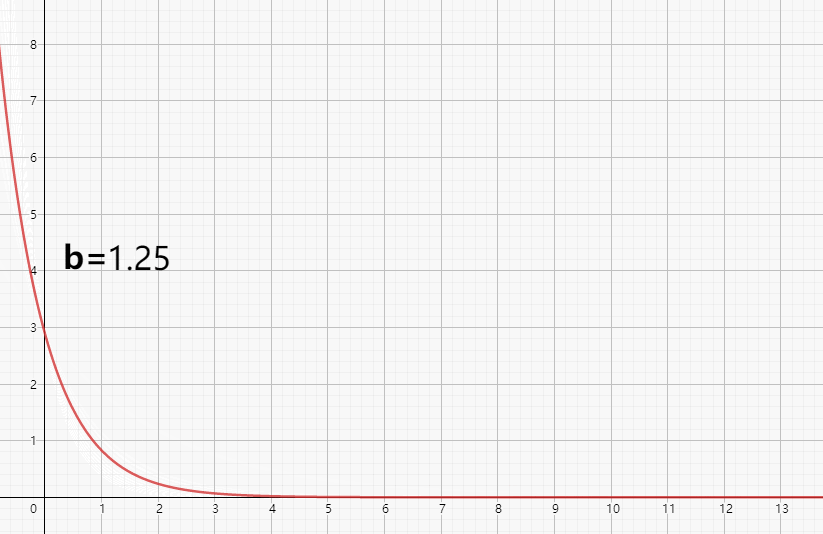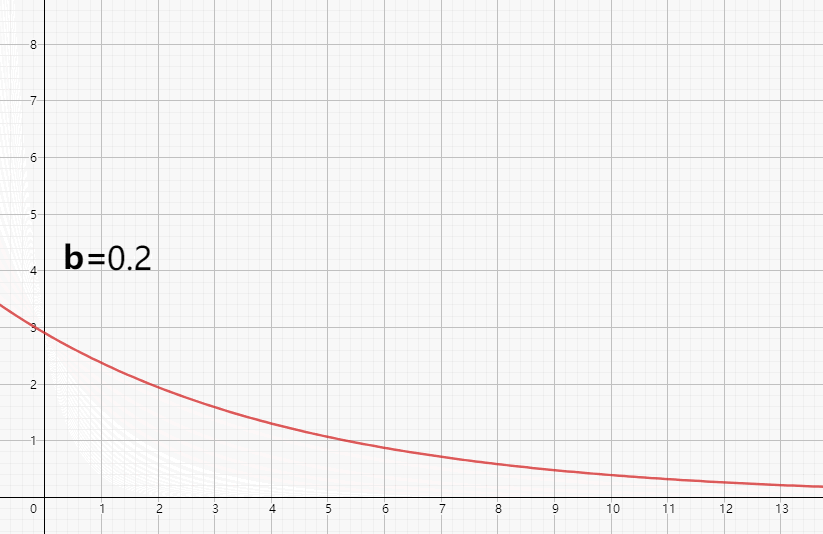
如上图所示,我们看到了整个随着b值的变化,整个曲线的变化情况。基本的规律,就是b值越大,物质浓度随时间衰减越快。
那么,对于实际情况来说,我们一般会根据经验有b值的范围,特定情况我们可能获取到经验值,我们可以在这个范围内给一个。有一个如下的监测数据(图中以点表示),给定了一直参数值b,其的曲线如下:
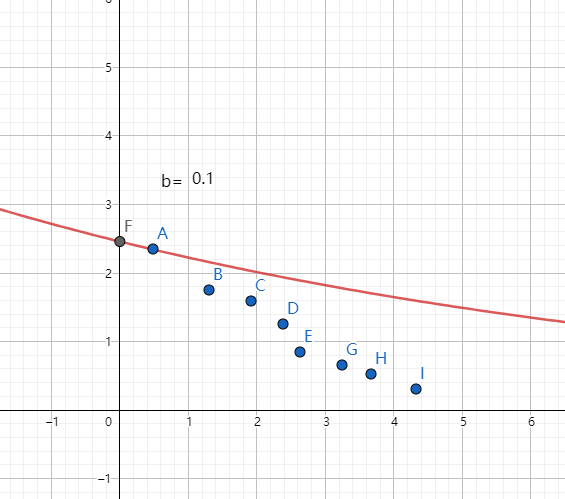
然后我们通过根据已知的曲线随b的变化,经过调整b的参数,获取到校准之后的结果,如下图。
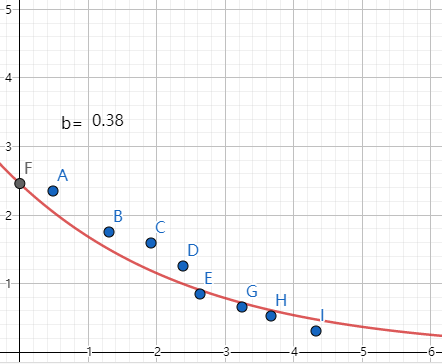
这时候,我们经过多次调试之后,发现b=0.38时,模拟值和监测值基本吻合一致,基本的调参完毕,这里引出一个新的问题,就是怎么样评判一个模型是校准完成的呢?或者说,校准到什么程度算是结束,这个后面再说。
上述这个调参的案例仅仅是一个非常简单的案例,实际当中的水质模型,参数数量可能多达十个或者上百个,这么多参数相互关联在一起使得参数的响应十分的复杂,特别是非线性存在其中,让你根本无法参透这里面的奥秘。所谓的非线性就是参数的响应并不明确,在某个区间,其可能一种表现,另外一个区间则是另外的表现。也就是调需要较多的经验的原因,当然所谓的经验不仅仅是你自己的,你也可以通过查阅文献获取别人的经验,从而获得调参的区间或者参数的响应。
但是虽然上面举的例子调参过程非常的简单,但是是调参的基本步骤。基于经验+实践,你可以把调参过程想象为火箭发射之后的,对火箭的控制,虽然有牛顿第二定律和相对论作为基础支撑(如上述的经验),但是实际火箭调整轨道还要根据火箭的实际情况进行动态调整,调整参数后观察其的反应,然后不断反复的测试,最后获取到自己想要的效果。
那么对于无法获取经验的那些参数,或者一些参数表现和经验所述不同,这时候经验失效了,只能自己探路了,也就是你自己要来建立经验,那么也就是你需要去调整这个参数,来获取结果的响应,从而自己来获取到参数的响应。
