==========================================================================================================
写在前面:
这两天比较头疼这个验证码识别功能,本来查看相关的资料时候,tesseract已经能够完成基本的识别,识别效果差,加上还有其他其他exe,后来
在网上看到Tess4J的文字,然后就想着该用这种依赖jar包融合的方式进行识别,下来列举下自己在OCR识别图片过程中遇到的坑和解决方案。
==========================================================================================================
参考链接地址:https://blog.csdn.net/zai_xia/article/details/80003778
首先,列举下进行OCR识别的步骤。
(1)下载图片或者截图地址到本地。
(2)对图片进行处理(如降噪,灰度等),根据识别图片的特点。
(3)使用Tess4J进行图片处理,获取识别结果,返回识别文本。
今天,着重讲下第三部分,上一篇实战里已经说了,可以使用Tesseract-ocr方式进行识别,但是由于需要下载软件,安装配置等,个人觉得移植性不高,所以使用Tess4J进行处理。
第一步:下载Tess4J的压缩包等。官网:http://tess4j.sourceforge.net/codesample.html
解压,其中的目录结构如下:
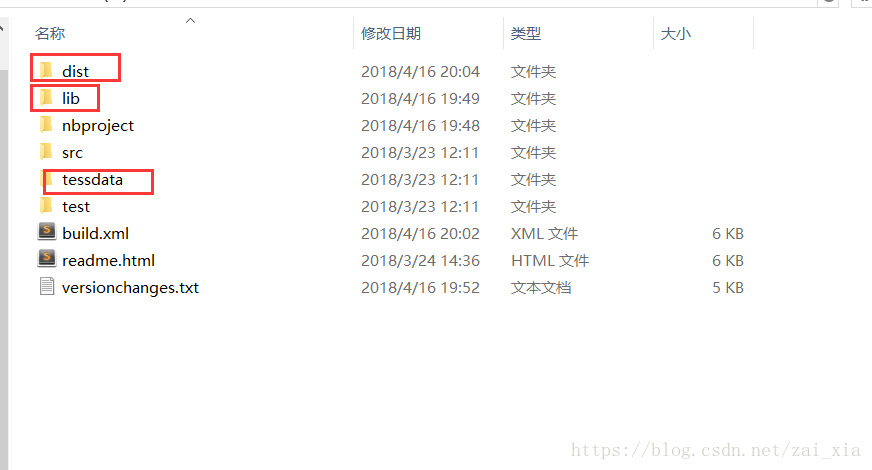
需要用到其中圈起来的三个文件夹中的东西。lib文件夹下放的是需要用到的Jar包,tessdata下放的是语言库,默认的有英语库,中文库需要另外下载,下载地址:https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata。
新建一个Java项目,将lib文件夹和tessdata文件夹复制到项目的根目录下,找到dist文件夹下的tess4j.jar(名字可能有版本号),将该文件也复制到项目根目录下的lib文件夹下。
项目的的目录如下:
lib中的文件如下(tess4J.jar也在该目录下):
再在eclipse中打开项目,在项目中导入lib文件夹中所有的jar包(Build path --> configure build path),导入后的结果如下:
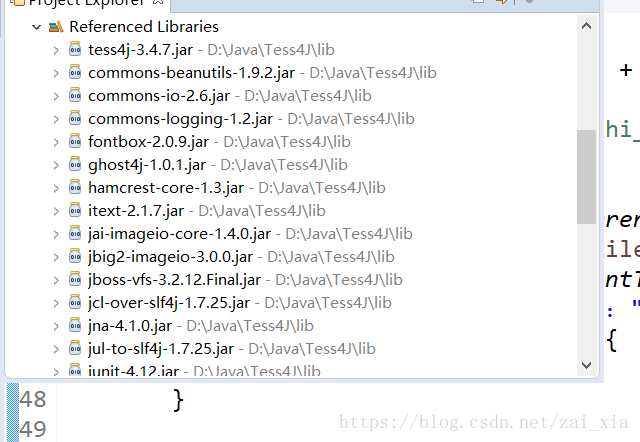
这样前期准备工作就完成了,下面就剩下代码了。Tess4J的代码比较简洁,如下:
Tess4JTest.java package ocr; import net.sourceforge.tess4j.ITesseract; import net.sourceforge.tess4j.Tesseract; import net.sourceforge.tess4j.TesseractException; import net.sourceforge.tess4j.util.LoadLibs; import java.io.File; import java.io.IOException; /** * Tess4J测试类 */ public class Tess4JTest { public static void main(String[] args){ String path = "D://Java//Tess4J"; //我的项目存放路径 File file = new File(path + "//photo.jpg"); ITesseract instance = new Tesseract(); /** * 获取项目根路径,例如: D:IDEAWorkSpace ess4J */ File directory = new File(path); String courseFile = null; try { courseFile = directory.getCanonicalPath(); } catch (IOException e) { e.printStackTrace(); } //设置训练库的位置 instance.setDatapath(courseFile + "//tessdata"); instance.setLanguage("eng");//chi_sim :简体中文, eng 根据需求选择语言库 String result = null; try { long startTime = System.currentTimeMillis(); result = instance.doOCR(file); long endTime = System.currentTimeMillis(); System.out.println("Time is:" + (endTime - startTime) + " 毫秒"); } catch (TesseractException e) { e.printStackTrace(); } System.out.println("result: "); System.out.println(result); } }
通过以上文字介绍的方式,本地化加入Lib包后,能够成功的识别文本,并输出结果。
但是我想把工程文件放到jenkins上去,所以不想额外依赖lib包,希望能够通过其他的方式比如maven的lib方式,加载相关内容。
也查了网络上相关的资料,不知道能不能成功呢。
相关参考链接:https://kefeng.wang/2017/04/22/tess4j/
第一:在maven添加依赖。
<dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>3.5.3</version> </dependency>
第二,在代码中添加识别文件的代码:
/** * @Title: executeTess4J * @Description: 执行图片识别 * @param imgUrl * @param resUrl * @return void */ public static String executeTess4J(String imgUrl) { String ocrResult = ""; try { File imgDir = new File(imgUrl); File tess = LoadLibs.extractTessResources("tessdata"); ITesseract instance = new Tesseract(); instance.setLanguage("eng"); // instance.setLanguage("chi_sim");
// 设置训练库的位置
logger.info("-----TESSDATA_FILE_PATH:" + tess.getParent() + "-----");
instance.setDatapath(tess.getParent());
long startTime = System.currentTimeMillis();
ocrResult = instance.doOCR(imgDir);
logger.info("-----识别出的文本内容:" + ocrResult + "-----");
long endTime = System.currentTimeMillis();
logger.info("Time is:" + (endTime - startTime) + " 毫秒");
} catch (TesseractException e) {
e.printStackTrace();
}
return ocrResult;
}
然后浪费我时间比较多的是,在执行
ocrResult = instance.doOCR(imgDir);
的时候,总是会报错,报错内容如下:
报错如下: Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language ‘eng‘ Tesseract couldn‘t load any languages! Could not initialize tesseract.
然后查找该问题的解决方案中,发现可以设置环境变量
TESSDATA_PREFIX
来解决,可是搞了半天没搞成功。
最后发现ITesseract类中,有个
instance.setDatapath(tess.getParent());
的方法,个人觉得比较实用,就是自己设置tessdata路径,然后让程序读取该路径下的信息。。
入了一个坑就是,使用maven下载的是4.1.1最新的版本,然后调试程序中发现始终打不开eng包,然后定位到相关目录下才发现,可能下载的maven包本身有问题,
然后在使用手动加入lib解决后,现在使用3.5.3版本完毕解决该问题。
但是个人感觉,在OCR过程中还是踩过很多坑,总结下来帮助自己回忆一些问题。
目前的方案虽然不是最完美的,但是能解决问题,一步一步来。