当然,若是少数的参数,我们多试试总会获取到参数的相关的效果,但是如果复杂的模型,参数往往非常的多,我们总不能一个个调整到天荒地老吧。这时候很明显需要抓住主要矛盾,也就是有一些参数,结果响应非常的强,有一些参数似乎调整半天,结果没有变化,那我肯定先去管那些反应强烈的,这样才能让模拟值快速达到我想要的效果,当然上述的方法的官方术语叫敏感性分析,具体的做法就比较多样了,蒙特卡洛、贝叶斯等等,具体就不多阐述了,大家可针对具体的模型去搜索。思路基本都是,变动一个参数,固定其他参数,看结果的响应,最后找出敏感的参数。
最后,有关水质模型的校准,由于水质模型建立在水动力模型基础上,所以我们一般是先调整水动力/水文参数,水动力中包括了水量平衡和水温的校准,也就是使得这些变量和观测值一致,然后校准水质参数,水质参数包括底泥中的水质参数、水中的水质参数等等。
校准评估
上面还留了一个问题,校准到什么程度才算结束,即校准的判断标准是什么?实际上业内对于水质模型的校准判断并没有统一的标准,因为模型的校准存在诸多不确定性。谈谈个人的看法,水质模型的构建,最终是为应用服务的,这个是我们的终极目标,那么从这个角度来说,校准是为了更好的应用,校准好的模型意味着能够代表实际水体,也就是在各种条件下的校准的模型反应与实际水体趋于一致,这个是我们的想要的结果。但是这个如何去判断,不幸的是,在水质模型领域内,目前没有充分必要条件,只有一些必要条件,比如观测值与模拟值吻合较好。
问题又来了,什么叫吻合好。这个吻合也非常的难解释,是不是模拟值的线完全的穿越点就是吻合好呢?不一定,因为存在过拟合的情况,过拟合是无法通过验证环节的,也就是模型与这套数据吻合的非常好,但是另外一套数据,就差的离谱了,这时候你的模型就不是代表实际水体,可以说是没有校准好的。所以校准的评估是没有绝对的标准的,没有评判标准也不行,因为没有标准你这个事情就没法做,所以也还是要一些基本的参考。
目前,水质模型校准的评判有两种方法参考,统计分析和图像分析。统计分析,就是计算模拟值和监测值的各种统计误差,误差小就认为好。但是误差多小呢?这个在水文模型、水动力模型上是可以的定一个参考的值的,但是水质模型过于复杂,不太好确定,误差过小的模型经常会出现过拟合的情况,导致模型无效。
图像分析,也就是利用时间序列图和空间分布图对模型时间和空间上的表现进行定性的分析,比如前面的时间序列图,模拟值和观测值在时间的上的趋势变化一致,夏天高冬天低等特征。空间分布图,即污染物浓度在空间上的变化,上游高下游低等,湖心高,岸边低等。
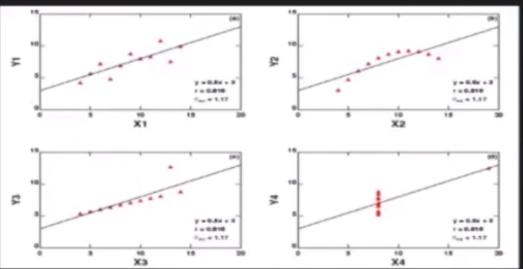
同时,图像分析还能检验统计方法,如下图所示(李博:水质模型入门课),四个图的相对误差是一样的,但是图形却完全不同。
多说几句,上面实际上用的是手动校准的工作,现在很多也有尝试自动校准的,所谓的自动校准实际上就是自动调参,在有明确的判断标准,可以利用机器进行大量的计算,从中获得参数的知识,实现自动校准。水质模型为啥没有自动校准,就是因为校准的判断不清楚,无法使用其他模型上采用的自动校准工作。但是自动校准的思路是辅助人工进行校准的,毕竟机器不需要休息。
校准只是调参吗?
上面说了非常多有关参数的内容,说明调参是校准中比较重要、难点的部分,但是不是说调参就是校准的全部了。因为模拟值和实测值不吻合,不一定是模拟值的问题,也可能是观测值的问题,有可能是监测的误差,或者数据输入的错误,使得两者不吻合。还有模型的机理是不是缺失,有些过程没有表达,那么无论你怎么调参都无法校准。
也就是说,我们调参是有潜在假设的,就是模型机理没有问题,数据正确等等,但是这些只是假设,必要的时候也要进行怀疑,实际工作中也有时候就是无法校准,去核实就是数据错了,模型可以用来检验数据,哈哈。也就是说,我们在调参之前要确保其他假设无误,或者直接调参也可以,但是心中也有保留一丝的怀疑。
小结
校准是玩水质模型的必经之路,也是最好玩的一部分,可以说模型的技术都在校准之中了,所以这部分也非常的长,写起来也非常的累,至于如何提高模型技术,因为我也是新手,给不出大家的更好的建议,多盘它就对了。
由于教程系列文章需要花费很多时间,难免出错,而这里不能进行后续完善,所以推荐大家关注我的博客,获取最新的修正和补充。 公众号的社群同步开启,感兴趣可在公众号对话框回复“社群”,获取群号和加入方式。

微信公众号 | 水环境编Cheng长 网 站 | comieswater.com

2020-1-31
folder=/微信公众号/水环境编Cheng长/
参考文献: [1] 李博,水质模型入门,环in学院.